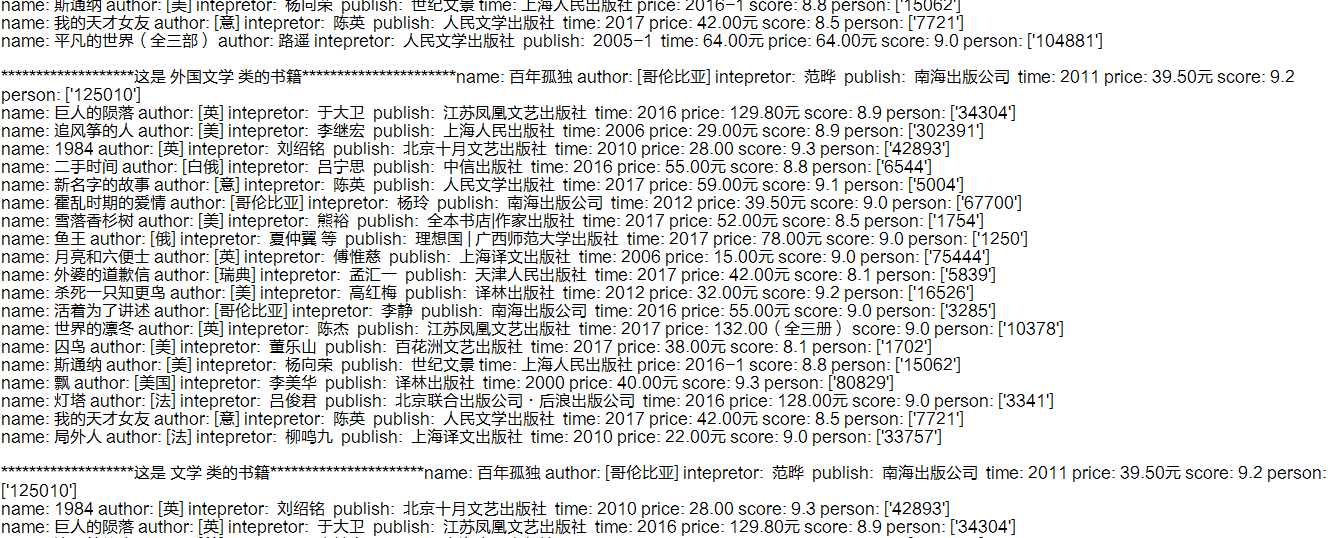
练习下BeautifulSoup,requests库,用python3.3 写了一个简易的豆瓣小爬虫,将爬取的信息在控制台输出并且写入文件中。
上源码:
1 # coding = utf-8 2 ‘‘‘my words 3 基于python3 需要的库 requests BeautifulSoup 4 这个爬虫很基本,没有采用任何的爬虫框架,用requests,BeautifulSoup,re等库。 5 这个爬虫的基本功能是爬取豆瓣各个类型的书籍的信息:作者,出版社,豆瓣评分,评分人数,出版时间等信息。 6 不能保证爬取到的信息都是正确的,可能有误。 7 也可以把爬取到的书籍信息存放在数据库中,这里只是输出到控制台。 8 爬取到的信息存储在文本txt中。 9 ‘‘‘ 10 11 import requests 12 from bs4 import BeautifulSoup 13 import re 14 15 #爬取豆瓣所有的标签分类页面,并且提供每一个标签页面的URL 16 def provide_url(): 17 # 以http的get方式请求豆瓣页面(豆瓣的分类标签页面) 18 responds = requests.get("https://book.douban.com/tag/?icn=index-nav") 19 # html为获得响应的页面内容 20 html = responds.text 21 # 解析页面 22 soup = BeautifulSoup(html, "lxml") 23 # 选取页面中的需要的a标签,从而提取出其中的所有链接 24 book_table = soup.select("#content > div > .article > div > div > .tagCol > tbody > tr > td > a") 25 # 新建一个列表来存放爬取到的所有链接 26 book_url_list = [] 27 for book in book_table: 28 book_url_list.append(‘https://book.douban.com/tag/‘ + str(book.string)) 29 return book_url_list 30 31 #获得评分人数的函数 32 def get_person(person): 33 person = person.get_text().split()[0] 34 person = re.findall(r‘[0-9]+‘,person) 35 return person 36 37 #当detail分为四段时候的获得价格函数 38 def get_rmb_price1(detail): 39 price = detail.get_text().split(‘/‘,4)[-1].split() 40 if re.match("USD", price[0]): 41 price = float(price[1]) * 6 42 elif re.match("CNY", price[0]): 43 price = price[1] 44 elif re.match("\A$", price[0]): 45 price = float(price[1:len(price)]) * 6 46 else: 47 price = price[0] 48 return price 49 50 #当detail分为三段时候的获得价格函数 51 def get_rmb_price2(detail): 52 price = detail.get_text().split(‘/‘,3)[-1].split() 53 if re.match("USD", price[0]): 54 price = float(price[1]) * 6 55 elif re.match("CNY", price[0]): 56 price = price[1] 57 elif re.match("\A$", price[0]): 58 price = float(price[1:len(price)]) * 6 59 else: 60 price = price[0] 61 return price 62 63 #测试输出函数 64 def test_print(name,author,intepretor,publish,time,price,score,person): 65 print(‘name: ‘,name) 66 print(‘author:‘, author) 67 print(‘intepretor: ‘,intepretor) 68 print(‘publish: ‘,publish) 69 print(‘time: ‘,time) 70 print(‘price: ‘,price) 71 print(‘score: ‘,score) 72 print(‘person: ‘,person) 73 74 75 76 77 #解析每个页面获得其中需要信息的函数 78 def get_url_content(url): 79 res = requests.get(url) 80 html = res.text 81 soup = BeautifulSoup(html.encode(‘utf-8‘),"lxml") 82 tag = url.split("?")[0].split("/")[-1] #页面标签,就是页面链接中‘tag/‘后面的字符串 83 titles = soup.select(".subject-list > .subject-item > .info > h2 > a") #包含书名的a标签 84 details = soup.select(".subject-list > .subject-item > .info > .pub") #包含书的作者,出版社等信息的div标签 85 scores = soup.select(".subject-list > .subject-item > .info > div > .rating_nums") #包含评分的span标签 86 persons = soup.select(".subject-list > .subject-item > .info > div > .pl") #包含评价人数的span标签 87 88 print("*******************这是 %s 类的书籍**********************" %tag) 89 90 #打开文件,将信息写入文件 91 file = open("C:/Users/lenovo/Desktop/book_info.txt",‘a‘) #可以更改为你自己的文件地址 92 file.write("*******************这是 %s 类的书籍**********************" % tag) 93 94 #用zip函数将相应的信息以元祖的形式组织在一起,以供后面遍历 95 for title,detail,score,person in zip(titles,details,scores,persons): 96 try:#detail可以分成四段 97 name = title.get_text().split()[0] #书名 98 author = detail.get_text().split(‘/‘,4)[0].split()[0] #作者 99 intepretor = detail.get_text().split(‘/‘,4)[1] #译者 100 publish = detail.get_text().split(‘/‘,4)[2] #出版社 101 time = detail.get_text().split(‘/‘,4)[3].split()[0].split(‘-‘)[0] #出版年份,只输出年 102 price = get_rmb_price1(detail) #获取价格 103 score = score.get_text() if True else "" #如果没有评分就置空 104 person = get_person(person) #获得评分人数 105 #在控制台测试打印 106 test_print(name,author,intepretor,publish,time,price,score,person) 107 #将书籍信息写入txt文件 108 try: 109 file.write(‘name: %s ‘ % name) 110 file.write(‘author: %s ‘ % author) 111 file.write(‘intepretor: %s ‘ % intepretor) 112 file.write(‘publish: %s ‘ % publish) 113 file.write(‘time: %s ‘ % time) 114 file.write(‘price: %s ‘ % price) 115 file.write(‘score: %s ‘ % score) 116 file.write(‘person: %s ‘ % person) 117 file.write(‘\n‘) 118 except (IndentationError,UnicodeEncodeError): 119 continue 120 121 except IndexError: 122 try:#detail可以分成三段 123 name = title.get_text().split()[0] # 书名 124 author = detail.get_text().split(‘/‘, 3)[0].split()[0] # 作者 125 intepretor = "" # 译者 126 publish = detail.get_text().split(‘/‘, 3)[1] # 出版社 127 time = detail.get_text().split(‘/‘, 3)[2].split()[0].split(‘-‘)[0] # 出版年份,只输出年 128 price = get_rmb_price2(detail) # 获取价格 129 score = score.get_text() if True else "" # 如果没有评分就置空 130 person = get_person(person) # 获得评分人数 131 #在控制台测试打印 132 test_print(name, author, intepretor, publish, time, price, score, person) 133 #将书籍信息写入txt文件 134 try: 135 file.write(‘name: %s ‘ % name) 136 file.write(‘author: %s ‘ % author) 137 file.write(‘intepretor: %s ‘ % intepretor) 138 file.write(‘publish: %s ‘ % publish) 139 file.write(‘time: %s ‘ % time) 140 file.write(‘price: %s ‘ % price) 141 file.write(‘score: %s ‘ % score) 142 file.write(‘person: %s ‘ % person) 143 file.write(‘\n‘) 144 except (IndentationError, UnicodeEncodeError): 145 continue 146 147 except (IndexError,TypeError): 148 continue 149 150 except TypeError: 151 continue 152 file 153 154 file.write(‘\n‘) 155 file.close() #关闭文件 156 157 158 #程序执行入口 159 if __name__ == ‘__main__‘: 160 #url = "https://book.douban.com/tag/程序" 161 book_url_list = provide_url() #存放豆瓣所有分类标签页URL的列表 162 for url in book_url_list: 163 get_url_content(url) #解析每一个URL的内容
下面是效果图: