示例背景:
我的朋友海伦一直使用在线约会网站寻找合适自己的约会对象。尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人。经过一番总结,她发现曾交往过三种类型的人:
(1)不喜欢的人;
(2)魅力一般的人;
(3)极具魅力的人;
尽管发现了上述规律,但海伦依然无法将约会网站推荐的匹配对象归入恰当的分类,她觉得可以在周一到周五约会那些魅力一般的人,而周末则更喜欢与那些极具魅力的人为伴。海伦希望我们的分类软件可以更好地帮助她将匹配对象划分到确切的分类中。此外,海伦还收集了一些约会网站未曾记录的数据信息,她认为这些数据更助于匹配对象的归类。
准备数据:从文本文件中解析数据
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。海伦的样本主要包括以下3种特征:
1.每年获得的飞行常客里程数;
2.玩视频游戏所耗时间百分比;
3.每周消费的冰淇淋公升数;
在将上述特征数据输入到分类器之前,必须将待处理数据的格式改变为分类器可以接受的格式。在kNN.py中创建名为file2matrix的函数,以此来处理输入格式问题。该函数的输入为文本文件名字符串,输出为训练样本矩阵和类标签向量。
分析数据:使用Matplotlib创建散点图
2 import matplotlib as mpl 3 import matplotlib.pyplot as plt 4 import operator 5 6 7 def file2matrix(filename): #获取数据 8 f = open(filename) 9 arrayOLines = f.readlines() 10 numberOfLines = len(arrayOLines) 11 returnMat = zeros((numberOfLines,3),dtype=float) 12 #zeros(shape, dtype, order),创建一个shape大小的全为0矩阵,dtype是数据类型,默认为float,
#order表示在内存中排列的方式(以C语言或Fortran语言方式排列),默认为C语言排列 13 classLabelVector = [] 14 rowIndex = 0 15 for line in arrayOLines: 16 line = line.strip() 17 listFormLine = line.split(‘\t‘) 18 returnMat[rowIndex,:] = listFormLine[0:3] 19 classLabelVector.append(int(listFormLine[-1])) 20 rowIndex += 1 21 return returnMat, classLabelVector 22 23 24 if __name__ == "__main__": 25 datingDataMat, datingLabels = file2matrix(‘datingTestSet2.txt‘) 26 fig = plt.figure() #图 27 mpl.rcParams[‘font.sans-serif‘] = [‘KaiTi‘] 28 mpl.rcParams[‘font.serif‘] = [‘KaiTi‘] 29 plt.xlabel(‘玩视频游戏所耗时间百分比‘) 30 plt.ylabel(‘每周消费的冰淇淋公升数‘) 31 ‘‘‘ 32 matplotlib.pyplot.ylabel(s, *args, **kwargs) 33 34 override = { 35 ‘fontsize‘ : ‘small‘, 36 ‘verticalalignment‘ : ‘center‘, 37 ‘horizontalalignment‘ : ‘right‘, 38 ‘rotation‘=‘vertical‘ : } 39 ‘‘‘ 40 ax = fig.add_subplot(111) #将图分成1行1列,当前坐标系位于第1块处(这里总共也就1块) 41 ax.scatter(datingDataMat[: ,1], datingDataMat[: ,2],15.0*array(datingLabels), 15.0*array(datingLabels)) 42 #scatter是用来画散点图的 43 # scatter(x,y,s=1,c="g",marker="s",linewidths=0) 44 # s:散列点的大小,c:散列点的颜色,marker:形状,linewidths:边框宽度 45 plt.show()
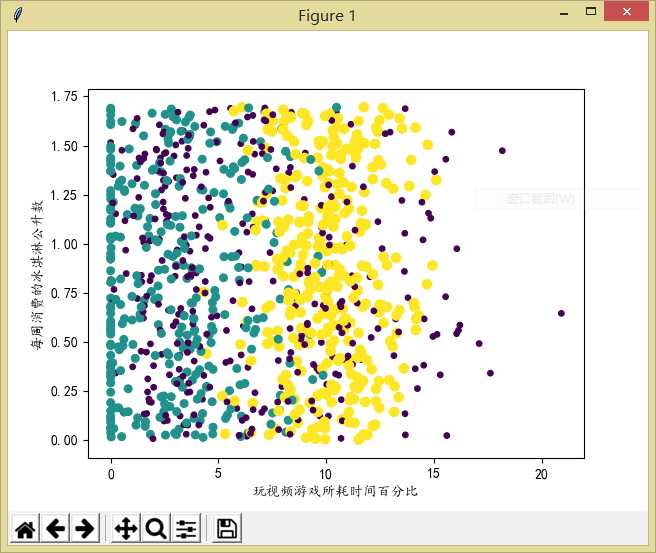
这是简单的创建了一下散点图,可以看到上面的图中还缺少了图例,所以下面的代码以另两列数据为例创建了带图例的散点图,代码大致还是一样的:
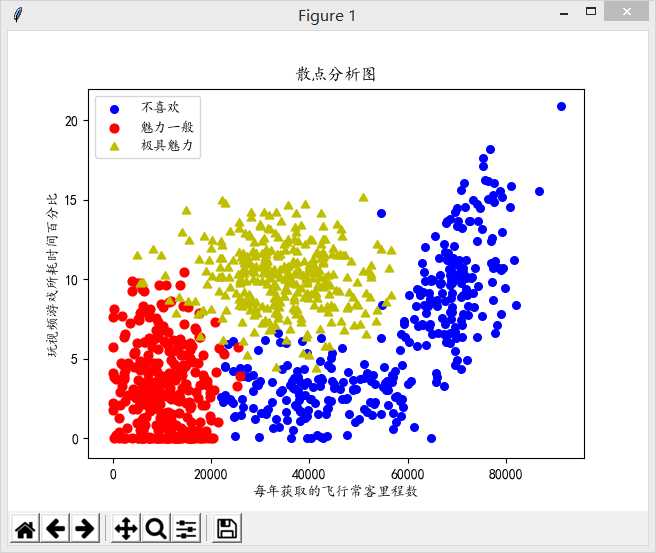
1 from numpy import * 2 import matplotlib as mpl 3 import matplotlib.pyplot as plt 4 import operator 5 6 def file2matrix(filename): #获取数据 7 f = open(filename) 8 arrayOLines = f.readlines() 9 numberOfLines = len(arrayOLines) 10 returnMat = zeros((numberOfLines,3),dtype=float) 11 #zeros(shape, dtype, order),创建一个shape大小的全为0矩阵,dtype是数据类型,默认为float,order表示在内存中排列的方式(以C语言或Fortran语言方式排列),默认为C语言排列 12 classLabelVector = [] 13 rowIndex = 0 14 for line in arrayOLines: 15 line = line.strip() 16 listFormLine = line.split(‘\t‘) 17 returnMat[rowIndex,:] = listFormLine[0:3] 18 classLabelVector.append(int(listFormLine[-1])) 19 rowIndex += 1 20 return returnMat, classLabelVector 21 22 if __name__ == "__main__": 23 datingDataMat, datingLabels = file2matrix(‘datingTestSet2.txt‘) 24 fig = plt.figure() #图 25 plt.title(‘散点分析图‘) 26 mpl.rcParams[‘font.sans-serif‘] = [‘KaiTi‘] 27 mpl.rcParams[‘font.serif‘] = [‘KaiTi‘] 28 plt.xlabel(‘每年获取的飞行常客里程数‘) 29 plt.ylabel(‘玩视频游戏所耗时间百分比‘) 30 ‘‘‘ 31 matplotlib.pyplot.ylabel(s, *args, **kwargs) 32 33 override = { 34 ‘fontsize‘ : ‘small‘, 35 ‘verticalalignment‘ : ‘center‘, 36 ‘horizontalalignment‘ : ‘right‘, 37 ‘rotation‘=‘vertical‘ : } 38 ‘‘‘ 39 40 type1_x = [] 41 type1_y = [] 42 type2_x = [] 43 type2_y = [] 44 type3_x = [] 45 type3_y = [] 46 ax = fig.add_subplot(111) #将图分成1行1列,当前坐标系位于第1块处(这里总共也就1块) 47 48 index = 0 49 for label in datingLabels: 50 if label == 1: 51 type1_x.append(datingDataMat[index][0]) 52 type1_y.append(datingDataMat[index][1]) 53 elif label == 2: 54 type2_x.append(datingDataMat[index][0]) 55 type2_y.append(datingDataMat[index][1]) 56 elif label == 3: 57 type3_x.append(datingDataMat[index][0]) 58 type3_y.append(datingDataMat[index][1]) 59 index += 1 60 61 type1 = ax.scatter(type1_x, type1_y, s=30, c=‘b‘) 62 type2 = ax.scatter(type2_x, type2_y, s=40, c=‘r‘) 63 type3 = ax.scatter(type3_x, type3_y, s=50, c=‘y‘, marker=(3,1)) 64 65 ‘‘‘ 66 scatter是用来画散点图的 67 matplotlib.pyplot.scatter(x, y, s=20, c=‘b‘, marker=‘o‘, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, verts=None, hold=None,**kwargs) 68 其中,xy是点的坐标,s点的大小 69 maker是形状可以maker=(5,1)5表示形状是5边型,1表示是星型(0表示多边形,2放射型,3圆形) 70 alpha表示透明度;facecolor=‘none’表示不填充。 71 ‘‘‘ 72 73 ax.legend((type1, type2, type3), (‘不喜欢‘, ‘魅力一般‘, ‘极具魅力‘), loc=0) 74 ‘‘‘ 75 loc(设置图例显示的位置) 76 ‘best‘ : 0, (only implemented for axes legends)(自适应方式) 77 ‘upper right‘ : 1, 78 ‘upper left‘ : 2, 79 ‘lower left‘ : 3, 80 ‘lower right‘ : 4, 81 ‘right‘ : 5, 82 ‘center left‘ : 6, 83 ‘center right‘ : 7, 84 ‘lower center‘ : 8, 85 ‘upper center‘ : 9, 86 ‘center‘ : 10, 87 ‘‘‘ 88 plt.show()
效果还是很不错的:
准备数据:归一化数值
当我们计算样本之间的欧几里得距离时,由于有些数值较大,所以它对结果整体的影响也就越大,那么小数据的可能就毫无影响了。在这个例子中飞行常客里程数很大,然而其余两列数据很小。为了解决这个问题,需要把数据相应的进行比例兑换,也就是这里需要做的归一化数值,将所有数值转化为[0,1]之间的值。
公式为:
$newValue = (oldValue-min)/(max-min)$ ($min$和$max$分别是数据集中的最小特征值和最大特征值)
1 def autoNorm(dataSet): #归一化数值 2 minVals = dataSet.min(0) #0表示每列的最小值,1表示每行的最小值,以一维矩阵形式返回 3 maxVals = dataSet.max(0) 4 ranges = maxVals - minVals 5 normDataSet = zeros(shape(dataSet)) 6 m = dataSet.shape[0] 7 normDataSet = dataSet - tile(minVals, (m,1)) 8 normDataSet = normDataSet/tile(ranges, (m,1)) 9 return normDataSet, ranges, minVals
测试并构造完整算法
根据这1000个数据,将其中的100个作为测试数据,另900个作为训练集,看着100个数据集的正确率。
最后根据自己输入的测试数据来判断应该出现的结果是什么。
1 from numpy import * 2 import matplotlib as mpl 3 import matplotlib.pyplot as plt 4 import operator 5 6 def classify0(inX, dataSet, labels, k): 7 dataSetSize = dataSet.shape[0] 8 diffMat = tile(inX, (dataSetSize,1)) - dataSet #统一矩阵,实现加减 9 sqDiffMat = diffMat**2 10 sqDistances = sqDiffMat.sum(axis=1) #进行累加,axis=0是按列,axis=1是按行 11 distances = sqDistances**0.5 #开根号 12 sortedDistIndicies = distances.argsort() #按升序进行排序,返回原下标 13 classCount = {} 14 for i in range(k): 15 voteIlabel = labels[sortedDistIndicies[i]] 16 classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 #get是字典中的方法,前面是要获得的值,后面是若该值不存在时的默认值 17 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) 18 return sortedClassCount[0][0] 19 20 21 def file2matrix(filename): #获取数据 22 f = open(filename) 23 arrayOLines = f.readlines() 24 numberOfLines = len(arrayOLines) 25 returnMat = zeros((numberOfLines,3),dtype=float) 26 #zeros(shape, dtype, order),创建一个shape大小的全为0矩阵,dtype是数据类型,默认为float,order表示在内存中排列的方式(以C语言或Fortran语言方式排列),默认为C语言排列 27 classLabelVector = [] 28 rowIndex = 0 29 for line in arrayOLines: 30 line = line.strip() 31 listFormLine = line.split(‘\t‘) 32 returnMat[rowIndex,:] = listFormLine[0:3] 33 classLabelVector.append(int(listFormLine[-1])) 34 rowIndex += 1 35 return returnMat, classLabelVector 36 37 38 def autoNorm(dataSet): #归一化数值 39 minVals = dataSet.min(0) #0表示每列的最小值,1表示每行的最小值,以一维矩阵形式返回 40 maxVals = dataSet.max(0) 41 ranges = maxVals - minVals 42 normDataSet = zeros(shape(dataSet)) 43 m = dataSet.shape[0] 44 normDataSet = dataSet - tile(minVals, (m,1)) 45 normDataSet = normDataSet/tile(ranges, (m,1)) 46 return normDataSet, ranges, minVals 47 48 49 def datingClassTest(datingDataMat, datingLabels): #测试正确率 50 hoRatio = 0.1 51 m = datingDataMat.shape[0] 52 numTestVecs = int(hoRatio*m) 53 numError = 0.0 54 for i in range(numTestVecs): 55 classifierResult = classify0(datingDataMat[i,:], datingDataMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3) 56 print(‘The classifier came back with: %d, the real answer is: %d.‘ %(classifierResult, datingLabels[i])) 57 if (classifierResult != datingLabels[i]): 58 numError += 1 59 print(‘错误率为 %f‘ %(numError/float(numTestVecs))) 60 61 62 def classifyPerson(datingDataMat, datingLabels, ranges, minVals): 63 result = [‘not at all‘, ‘in small doses‘, ‘in large doses‘] 64 print(‘请输入相应信息:‘) 65 percentTats = float(input(‘percentage of time spent playing video games?‘)) 66 ffMiles = float(input(‘frequent flier miles earned per year?‘)) 67 iceCream = float(input(‘liters of ice cream consumed per year?‘)) 68 inArr = array([ffMiles, percentTats, iceCream]) 69 classifyResult = classify0((inArr-minVals)/ranges, datingDataMat, datingLabels, 3) 70 print(‘You will probably like this person: ‘, result[classifyResult-1]) 71 72 73 if __name__ == "__main__": 74 datingDataMat, datingLabels = file2matrix(‘datingTestSet2.txt‘) 75 datingDataMat, ranges, minVals = autoNorm(datingDataMat) #归一化数值 76 datingClassTest(datingDataMat, datingLabels) 77 classifyPerson(datingDataMat, datingLabels, ranges, minVals) 78 fig = plt.figure() #图 79 plt.title(‘散点分析图‘) 80 mpl.rcParams[‘font.sans-serif‘] = [‘KaiTi‘] 81 mpl.rcParams[‘font.serif‘] = [‘KaiTi‘] 82 plt.xlabel(‘每年获取的飞行常客里程数‘) 83 plt.ylabel(‘玩视频游戏所耗时间百分比‘) 84 ‘‘‘ 85 matplotlib.pyplot.ylabel(s, *args, **kwargs) 86 87 override = { 88 ‘fontsize‘ : ‘small‘, 89 ‘verticalalignment‘ : ‘center‘, 90 ‘horizontalalignment‘ : ‘right‘, 91 ‘rotation‘=‘vertical‘ : } 92 ‘‘‘ 93 94 type1_x = [] 95 type1_y = [] 96 type2_x = [] 97 type2_y = [] 98 type3_x = [] 99 type3_y = [] 100 ax = fig.add_subplot(111) #将图分成1行1列,当前坐标系位于第1块处(这里总共也就1块) 101 102 index = 0 103 for label in datingLabels: 104 if label == 1: 105 type1_x.append(datingDataMat[index][0]) 106 type1_y.append(datingDataMat[index][1]) 107 elif label == 2: 108 type2_x.append(datingDataMat[index][0]) 109 type2_y.append(datingDataMat[index][1]) 110 elif label == 3: 111 type3_x.append(datingDataMat[index][0]) 112 type3_y.append(datingDataMat[index][1]) 113 index += 1 114 115 type1 = ax.scatter(type1_x, type1_y, s=30, c=‘b‘) 116 type2 = ax.scatter(type2_x, type2_y, s=40, c=‘r‘) 117 type3 = ax.scatter(type3_x, type3_y, s=50, c=‘y‘, marker=(3,1)) 118 119 ‘‘‘ 120 scatter是用来画散点图的 121 matplotlib.pyplot.scatter(x, y, s=20, c=‘b‘, marker=‘o‘, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, verts=None, hold=None,**kwargs) 122 其中,xy是点的坐标,s点的大小 123 maker是形状可以maker=(5,1)5表示形状是5边型,1表示是星型(0表示多边形,2放射型,3圆形) 124 alpha表示透明度;facecolor=‘none’表示不填充。 125 ‘‘‘ 126 127 ax.legend((type1, type2, type3), (‘不喜欢‘, ‘魅力一般‘, ‘极具魅力‘), loc=0) 128 ‘‘‘ 129 loc(设置图例显示的位置) 130 ‘best‘ : 0, (only implemented for axes legends)(自适应方式) 131 ‘upper right‘ : 1, 132 ‘upper left‘ : 2, 133 ‘lower left‘ : 3, 134 ‘lower right‘ : 4, 135 ‘right‘ : 5, 136 ‘center left‘ : 6, 137 ‘center right‘ : 7, 138 ‘lower center‘ : 8, 139 ‘upper center‘ : 9, 140 ‘center‘ : 10, 141 ‘‘‘ 142 plt.show()
可以看到错误率为5%:

