python网络爬虫(一) 2018-02-10
python版本:python 3.7.0b1
IDE:PyCharm 2016.3.2
涉及模块:requests & builtwith
模块安装方法:Win+R 进入cmd, 进入文件夹Scripts
命令:pip install requests / pip install requests(如不能正确安装,请留言或自行百度解决)
话不多说,先上代码:
1 #coding : utf-8 2 import requests 3 import builtwith #引入所需python库 4 print("开始爬取") 5 url = "https://www.wenjiwu.com/doc/uqzlni.html" #爬取对象网址 6 r = requests.get(url) #requests模块get方法 7 print (r.status_code) #xxx.status_code方法,返回值若为200,则爬取成功 8 print (r.text) #xxx.text方法,得到URL对应HTML源码 9 print (builtwith.parse(url)) #builtwith模块将URL作为参数,返回该网站使用的技术
(url网址随意,baidu, imooc...都可以)
脚本运行结果:
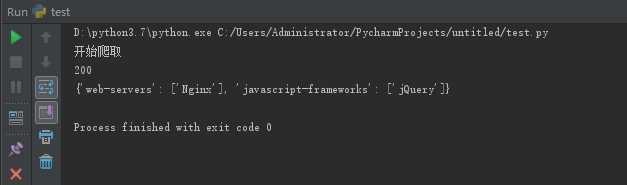
可以看到,程序正常运行,返回值200,爬取成功,builtwith模块得到了示例网站 web-servers: Nginx(服务器类型,详细了解),
使用了jQuery的javascript框架。但是碍于篇幅,其中HTML源码内容运行时注释掉了,不要惊讶!!!
r.text 结果(部分):
(内容无意中伤 Single Dog, Me too #_# )
转载请注明出处,欢迎留言讨论。