Apache Spark 2.2最近引入了高级的基于成本的优化器框架用于收集并均衡不同的列数据的统计工作 (例如., 基(cardinality)、唯一值的数量、空值、最大最小值、平均/最大长度,等等)来改进查询类作业的执行计划。均衡这些作业帮助Spark在选取最优查询计划时做出更好决定。这些优化的例子包括在做hash-join时选择正确的一方建hash,选择正确的join类型(广播hash join和全洗牌hash-join)或调整多路join的顺序,等等)
在该博客中,我们将深入讲解Spark的基于成本的优化器(CBO)并讨论Spark是如何收集并存储这些数据、优化查询,并在压力测试查询中展示所带来的性能影响。
一个启发性的例子
在Spark2.2核心,Catalyst优化器是一个统一的库,用于将查询计划表示成多颗树并依次使用多个优化规则来变换他们。大部门优化规则都基于启发式,例如,他们只负责查询的结构且不关心要处理数据的属性,这样严重限制了他们的可用性。让我们用一个简单的例子来演示。考虑以下的查询,该查询过滤大小为500GB的t1表并与另一张大小为20GB的t2表做join操作。Spark使用hash join,即选择小的join关系作为构建hash表的一方并选择大的join关系作为探测方。由于t2表比t1表小, Apache Spark 2.1 将会选择右方作为构建hash表的一方而不是对其进行过滤操作(在这个案例中就是会过滤出t1表的大部分数据)。选择错误那方做构建hash表经常会导致系统由于内存限制的原因去放弃快速hash join而使用排序-归并 join(sort-merge join)。
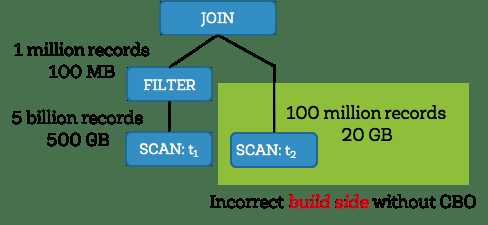
而Apache Spark 2.2却不这么做,它会收集每个操作的统计信息 并发现左方在过滤后大小只有100MB (1 百万条纪录) ,而过滤右方会有20GB (1亿条纪录)。有了两侧正确的表大小/基的信息,Spark 2.2会选择左方为构建方,这种选择会极大加快查询速度。
为了改进查询执行计划的质量,我们使用详细的统计信息加强了Spark SQL优化器。从详细的统计信息中,我们传播统计信息到别的操作子(因为我们从下往上遍历查询树)。传播结束,我们可以估计每个数据库操作子的输出记录数和输出纪录的大小,这样就可以得到一个高效的查询计划。
统计信息收集框架
ANALYZE TABLE 命令
CBO依赖细节化的统计信息来优化查询计划。要收集这些统计信息,用户可以使用以下这些新的SQL命令:
1 ANALYZE TABLE table_name COMPUTE STATISTICS
上面的 SQL 语句可以收集表级的统计信息,例如记录数、表大小(单位是byte)。这里需要注意的是ANALYZE, COMPUTE, and STATISTICS都是保留的关键字,他们已特定的列名为入参,在metastore中保存表级的统计信息。
1 ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS column-name1, column-name2, ….
需要注意的是在ANALYZE 语句中没必要指定表的每个列-只要指定那些在过滤/join条件或group by等中涉及的列
统计信息类型
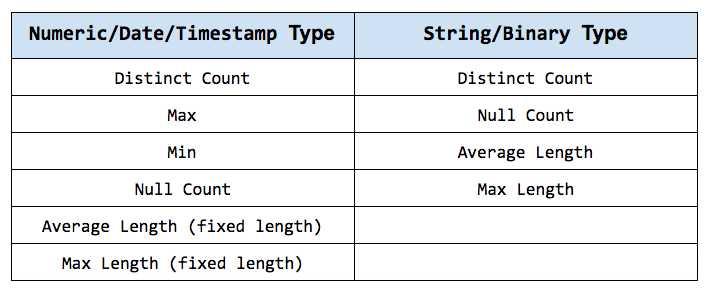
下表列出了所收集的统计信息的类型,包括数字类型、日期、时间戳和字符串、二进制数据类型
由于CBO是以后续方式遍历Spark的逻辑计划树,我们可以自底向上地把这些统计信息传播到其他操作子。虽然我们要评估的统计信息及对应开销的操作子有很多,我们将讲解两个最复杂且有趣的操作子FILTER 和JOIN的评估统计信息的流程。
过滤选择
过滤条件是配置在SQL SELECT语句中的WHERE 子句的谓语表达式。谓语可以是包含了逻辑操作子AND、OR、NOT且包含了多个条件的复杂的逻辑表达式 。单个条件通常包含比较操作子,例如=, <, <=, >, >= or <=>。因此,根据全部过滤表达式来估计选择是非常复杂的。
我们来演示对包含多个条件逻辑表达式的复杂逻辑表达式做过滤选择 的一些计算。
- 对于逻辑表达式AND,他的过滤选择是左条件的选择乘以右条件选择,例如fs(a AND b) = fs(a) * fs (b)。
- 对于逻辑表达式OR,他的过滤选择是左条件的选择加上右条件选择并减去左条件中逻辑表达式AND的选择,例如 fs (a OR b) = fs (a) + fs (b) - fs (a AND b) = fs (a) + fs (b) – (fs (a) * fs (b))
- 对于逻辑表达式NOT,他的过滤因子是1.0 减去原表达式的选择,例如 fs (NOT a) = 1.0 - fs (a)
现在我们看下可能有多个操作子的单个逻辑条件例如 =, <, <=, >, >= or <=>。对于单个操作符作为列,另一个操作符为字符串的情况,我们先计算等于 (=) 和小于 (<) 算子的过滤选择。其他的比较操作符也是类似。
- 等于操作符 (=) :我们检查条件中的字符串常量值是否落在列的当前最小值和最大值的区间内 。这步是必要的,因为如果先使用之前的条件可能会导致区间改变。如果常量值落在区间外,那么过滤选择就是 0.0。否则,就是去重后值的反转(注意:不包含额外的柱状图信息,我们仅仅估计列值的统一分布)。后面发布的版本将会均衡柱状图来优化估计的准确性。
-
小于操作符 (<) :检查条件中的字符串常量值落在哪个区间。如果比当前列值的最小值还小,那么过滤选择就是 0.0(如果大于最大值,选择即为1.0)。否则,我们基于可用的信息计算过滤因子。如果没有柱状图,就传播并把过滤选择设置为: (常量值– 最小值) / (最大值 – 最小值)。另外,如果有柱状图,在计算过滤选择时就会加上在当前列最小值和常量值之间的柱状图桶密度 。同时,注意在条件右边的常量值此时变成了该列的最大值。
Join基数
我们已经讨论了过滤选择, 现在讨论join的输出基。在计算二路join的输出基之前,我们需要先有双方孩子节点的输出基 。每个join端的基都不会超过原表记录数的基。更准确的说,是在执行join操作子之前,执行所有操作后得到的有效纪录数。在此,我们偏好计算下內连接(inner join)操作的基因为它经常用于演化出其他join类型的基。我们计算下在 A.k = B.k 条件下A join B 的记录数 ,即
num(A IJ B) = num(A)*num(B)/max(distinct(A.k),distinct(B.k))
num(A) 是join操作上一步操作执行后表A的有效记录数, distinct是join列 k唯一值的数量。
如下所示,通过计算内连接基,我们可以大概演化出其他join类型的基:
- 左外连接(Left-Outer Join): num(A LOJ B) = max(num(A IJ B),num(A)) 是指内连接输出基和左外连接端A的基之间较大的值。这是因为我们需要把外端的每条纪录计入,虽然他们没有出现在join输出纪录内。
- Right-Outer Join: num(A ROJ B) = max(num(A IJ B),num(B))
- Full-Outer Join: num(A FOJ B) = num(A LOJ B) + num(A ROJ B) - num(A IJ B)
最优计划选择
现在我们已经有了数据统计的中间结果,让我们讨论下如何使用这个信息来选择最佳的查询计划。早先我们解释了在hash join操作中根据精确的基和统计信息选择构建方。
同样,根据确定的基和join操作的前置所有操作的大小估计,我们可以更好的估计join测的大小来决定该测是否符合广播的条件。
这些统计信息同时也有助于我们均衡基于成本的join的重排序优化。我们适配了动态编程算法[Selinger 1979]3 来选取最佳的多路join顺序。更确切的说,在构建多路join时候,我们仅考虑同个集合(包含m个元素)的最佳方案(成本最低)。举个例子,对于3路join,我们根据元素 {A, B, C} 可能的排列顺序,即 (A join B) join C, (A join C) join B 和(B join C) join A来考虑最佳join方案。我们适配 的算法考虑了所有的组合,包括左线性树(left-deep trees),浓密树(bushy trees)和右线性树(right-deep-trees)。我们还修剪笛卡儿积(cartesian product )用于在构建新的计划时如果左右子树都没有join条件包含的引用需要情况。这个修剪策略显著减少了搜索范围。
大部分数据库优化器将CPU和I/O计入考虑因素,分开考虑成本来估计总共的操作开销。在Spark中,我们用简单的公式估计join操作的成本:
cost = weight * cardinality + (1.0 - weight) * size 4
公式的第一部分对应CPU成本粗略值,第二部分对应IO。一颗join树的成本是所有中间join成本的总和。
查询的性能测试和分析
我们使用非侵入式方法把这些基于成本的优化加入到Spark,通过加入全局配置spark.sql.cbo.enabled来开关这个特性。在Spark 2.2, 这个参数默认是false 。短期内有意设置该特性默认为关闭,因为的Spark被上千家公司用于生产环境,默认开启该特性可能会导致生产环境压力变大从而导致不良后果。
配置及方法学
在四个节点 (单台配置:Huawei FusionServer RH2288 , 40 核和384 GB 内存) 的集群用TPC-DS来测试Apache Spark 2.2查询性能。在四个节点的集群运行测试查询性能的语句并设比例因子为1000(大概1TB数据)。收集全部24张表(总共245列)的统计信息大概要14分钟。
在校验端到端的结果前,我们先看一条查询语句TPC-DS(Q25; 如下所示)来更好了解基于成本的join排序带来的威力。这句查询语句包括三张事实表: store_sales (29 亿行纪录), store_returns (2.88 亿行纪录) 和catalog_sales (14.4 亿行纪录). 同时也包括三张维度表: date_dim(7.3万行纪录), store (1K 行纪录) 和 item (300K 行纪录).
1 SELECT
2 i_item_id,
3 i_item_desc,
4 s_store_id,
5 s_store_name,
6 sum(ss_net_profit) AS store_sales_profit,
7 sum(sr_net_loss) AS store_returns_loss,
8 sum(cs_net_profit) AS catalog_sales_profit
9 FROM
10 store_sales, store_returns, catalog_sales, date_dim d1, date_dim d2, date_dim d3,
11 store, item
12 WHERE
13 d1.d_moy = 4
14 AND d1.d_year = 2001
15 AND d1.d_date_sk = ss_sold_date_sk
16 AND i_item_sk = ss_item_sk
17 AND s_store_sk = ss_store_sk
18 AND ss_customer_sk = sr_customer_sk
19 AND ss_item_sk = sr_item_sk
20 AND ss_ticket_number = sr_ticket_number
21 AND sr_returned_date_sk = d2.d_date_sk
22 AND d2.d_moy BETWEEN 4 AND 10
23 AND d2.d_year = 2001
24 AND sr_customer_sk = cs_bill_customer_sk
25 AND sr_item_sk = cs_item_sk
26 AND cs_sold_date_sk = d3.d_date_sk
27 AND d3.d_moy BETWEEN 4 AND 10
28 AND d3.d_year = 2001
29 GROUP BY
30 i_item_id, i_item_desc, s_store_id, s_store_name
31 ORDER BY
32 i_item_id, i_item_desc, s_store_id, s_store_name
33 LIMIT 100
没使用CBO的Q25
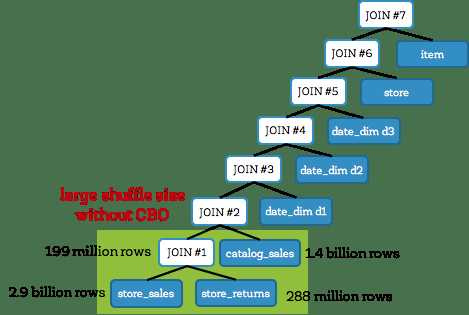
我们先看下没使用基于成本优化的Q25的join树(如下)。一般这种树也叫做左线性树。这里, join #1 和 #2 是大的事实表与事实表join,join了3张事实表store_sales, store_returns, 和catalog_sales,并产生大的中间结果表。这两个join都以shuffle join的方式执行并会产生大的输出,其中join #1输出了1.99亿行纪录。总之,关闭CBO,查询花费了241秒。
使用了CBO的Q25
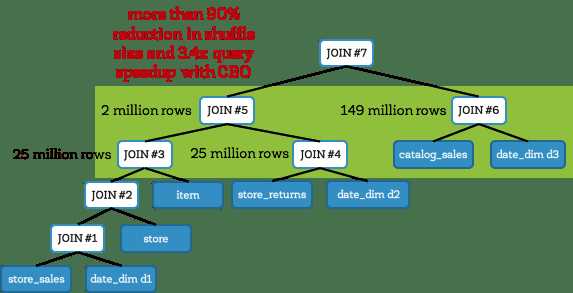
另一方面,用了CBO,Spark创建了优化方案可以减小中间结果(如下)。在该案例中,Spark创建了浓密树而不是左-深度树。在CBO规则下,Spark 先join 的是事实表对应的维度表 (在尝试直接join事实表前)。避免大表join意味着避免了大开销的shuffle。在这次查询中,中间结果大小缩小到原来的1/6(相比之前)。最后,Q25只花了71秒,性能提升了3.4倍。
TPC-DS 查询性能
现在我们对性能提升的原因有了直观感受,我们再看下端到端的TPC-DS查询结果。下表展示了使用CBO或没使用CBO下所有TPC-DS查询花费的:
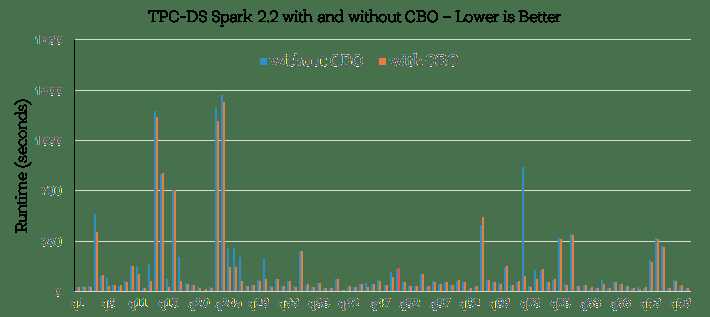
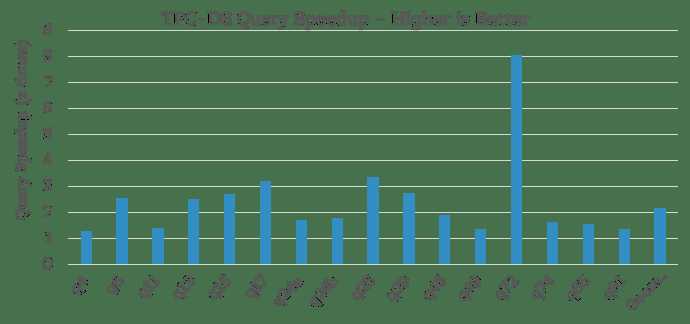
首先,要注意的是一半TPC-DS性能查询没有性能的改变。这是因为使用或没使用CBO的查询计划没有不同 (例如,即使没有CBO, Spark’s Catalyst 优化器的柱状图也可以优化这些查询。剩下的查询性能都有提升,最有意思的其中16个查询,CBO对查询计划进行巨大改变并带来了超过30%的性能提升(如下)总的来说,我们观察的图标说明16个查询大概加速了2.2倍,其中Q72 加速最大,达到了8倍。
结论
回顾前文,该博客展示了Apache Spark 2.2新的CBO不同的高光层面的。我们讨论了统计信息收集框架的细节、过滤和join时的基传播、CBO开启(选择构建方和多路重排序)以及TPC-DS查询性能的提升。
去年,我们针对CBO umbrella JIRA SPARK-16026总共处理了32个子任务,涉及到50多个补丁和7000多行代码。也就是说,在分布式数据库 均衡CBO是非常困难的而这也是向这个方向迈出的一小步。在以后的版本中,我们计划继续往这个方向做下去,继续加入更复杂的统计信息(直方图、总记录数-最小粗略估计、统计信息分区程度,等等)并改进我们的公式。
我们对已经取得的进展感到十分兴奋并希望你们喜欢这些改进。我们希望你们能在Apache Spark 2.2中尝试新的CBO!
延伸阅读
可以查看Spark 2017(峰会) 演讲: Cost Based Optimizer in Spark 2.2
- 原理就是较小的关系更容易放到内存
- <=> 表示‘安全的空值相等’ ,如果两边的结果都是null就返回true,如果只有一边是null就返回false
- P. Griffiths Selinger, M. M. Astrahan, D. D. Chamberlin, R. A. Lorie, T. G. Price, “Access Path Selection in a Relational Database Management System”, Proceedings of ACM SIGMOD conference, 1979
- weight(权值)是调优参数,可以通过配置 spark.sql.cbo.joinReorder.card.weight (默认是0.7)