基本查询
orderby子句
形式:
order by 排序字段1 [排序方式], 排序字段2 [排序方式], .....
说明:
对前面取得的数据(含from子句,where子句,group子句,having子句的所有结果)来指定按某个字段的大小进行排列(排序),排序只有2种方式:
正序: ASC(默认值),可以省略
倒序: DESC
如果指定多个字段排序(虽然不常见),则其含义是,在前一个字段排序中相同的那些数据里,再按后一字段的大小进行指定的排序。


limit子句
形式:
limit [起始行号start], 要取出的行数num
说明:
表示将前面取得的数据并前面排好之后(如果有),对之指定取得“局部连续的若干条”数据。
起始行号start:第一行的行号为0, 可以省略,则为默认行号(0)。
要取得的行数:如果结果集中从指定的行号开始到最后没有这么多行,则就只取到最后。
此子句非常有用——主要用于网页上最常见的一个需求(现象):分页。
分页原理:
分页的前提:人为指定每页显示的条数,$pageSize = 3;
显示(取得)第1页数据:select * from 表名 limit 0, $pageSize;
显示(取得)第2页数据:select * from 表名 limit 3, $pageSize;
显示(取得)第3页数据:select * from 表名 limit 6, $pageSize;
显示(取得)第$n页数据:select * from 表名 limit ($n-1)*$pageSize, $pageSize;
连接查询
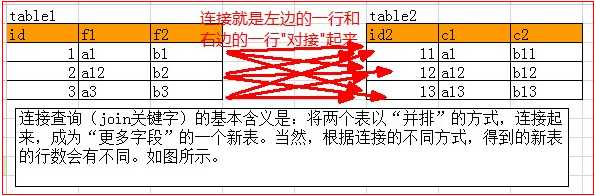
连接就是指两个或2个以上的表(数据源)“连接起来成为一个数据源”。
实际上,两个表的完全的连接是这样的一个过程:
左边的表的每一行,跟右边的表的每一行,两两互相“横向对接”后所得到的所有数据行的结果。
注意:连接之后,并非形成了一个新的数据表,而只是一种“内存形态”。
语法形式:from 表1 [连接方式] join 表2 [on 连接条件];
例:
select * from course join teacher on course.cno=teacher.cno
select student.sno,course.cname,score.degree from student join score on score.sno=student.sno join course on course.cno=score.cno;
交叉连接:
实际上,交叉连接是将两个表不设定任何条件的连接结果。
交叉连接通常也被叫做“笛卡尔积”——数学上可能比较多。
语法形式:
from 表1 [cross] join 表2 ; //可见交叉连接只是没有on条件而已。
cross这个词也可以省略,还可以使用inner这个词代替
内连接:相当于连接查询
语法:
from 表1 [inner] join 表2 on 表1.字段1=表2.字段2;
左[外]连接:
形式:
from 表1 left [outer] join 表2 on 连接条件。
说明:
1,这里,left是关键字。
2,连接条件跟内连接一样。
3,含义是:内连接的结果基础上,加上左边表中所有不符合连接条件的数据,相应本应放右边表的字段的位置就自动补为“null”值。
右[外]连接:
形式:
from 表1 right [outer] join 表2 on 连接条件。
说明:
1,这里,right是关键字。
2,连接条件跟内连接一样。
3,含义是:在内连接的结果基础上,加上右边表中所有不符合连接条件的数据,相应本应放左边表的字段的位置就自动补为“null”值。
全[外]连接:
相当于左外查询和右外查询的合集。
形式:
from 表1 full [outer] join 表2 on 连接条件;
说明:
1,含义:其实是左右连接的“并集”(消除重复项),即内连接的结果,加上左表中不满足条件的所有行(右边对应补null),再加上,右表中不满足条件的所有行(左边对应补null)。
2,mysql中其实不认识全[外]连接语法,即mysql这个软件本身不支持全连接的语法。
3,此概念在其他数据库有的存在,了解就可以。
常见子查询及相关关键字
子查询
一个查询,通常就是一个select语句(即出现一次select关键字)
但,如果在一个select查询语句中,又出现了select查询语句,此时就称后者为“子查询”,前者就是“主查询”
形式:
selelct 字段或表达式或(子查询1) [as 别名] from 表名或(子查询2) where 字段或表达式或(子查询3) 的条件判断
使用in子查询
in的基本语法形式为:
where 操作数 in (值1,值2, ....)
则in子查询就是:
where 操作数 in ( 列子查询 );
含义:
表示该操作数(字段值) 等于 该子查询的其中任意一个只,就算满足条件。
使用any子查询
使用形式:
where 操作数 比较运算符 any ( 列子查询 );
说明:
1操作数通常仍然是字段名
2比较运算符就是常规的〉 〉= < <= = <>
3列子查询也可以是标量子查询,都表示“若干个数据值”
含义:
表示该操作数的值只要跟列子查询的任意一个值满足给定的比较运算,就算满足了条件——就是只要有一个成就成。
特殊情况:
where 操作数 = any ( 列子查询 );
则其完全相当于:
where 操作数 in ( 列子查询 );
使用all子查询
where 操作数 比较运算符 all ( 列子查询 );
说明:
1操作数通常仍然是字段名
2比较运算符就是常规的〉 〉= < <= = <>
3列子查询也可以是标量子查询,都表示“若干个数据值”
含义:
表示该操作数的值必须跟列子查询的所有值都满足给定的比较运算,才算满足了条件。
使用some的子查询
some是any的同义词。一样用。
使用exists的子查询
形式:
where exists (子查询);
含义:
如果该子查询有结果数据(无论什么数据,只要大于等于1行),则就是true,否则为false
not exists子查询:
和exists子查询相反。
联合查询
联合查询的关键字是: union 对行的扩展,两张表 字段相同,结果不同
连接查询的关键字是: join 对列的扩展,两张表左右拼起来
联合查询就是将两个select语句的查询结果“层叠”到一起成为一个“大结果”。
两个查询结果的能够进行“联合”的先觉条件是:结果字段数相等。
语法形式:
select 语句1 union [ALL | DISTINCT] select 语句2;
说明:
1,两个select语句的输出段(结果字段)一样数目一样,应用中通常类型一样才有意义。
2,结果集中的字段以第一个select语句的字段为准。
3,第一个select语句的字段可以做别名,但如果做别名,则后续的where,group,order等子句应该用该别名。
4,联合查询默认是会消除重复项的(DISTINCT),要想不消除,则必须明确些“ALL”。
5,如果要对整个联合结果进行排序或limit,则应该对各自的select语句加括号:
(select 语句1)
union
(select 语句2)
order by ..... limit ....;
例:
#31、 查询所有教师和同学的name、sex和birthday. select sname,ssex,sbirthday from student union select tname,tsex,tbirthday from teacher; #32、查询所有“女”教师和“女”同学的name、sex和birthday. select sname,ssex,sbirthday from student where ssex="女" union select tname,tsex,tbirthday from teacher where tsex="女";