继续看这个文档
http://www.360doc.com/content/16/0104/11/22743342_525336297.shtml
SQL Server表分区
什么是表分区
一般情况下,我们建立数据库表时,表数据都存放在一个文件里。
但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在不同的磁盘下由多个cpu进行处理。这样文件的大小随着拆分而减小,还得到硬件系统的加强,自然对我们操作数据是大大有利的。
所以大数据量的数据表,对分区的需要还是必要的,因为它可以提高select效率,还可以对历史数据经行区分存档等。但是数据量少的数据就不要凑这个热闹啦,因为表分区会对数据库产生不必要的开销,除啦性能还会增加实现对象的管理费用和复杂性。
跟着做,分区如此简单
先跟着做一个分区表(分为11个分区),去除神秘的面纱,然后咱们再逐一击破各个要点要害。
分区是要把一个表数据拆分为若干子集合,也就是把把一个数据文件拆分到多个数据文件中,然而这些文件的存放可以依托一个文件组或这多个文件组,由于多个文件组可以提高数据库的访问并发量,还可以把不同的分区配置到不同的磁盘中提高效率,所以创建时建议分区跟文件组个数相同。
1.创建文件组
可以点击数据库属性在文件组里面添加
T-sql语法:
alter database <数据库名> add filegroup <文件组名>

---创建数据库文件组 alter database testSplit add filegroup ByIdGroup1 alter database testSplit add filegroup ByIdGroup2 alter database testSplit add filegroup ByIdGroup3 alter database testSplit add filegroup ByIdGroup4 alter database testSplit add filegroup ByIdGroup5 alter database testSplit add filegroup ByIdGroup6 alter database testSplit add filegroup ByIdGroup7 alter database testSplit add filegroup ByIdGroup8 alter database testSplit add filegroup ByIdGroup9 alter database testSplit add filegroup ByIdGroup10
2.创建数据文件到文件组里面
可以点击数据库属性在文件里面添加
T-sql语法:
alter database <数据库名称> add file <数据标识> to filegroup <文件组名称> --<数据标识> (name:文件名,fliename:物理路径文件名,size:文件初始大小kb/mb/gb/tb,filegrowth:文件自动增量kb/mb/gb/tb/%,maxsize:文件可以增加到的最大大小kb/mb/gb/tb/unlimited)
alter database testSplit add file (name=N‘ById1‘,filename=N‘J:\Work\数据库\data\ById1.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup1 alter database testSplit add file (name=N‘ById2‘,filename=N‘J:\Work\数据库\data\ById2.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup2 alter database testSplit add file (name=N‘ById3‘,filename=N‘J:\Work\数据库\data\ById3.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup3 alter database testSplit add file (name=N‘ById4‘,filename=N‘J:\Work\数据库\data\ById4.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup4 alter database testSplit add file (name=N‘ById5‘,filename=N‘J:\Work\数据库\data\ById5.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup5 alter database testSplit add file (name=N‘ById6‘,filename=N‘J:\Work\数据库\data\ById6.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup6 alter database testSplit add file (name=N‘ById7‘,filename=N‘J:\Work\数据库\data\ById7.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup7 alter database testSplit add file (name=N‘ById8‘,filename=N‘J:\Work\数据库\data\ById8.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup8 alter database testSplit add file (name=N‘ById9‘,filename=N‘J:\Work\数据库\data\ById9.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup9 alter database testSplit add file (name=N‘ById10‘,filename=N‘J:\Work\数据库\data\ById10.ndf‘,size=5Mb,filegrowth=5mb) to filegroup ByIdGroup10
执行完成后,右键数据库看文件组跟文件里面是不是多出来啦这些文件组跟文件。
3.使用向导创建分区表
右键到要分区的表--- >> 存储 --- >> 创建分区 --- >>显示向导视图 --- >> 下一步 --- >> 下一步。。
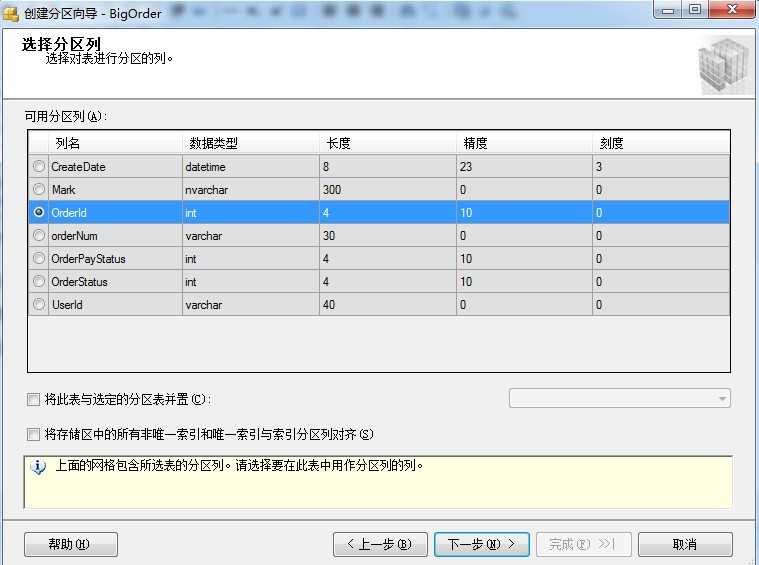
这里举例说下选择列的意思:
假如你选择的是int类型的列:那么你的分区可以指定为1--100W是一个分区,100W--200W是一个分区....
假如你选择的是datatime类型:那么你的分区可以指定为:2014-01-01--2014-01-31一个分区,2014-02-01--2014-02-28一个分区...
根据这样的列数据规则划分,那么在那个区间的数据,在插入数据库时就被指向那个分区存储下来。
我这里选用orderid int类型 --- >> 下一步 --- >>
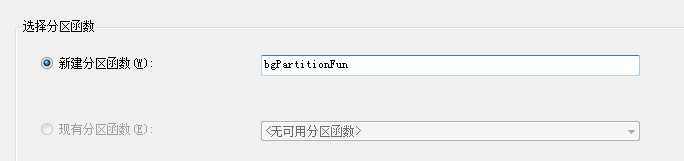
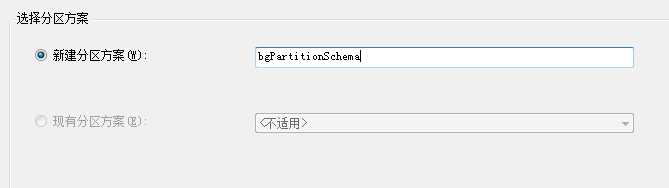
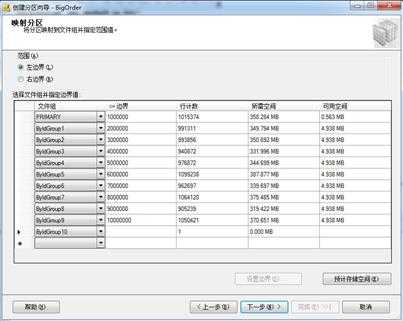
左边界右边界:就是把临界值划分给上一个分区还是下一个分区。一个小于号,一个小于等于号。
然后下一步下一步最后你会得到分区函数和分区方案。
USE [testSplit]
GO
BEGIN TRANSACTION
--创建分区函数
CREATE PARTITION FUNCTION [bgPartitionFun](int) AS RANGE LEFT FOR VALUES (N‘1000000‘, N‘2000000‘, N‘3000000‘, N‘4000000‘, N‘5000000‘, N‘6000000‘, N‘7000000‘, N‘8000000‘, N‘9000000‘, N‘10000000‘)
--创建分区方案
CREATE PARTITION SCHEME [bgPartitionSchema] AS PARTITION [bgPartitionFun] TO ([PRIMARY], [ByIdGroup1], [ByIdGroup2], [ByIdGroup3], [ByIdGroup4], [ByIdGroup5], [ByIdGroup6], [ByIdGroup7], [ByIdGroup8], [ByIdGroup9], [ByIdGroup10])
--创建分区索引
CREATE CLUSTERED INDEX [ClusteredIndex_on_bgPartitionSchema_635342971076448165] ON [dbo].[BigOrder]
(
[OrderId]
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [bgPartitionSchema]([OrderId])
--删除分区索引
DROP INDEX [ClusteredIndex_on_bgPartitionSchema_635342971076448165] ON [dbo].[BigOrder] WITH ( ONLINE = OFF )
COMMIT TRANSACTION
执行上面向导生成的语句。分区完成。。
4.秀一下速度。
首先我在表中插入啦1千万行数据。给表分啦11个分区。前十个分区里面一个是100W条数据。。
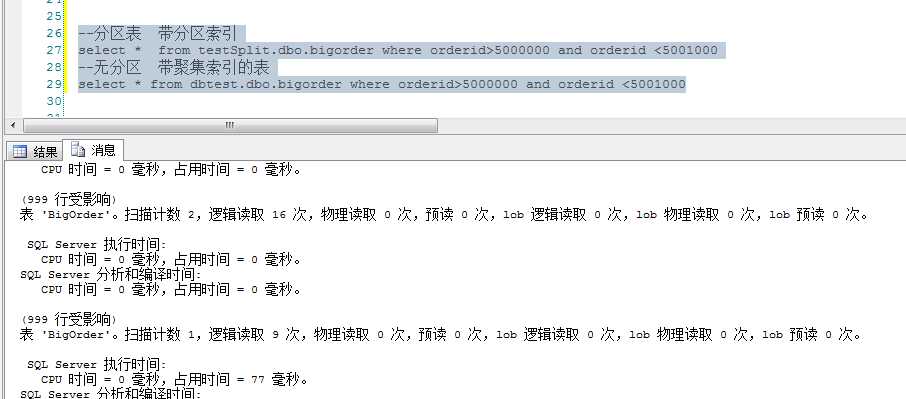
说两句:
可见反常现象,扫描次数跟逻辑读取次数都是无分区表的2倍之多,但查询速度却是快啦不少啊。这就是分区的神奇之处啊,所以要相信这世界一切皆有可能。
分区函数,分区方案,分区表,分区索引
1.分区函数
指定分依据区列(依据列唯一),分区数据范围规则,分区数量,然后将数据映射到一组分区上。
创建语法:
create partition function 分区函数名(<分区列类型>) as range [left/right] for values (每个分区的边界值,....)
--创建分区函数 CREATE PARTITION FUNCTION [bgPartitionFun](int) AS RANGE LEFT FOR VALUES (N‘1000000‘, N‘2000000‘, N‘3000000‘, N‘4000000‘, N‘5000000‘, N‘6000000‘, N‘7000000‘, N‘8000000‘, N‘9000000‘, N‘10000000‘)
然而,分区函数只定义了分区的方法,此方法具体用在哪个表的那一列上,则需要在创建表或索引是指定。
删除语法:
--删除分区语法 drop partition function <分区函数名>
--删除分区函数 bgPartitionFun drop partition function bgPartitionFun
需要注意的是,只有没有应用到分区方案中的分区函数才能被删除。
2.分区方案
指定分区对应的文件组。
创建语法:
--创建分区方案语法 create partition scheme <分区方案名称> as partition <分区函数名称> [all]to (文件组名称,....)
--创建分区方案,所有分区在一个组里面 CREATE PARTITION SCHEME [bgPartitionSchema] AS PARTITION [bgPartitionFun] TO ([ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1], [ByIdGroup1])
分区函数必须关联分区方案才能有效,然而分区方案指定的文件组数量必须与分区数量一致,哪怕多个分区存放在一个文件组中。
删除语法:
--删除分区方案语法 drop partition scheme<分区方案名称>
--删除分区方案 bgPartitionSchema drop partition scheme bgPartitionSchema1
只有没有分区表,或索引使用该分区方案是,才能对其删除。
3.分区表
创建语法:
--创建分区表语法 create table <表名> ( <列定义> )on<分区方案名>(分区列名)
--创建分区表 create table BigOrder ( OrderId int identity, orderNum varchar(30) not null, OrderStatus int not null default 0, OrderPayStatus int not null default 0, UserId varchar(40) not null, CreateDate datetime null default getdate(), Mark nvarchar(300) null )on bgPartitionSchema(OrderId)
如果在表中创建主键或唯一索引,则分区依据列必须为该列。
4.分区索引
创建语法:
--创建分区索引语法 create <索引分类> index <索引名称> on <表名>(列名) on <分区方案名>(分区依据列名)
--创建分区索引
CREATE CLUSTERED INDEX [ClusteredIndex_on_bgPartitionSchema_635342971076448165] ON [dbo].[BigOrder]
(
[OrderId]
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [bgPartitionSchema]([OrderId])
使用分区索引查询,可以避免多个cpu操作多个磁盘时产生的冲突。
分区表明细信息
这里的语法,我就不写啦,自己看语句分析吧。简单的很。。
1.查看分区依据列的指定值所在的分区
--查询分区依据列为10000014的数据在哪个分区上 select $partition.bgPartitionFun(2000000) --返回值是2,表示此值存在第2个分区
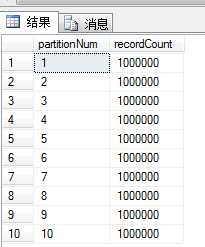
2.查看分区表中,每个非空分区存在的行数
--查看分区表中,每个非空分区存在的行数 select $partition.bgPartitionFun(orderid) as partitionNum,count(*) as recordCount from bigorder group by $partition.bgPartitionFun(orderid)
3.查看指定分区中的数据记录
---查看指定分区中的数据记录 select * from bigorder where $partition.bgPartitionFun(orderid)=2
结果:数据从1000001开始到200W结束
分区的拆分与合并以及数据移动
1.拆分分区
在分区函数中新增一个边界值,即可将一个分区变为2个。
--分区拆分 alter partition function bgPartitionFun() split range(N‘1500000‘) --将第二个分区拆为2个分区
注意:如果分区函数已经指定了分区方案,则分区数需要和分区方案中指定的文件组个数保持对应一致。
2.合并分区
与拆分分区相反,去除一个边界值即可。
--合并分区 alter partition function bgPartitionFun() merge range(N‘1500000‘) --将第二第三分区合并
3.分区中的数据移动
你或许会遇到这样的需求,将普通表数据复制到分区表中,或者将分区表中的数据复制到普通表中。
那么移动数据这两个表,则必须满足下面的要求。
- 字段数量相同,对应位置的字段相同
- 相同位置的字段要有相同的属性,相同的类型。
- 两个表在一个文件组中
1.创建表时指定文件组
--创建表 create table <表名> ( <列定义> )on <文件组名>
2.从分区表中复制数据到普通表
--将bigorder分区表中的第一分区数据复制到普通表中 alter table bigorder switch partition 1 to <普通表名>
3.从普通标中复制数据到分区表中
这里要注意的是要先将分区表中的索引删除,即便普通表中存在跟分区表中相同的索引。
--将普通表中的数据复制到bigorder分区表中的第一分区 alter table <普通表名> switch to bigorder partition 1
分区视图
分区视图是先建立带有字段约束的相同表,而约束不同,例如,第一个表的id约束为0--100W,第二表为101万到200万.....依次类推。
创建完一系列的表之后,用union all 连接起来创建一个视图,这个视图就形成啦分区视同。
很简单的,这里我主要是说分区表,就不说分区视图啦。。
查看数据库分区信息
SELECT OBJECT_NAME(p.object_id) AS ObjectName,
i.name AS IndexName,
p.index_id AS IndexID,
ds.name AS PartitionScheme,
p.partition_number AS PartitionNumber,
fg.name AS FileGroupName,
prv_left.value AS LowerBoundaryValue,
prv_right.value AS UpperBoundaryValue,
CASE pf.boundary_value_on_right
WHEN 1 THEN ‘RIGHT‘
ELSE ‘LEFT‘ END AS Range,
p.rows AS Rows
FROM sys.partitions AS p
JOIN sys.indexes AS i
ON i.object_id = p.object_id
AND i.index_id = p.index_id
JOIN sys.data_spaces AS ds
ON ds.data_space_id = i.data_space_id
JOIN sys.partition_schemes AS ps
ON ps.data_space_id = ds.data_space_id
JOIN sys.partition_functions AS pf
ON pf.function_id = ps.function_id
JOIN sys.destination_data_spaces AS dds2
ON dds2.partition_scheme_id = ps.data_space_id
AND dds2.destination_id = p.partition_number
JOIN sys.filegroups AS fg
ON fg.data_space_id = dds2.data_space_id
LEFT JOIN sys.partition_range_values AS prv_left
ON ps.function_id = prv_left.function_id
AND prv_left.boundary_id = p.partition_number - 1
LEFT JOIN sys.partition_range_values AS prv_right
ON ps.function_id = prv_right.function_id
AND prv_right.boundary_id = p.partition_number
WHERE
OBJECTPROPERTY(p.object_id, ‘ISMSShipped‘) = 0
UNION ALL
SELECT
OBJECT_NAME(p.object_id) AS ObjectName,
i.name AS IndexName,
p.index_id AS IndexID,
NULL AS PartitionScheme,
p.partition_number AS PartitionNumber,
fg.name AS FileGroupName,
NULL AS LowerBoundaryValue,
NULL AS UpperBoundaryValue,
NULL AS Boundary,
p.rows AS Rows
FROM sys.partitions AS p
JOIN sys.indexes AS i
ON i.object_id = p.object_id
AND i.index_id = p.index_id
JOIN sys.data_spaces AS ds
ON ds.data_space_id = i.data_space_id
JOIN sys.filegroups AS fg
ON fg.data_space_id = i.data_space_id
WHERE
OBJECTPROPERTY(p.object_id, ‘ISMSShipped‘) = 0
ORDER BY
ObjectName,
IndexID,
PartitionNumber

按此理解,1年就有12个分区,如果随着时间的增长,该怎么分区呢?另外,此前已经存了大量数据的表还能做分区么?用时间类型的分区方案该是什么样的比较合理呢?
就是楼主那样 千万的 每个分区百万 取10000条
split range(N‘2012-01-01T00:00:00‘) --将第二个分区拆为2个分区”,报错“警告: 分区方案 ‘bgpartitionPerson‘ 没有任何下次使用的文件组。分区方案未更改。”始终不明白什么原因?
select * from [testDB].[dbo].[user_new] where $partition.userPartFounction(id)=2
和
select * from [testDB].[dbo].[user_new] where $partition.userPartFounction(id)=2
都能查到数据,是不说我这个表分区创建的时候就对user和user_new都创建了同样的表分区啊?
和
select * from [testDB].[dbo].[user] where $partition.userPartFounction(id)=2
都能查到数据,是不说我这个表分区创建的时候就对user和user_new都创建了同样的表分区啊?
我的理解是分区更侧重于数据库的管理,比如按照分区进行数据的备份,还原,drop或delete等。但是对于查询的效率提升有限(比起索引,高质量的Query而言),看到另外一个帖子也是这么说。
1. 如果我有10个表,都有一个RowId 字段,我希望这些表都用这个字段按照相同的方案进行表分区,我可以共用一个PartitionScheme和一个PartitionFunction吗?还是我需要分别创建10个类似的PartitionScheme和10个PartitionFunction给他们用?
2. 第三节:“3.使用向导创建分区表” 生成的脚本最后两步是“创建分区索引”,“删除分区索引”,为什么创建了分区索引马上又删除了这个分区索引,这是为什么呢?
3. 如果一个表已经存在一个聚集索引了,我不想用聚集索引这列做分区,可以用其他列做分区且仍然保持原来那列为聚集索引吗?
4. 删除分区的时候索引会失效吗?
谢谢~~
你这种只算是水平分区。