前一篇文章,我们使用re模块来匹配了一个长的字符串其中的部分内容。下面我们接着来作匹配“1305101765@qq.com advantage 314159265358 1892673 3.14 little Girl try_your_best 56 123456789@163.com python3”
我们的目标是匹配‘56’,其中\d表示匹配数字,{2}表示匹配次数为两次,{M,N},M,N均为非负整数,M<=N,表示匹配M-N次。在匹配规则前面加个r的意思是表示原生字符串。
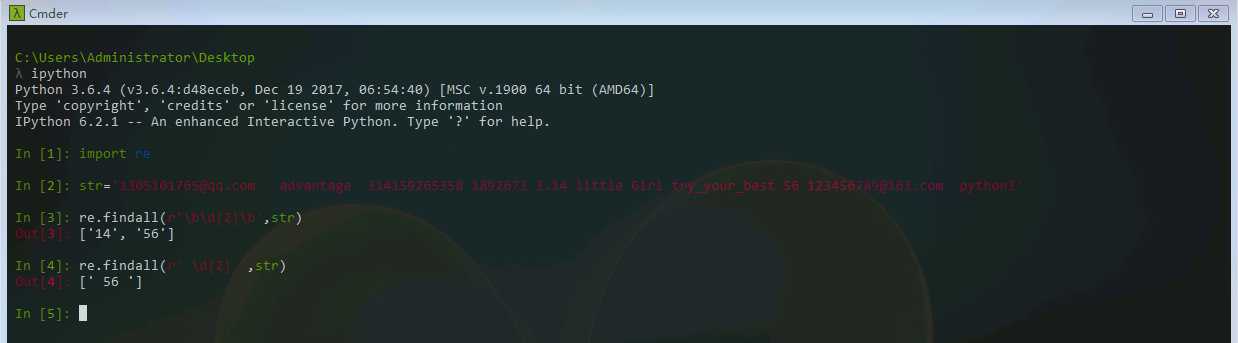
实际上我们在使用正则表达式的时候,通常先将其编译成pattern对象,使用re.compile()方法来进行编译。下面我们来匹配IP地址如:192.168.1.1。
1 import re 2 3 str=‘192.168.1.1‘ 4 5 re.search(r‘(([01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])\.){3}([01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])‘,str)
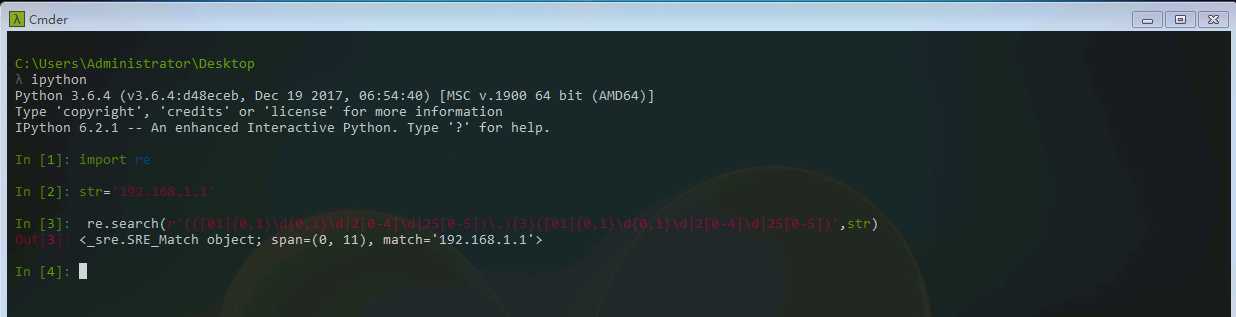
可以看出来,正则使用起来并不简单。在上面的规则中,我们是用了三个子组,如果我们在网页上用findall匹配所有IP,它会把结果给分类了,变成(‘192’,‘168’,‘1’,‘1’)。显然这不是我们想要的。这时候,我们需要用(?:...)来表示非捕获组,即该子组匹配的字符串无法从后面获取。
有了之前的基础,我尝试着写下了如下的代码,从西刺代理网站上爬取IP地址,并用代理访问网站验证其是否可用。当中用到了python的异常处理机制。虽然代码不成熟,但还是分享出来,慢慢改进。
1 import urllib.request 2 import re 3 4 5 url="http://www.xicidaili.com/" 6 useful_ip=[] 7 def loadPage(url): 8 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} 9 response=urllib.request.Request(url,headers=headers) 10 html=urllib.request.urlopen(response).read().decode("utf-8") 11 return html 12 13 def getProxy(): 14 html=loadPage(url) 15 pattern=re.compile(r‘(<td>\d+</td>)‘) 16 duankou=pattern.findall(html) 17 pattern=re.compile(r‘(?:(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])\.){3}(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])‘) 18 content_list=pattern.findall(html) 19 list_num=[] 20 for num in duankou: 21 list_num.append(num[4:-5]) 22 for i in range(len(list_num)): 23 ip=content_list[i]+ ":"+list_num[i] 24 while True: 25 proxy_support=urllib.request.ProxyHandler({‘http‘:ip}) 26 opener=urllib.request.build_opener(proxy_support) 27 opener.add_handler=[("User-Agent","Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36")] 28 urllib.request.install_opener(opener) 29 try: 30 print("正在尝试使用 %s 访问..." % ip) 31 ip_filter="http://www.whatsmyip.org/" 32 ip_response=urllib.request.urlopen(ip_filter) 33 except urllib.error.URLError: 34 print("访问出错,这个IP不能用啦") 35 break 36 else: 37 print("访问成功!") 38 print("可用IP为: %s " % ip) 39 useful_ip.append(ip) 40 if input("继续爬取?")=="N": 41 print("有效IP如下:") 42 for key in useful_ip: 43 print(key) 44 exit() 45 else: 46 break 47 48 if __name__=="__main__": 49 getProxy()
在处理IP地址对应的端口号时,我用的一个非常笨的方法。实际上有更好的办法解决,大家也可以想一想。在上面这段代码中,使用urllib访问网站、Handler处理器自定义opener、python异常处理、正则匹配ip等一系列的知识点。任何知识,用多了才会熟练。
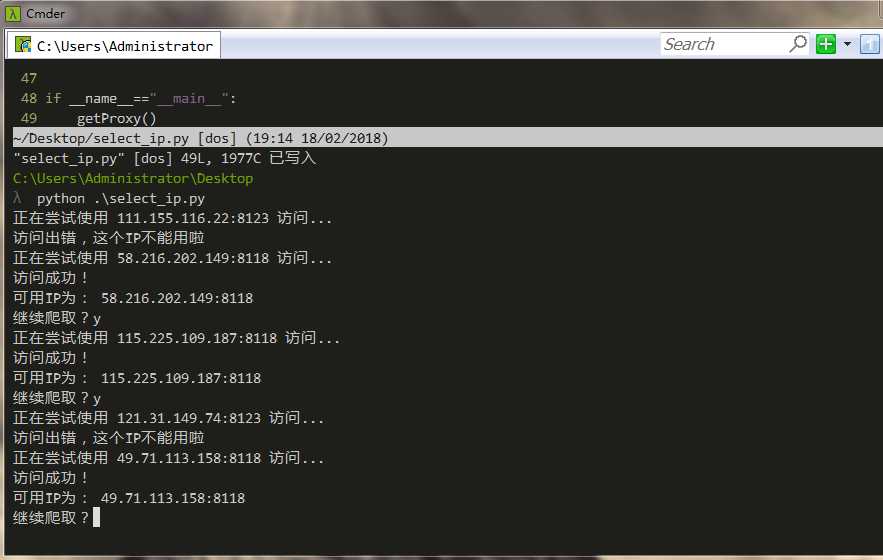
可以看到它运行成功,并且找到一个可用IP后会问你是否继续爬取。当然,我们可以手动构建一个IPPOOL即IP池,自定义一个函数,把可以用的IP写入一个文件保存起来,这里就不作赘述了。在github上有成熟的ip池代码,大家可以下载下来阅读,这里只是把前面讲的一些用法做一个简单的试验,因此并没有把这段代码完善。