前言:最近有同事反应有的接口响应时间时快时慢,经过排查有的数据层响应时间过长,为了加快定位定位慢sql的准确性,决定简单地搭建一个慢sql报警系统
具体流程如下架构图
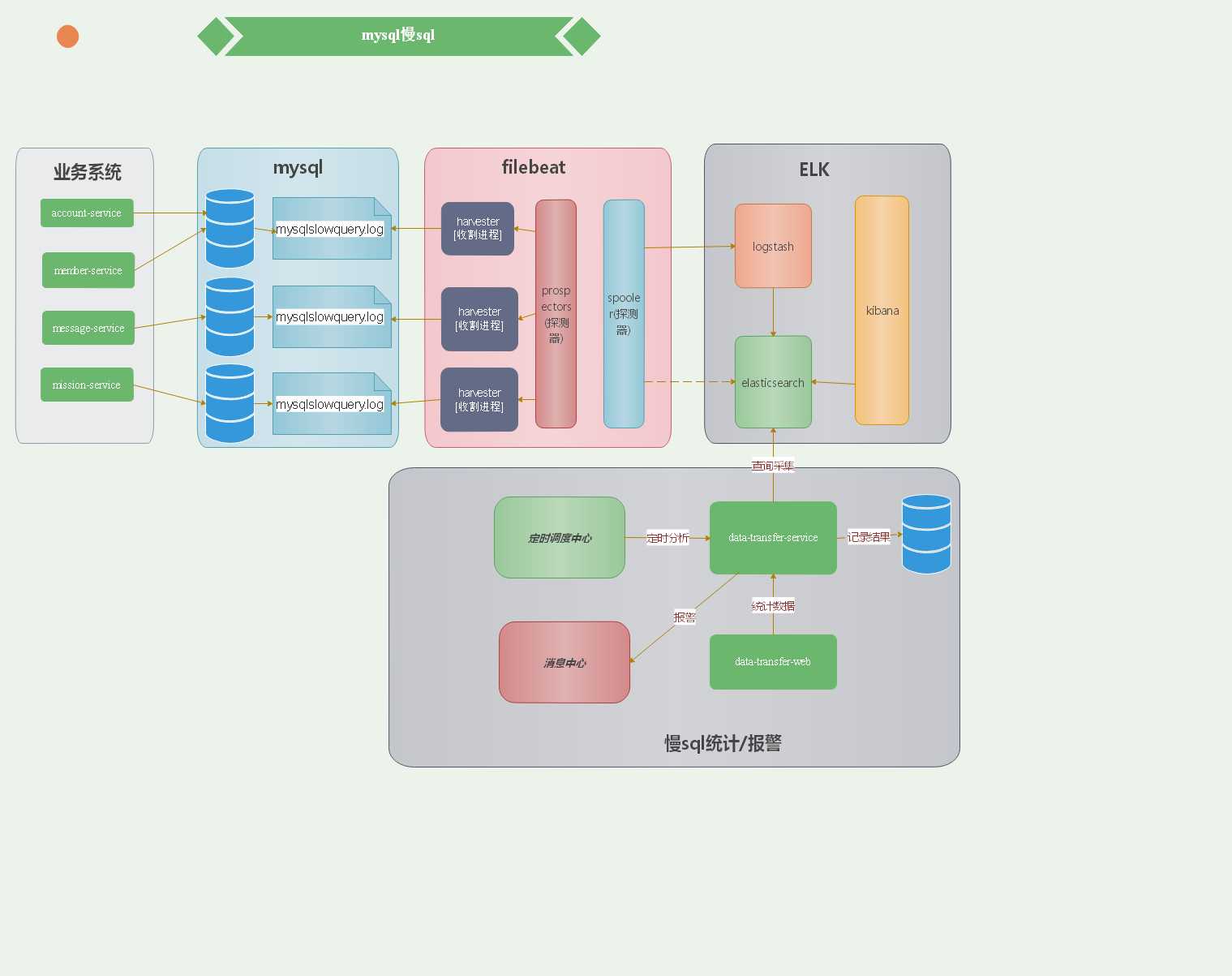
第一步:记录日志
每个业务系统都会在都会有自己的查询语句,所有的sql语句最红都会 我们先开启每个mysql的慢sql采集配置
1.将 slow_query_log 全局变量设置为“ON”状态
mysql> set global slow_query_log=‘ON‘;
2.设置慢查询日志存放的位置
3.mysql> set global slow_query_log_file=‘/usr/local/mysql/data/slow.log‘;
设置慢sql的时间
mysql> set global long_query_time=1;
测试一下
select sleep(3);去第二步设置的路径找到日志文件,打开日志发现会有一条记录
第二步:采集日志
当记录下所有的日志文件的之后,我们就需要采集,和传统的ELK那套模式一致,用filebeat去搜集(filebeat采集的原理就不多说介绍了),采集完成后就统一传输到logstash
第三步:格式化数据
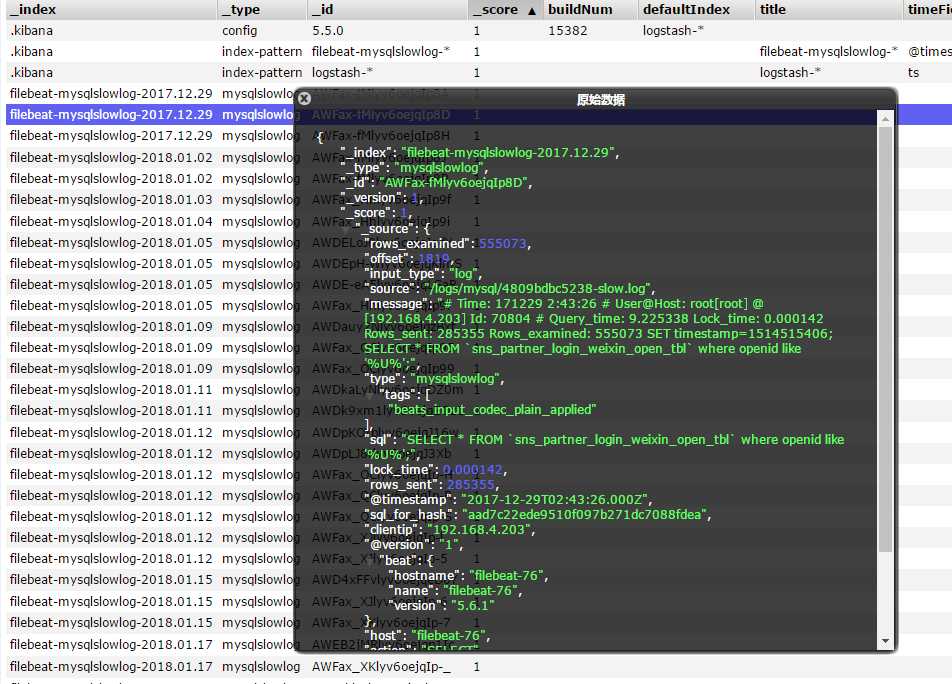
当logstash得到这些数据之后,需要格式化Elasticsearch需要的格式
注意:我们采集到日志格式中无法区分sql类型,比如select * from user where userId=2 和 select * from user where userId=5 是同一种类型,但是原始日志采集过来的数据无法判断,我们需要特殊处理一下:
1:用正则表达式把所有 数字和引号“”里面的内容都替换成?,
2:然后把返回的值用加密算法加密一下,得到一个新的字段
改字段就可以表明是某种类型的sql
第四步:分析和展示数据
Elasticsearch得到logstash传来的数据之后,就可以来检索了(sql_for_hash字段就行用来判别sql类型的字段)
第五步:报警功能
以上四步基本完成了mysql慢sql的采集分析过程,接下里就是报警功能,采用每小时(可以更短)去扫描es的中数据,根据日志中出现的查询时间以及每小时出现的次数决定报警级别,调用消息中心的报警接口进行报警,这样开发员人能够实时地接收到慢sql的出现的情况以便及时排除解决问题(后台也写了一个简单的统计页面方便查看)
