编码和字符串
编码
在学习回顾中总结一下ASCII编码、Unicode编码和utf-8编码。
计算机中只能处理数字,我们若要处理文本的话就要将文件转换为数字。所以,这就涉及该怎样转换的问题,也就是编码问题。
在计算机中使用8个比特(bit)作为一个字节(byte),一个字节最大的表示范围是255(从0开始),意味着一个字节最多表示256个字符,表示更多的字符需要更多的字节。
ASCII编码
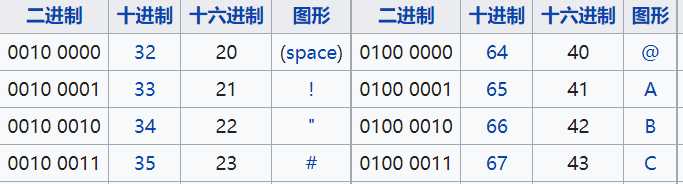
因为计算机是美国人发明的,所以最早就只有127个字符被编码到计算机中。127个字符包括大小写英文字母、数字和一些符号。这个编码也被称为ASCII编码。在ASCII码表中记录着127个字符所对应的十六进制和十进制等信息。
附一张ASCII码表的截图。
Unicode编码
见名知意,Unicode编码的意思就应该是统一编码之意。早期计算机刚诞生之时只做军队和大学研究之用不算普遍,可是后面发展迅速,在很多国家都在广泛使用计算机。为了能让各个国家统一处理语言编码问题就需要一种统一的编码,最开始的ASCII编码仅能表示256个字符远远不能满足需求,所以就产生了Unicode编码。
Unicode编码最常用的是两个字节表示一个字符(如果是非常偏僻的字符则需要四个字节)
utf-8
实际上,Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一致,以及出于节省空间的目的,对Unicode编码的实现方式会有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)
如果一个仅包含基本7位ASCII字符的Unicode文件,如果每个字符都使用2字节的原Unicode编码传输,其第一字节的8位始终为0。这就造成了比较大的浪费。对于这种情况,可以使用UTF-8编码,这是一种变长编码,UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
因此,如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
字符串
在Python3中,文本是Unicode编码,由str类型表示,二进制数据则由bytes类型表示。
需要注意Python对bytes类型数据用带b前缀的单引号或双引号表示如:x=b‘time‘
当数据保存在磁盘上或者在网络上传输时,我们需要将str类型数据转换为二进制数据类型bytes。
以Unicode表示的str可以通过encode()方法编码为指定的bytes
>>> ‘ABC‘.encode(‘ascii‘)
b‘ABC‘
>>> ‘中文‘.encode(‘utf-8‘)
b‘\xe4\xb8\xad\xe6\x96\x87‘
>>> ‘中文‘.encode(‘ascii‘)
Traceback (most recent call last):
File "<input>", line 1, in <module>
UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 0-1: ordinal not in range(128)以上可以也证明中文编码不能用ascii编码
如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法。
当然,bytes中可能包含无法解码的字节,这时decode()方法会报错,如果bytes中只有一小部分无效的字节,可以传入errors=‘ignore‘忽略错误的字节
>>> b‘ABC‘.decode(‘ascii‘)
‘ABC‘
>>> b‘\xe4\xb8\xad\xe6\x96\x87‘.decode(‘utf-8‘)
‘中文‘
>>> b‘\xe4\xb8\xad\xff‘.decode(‘utf-8‘)
Traceback (most recent call last):
File "<input>", line 1, in <module>
UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xff in position 3: invalid start byte
>>> b‘\xe4\xb8\xad\xff‘.decode(‘utf-8‘,errors=‘ignore‘)
‘中‘
还有一点需要注意一下,len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数
>>> len(‘中文‘.encode(‘utf-8‘))
6
>>> len(‘中文‘)
2