Linux 操作系统和驱动程序运行在内核空间,应用程序运行在用户空间,两者不能简单地使用指针传递数据,因为Linux使用的虚拟内存机制,用户空间的数据可能被换出,当内核空间使用用户空间指针时,对应的数据可能不在内存中。
Linux内核地址空间划分
通常32位Linux内核地址空间划分0~3G为用户空间,3~4G为内核空间。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。
1、x86的物理地址空间布局:

物理地址空间的顶部以下一段空间,被PCI设备的I/O内存映射占据,它们的大小和布局由PCI规范所决定。640K~1M这段地址空间被BIOS和VGA适配器所占据。
Linux系统在初始化时,会根据实际的物理内存的大小,为每个物理页面创建一个page对象,所有的page对象构成一个mem_map数组。
进一步,针对不同的用途,Linux内核将所有的物理页面划分到3类内存管理区中,如图,分别为ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM。
ZONE_DMA的范围是0~16M,该区域的物理页面专门供I/O设备的DMA使用。之所以需要单独管理DMA的物理 页面,是因为DMA使用物理地址访问内存,不经过MMU,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区 域用于DMA。
ZONE_NORMAL的范围是16M~896M,该区域的物理页面是内核能够直接使用的。
ZONE_HIGHMEM的范围是896M~结束,该区域即为高端内存,内核不能直接使用。
2、linux虚拟地址内核空间分布

在kernel image下面有16M的内核空间用于DMA操作。位于内核空间高端的128M地址主要由3部分组成,分别为vmalloc area,持久化内核映射区,临时内核映射区。
由于ZONE_NORMAL和内核线性空间存在直接映射关系,所以内核会将频繁使用的数据如kernel代码、GDT、IDT、PGD、 mem_map数组等放在ZONE_NORMAL里。而将用户数据、页表(PT)等不常用数据放在ZONE_ HIGHMEM里,只在要访问这些数据时才建立映射关系(kmap())。比如,当内核要访问I/O设备存储空间时,就使用ioremap()将位于物理 地址高端的mmio区内存映射到内核空间的vmalloc area中,在使用完之后便断开映射关系。
3、linux虚拟地址用户空间分布

用户进程的代码区一般从虚拟地址空间的0x08048000开始,这是为了便于检查空指针。代码区之上便是数据区,未初始化数据区,堆区,栈区,以及参数、全局环境变量。
4、linux虚拟地址与物理地址映射的关系

Linux将4G的线性地址空间分为2部分,0~3G为user space,3G~4G为kernel space。
由于开启了分页机制,内核想要访问物理地址空间的话,必须先建立映射关系,然后通过虚拟地址来访问。为了能够访问所有的 物理地址空间,就要将全部物理地址空间映射到1G的内核线性空间中,这显然不可能。于是,内核将0~896M的物理地址空间一对一映射到自己的线性地址空 间中,这样它便可以随时访问ZONE_DMA和ZONE_NORMAL里的物理页面;此时内核剩下的128M线性地址空间不足以完全映射所有的 ZONE_HIGHMEM,Linux采取了动态映射的方法,即按需的将ZONE_HIGHMEM里的物理页面映射到kernel space的最后128M线性地址空间里,使用完之后释放映射关系,以供其它物理页面映射。虽然这样存在效率的问题,但是内核毕竟可以正常的访问所有的物 理地址空间了。
5、buddyinfo的理解
cat /proc/buddyinfo 显示如下:
Node 0, zone DMA 0 4 5 4 4 3 ...
Node 0, zone Normal 1 0 0 1 101 8 ...
Node 0, zone HighMem 2 0 0 1 1 0 ...
其中,Node表示在NUMA环境下的节点号,这里只有一个节点0;zone表示每一个节点下的区域,一般有DMA、Normal和HignMem 三个区域;后面的列表示,伙伴系统中每一个order对应的空闲页面块。例如,对于zone DMA的第二列(从0开始算起),空闲页面数为5*2^4,可用内存为5*2^4*PAGE_SIZE。
计算方法就是:
当前列的数字*2^列数*PAGE_SIZE 其中列数是从0开始计算的,即第一列是 当前列的数字*2^0*PAGE_SIZE
常见问题:
1、用户空间(进程)是否有高端内存概念?
用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
高端内存只和逻辑地址有关系,和逻辑地址、物理地址没有直接关系。
5、为什么不把所有的地址空间都分配给内核?
若把所有地址空间都给内存,那么用户进程怎么使用内存?怎么保证内核使用内存和用户进程不起冲突?
由于所有用户进程总的虚拟地址空间比可用的物理内存大很多,因此只有最常用的部分才与物理页帧关联。这不是问题,因为大多数程序只占用实际可用内存的一小部分。
在将磁盘上的数据映射到进程的虚拟地址空间的时,内核必须提供数据结构,以建立虚拟地址空间的区域和相关数据所在位置之间的关联。例如,在映射文本文件时,映射的虚拟内存区必须关联到文件系统的硬盘上存储文件内容的区域。如图所示:
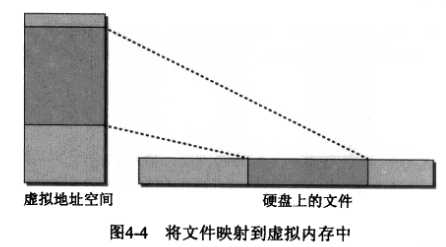
当然,给出的是简化的图,因为文件数据在硬盘上的存储通常并不是连续的,而是分布到若干小的区域。内核利用address_space数据结构,提 供一组方法从后备存储器读取数据。例如,从文件系统读取。因此address_space形成了一个辅助层,将映射的数据表示为连续的线性区域,提供给内 存管理子系统。
按需分配和填充页称为按需调页法。它基于处理器和内核之间的交互,使用的各种数据结构如图所示:
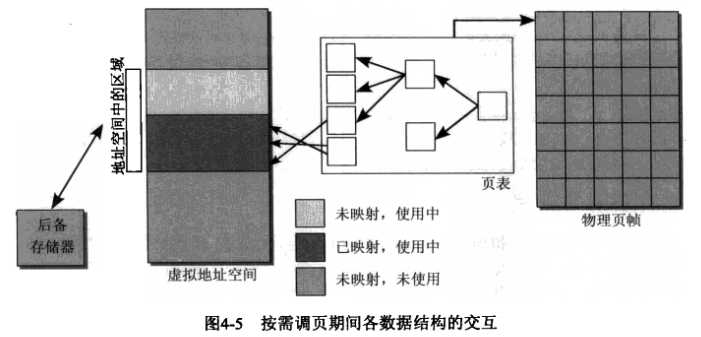
过程如下:
CPU将一个虚拟内存空间中的地址转换为物理地址,需要进行两步(如下图):
首先,将给定一个逻辑地址(其实是段内偏移量,这个一定要理解!!!),CPU要利用其段式内存管理单元,先将为个逻辑地址转换成一个线程地址,
其次,再利用其页式内存管理单元,转换为最终物理地址。

这样做两次转换,的确是非常麻烦而且没有必要的,因为直接可以把线性地址抽像给进程。之所以这样冗余,Intel完全是为了兼容而已。
- 进程试图访问用户地址空间中的一个内存地址,利用上面的线性地址去查找页表,确定对应的物理地址,但使用的页表无法确定物理地址(物理内存中没有关联页)
- 处理器接下来触发一个缺页异常,发送到内核。
- 内核会检查负责缺页区域的进程地址空间数据结构,找到适当的后备存储器,或者确认该访问实际上是不正确的(未映射,未使用)
- 分配物理内存页,并从后备存储器读取所需数据填充。
- 借助于页表将物理内存页并入到用户进程的地址空间,应用程序恢复执行。
这些操作对用户进程是透明的。换句话说,进程不会注意到页是实际在物理内存中,还是需要通过按需调页加载。
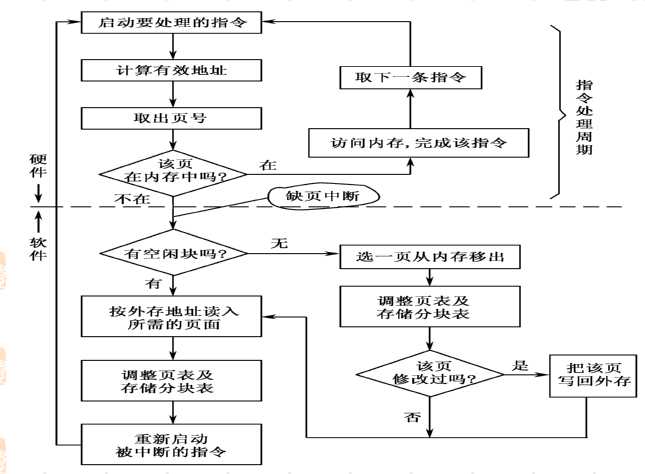
在整个过程中可能需要解决以下几个问题:
1)系统如何感知进程当前所需页面不在主存(页表机制);
2)当发现缺页时,如何把所缺页面调入主存(缺页中断机构);
3)在置换页面时,根据什么策略选择欲淘汰的页面(置换算法)。
页表机制

状态位(中断位):标识该页是否在内存(0或1);
访问位:标识该页面的近来的访问次数或时间(换出);
修改位:标识此页是否在内存中被修改过;
外存地址:记录该页面在外存上的地址,即(外存而非内存的)物理块号。
缺页中断机制
程序在执行时,首先检查页表,当状态位指示该页不在主存时,则引起一个缺页中断发生,其中断执行过程与一般中断相同:
保护现场(CPU环境);
中断处理(中断处理程序装入页面);
恢复现场,返回断点继续执行。