一、简介
MongoDB是一款强大、灵活、且易于扩展的通用型数据库
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
MongoDB的特点:
1、易用性
MongoDB是由C++编写的,是一个基于分布式文件存储的开源数据库系统,它不是关系型数据库。在高负载的情况下,添加更多的节点,可以保证服务器的性能。
MongoDB是一个面向文档(document-oriented)的数据库,而不是关系型数据库。 不采用关系型主要是为了获得更好得扩展性。当然还有一些其他好处,与关系数据库相比,面向文档的数据库不再有“行“(row)
的概念取而代之的是更为灵活的“文档”(document)模型。通过在文档中嵌入文档和数组,面向文档的方法能够仅使用一条记录
来表现复杂的层级关系,这与现代的面向对象语言的开发者对数据的看法一致。
另外,不再有预定义模式(predefined schema):文档的键(key)和值(value)不再是固定的类型和大小
。由于没有固定的模式,根据需要添加或删除字段变得更容易了。通常由于开发者能够进行快速迭代,所以开发进程得以加快。
而且,实验更容易进行。开发者能尝试大量的数据模型,从中选一个最好的。
2、易扩展性
应用程序数据集的大小正在以不可思议的速度增长。随着可用带宽的增长和存储器价格的下降,即使是一个小规模的应用程序,需要存储的数据量也可能大的惊人,甚至超出 了很多数据库的处理能力。过去非常罕见的T级数据,现在已经是司空见惯了。 由于需要存储的数据量不断增长,开发者面临一个问题:应该如何扩展数据库,分为纵向扩展和横向扩展,纵向扩展是最省力的做法,但缺点是大型机一般都非常贵,而且 当数据量达到机器的物理极限时,花再多的钱也买不到更强的机器了,此时选择横向扩展更为合适,但横向扩展带来的另外一个问题就是需要管理的机器太多。 MongoDB的设计采用横向扩展。面向文档的数据模型使它能很容易地在多台服务器之间进行数据分割。MongoDB能够自动处理跨集群的数据和负载,自动重新分配文档,
以及将用户的请求路由到正确的机器上。这样,开发者能够集中精力编写应用程序,而不需要考虑如何扩展的问题。
如果一个集群需要更大的容量,只需要向集群添加新服务器,MongoDB就会自动将现有的数据向新服务器传送
3、丰富的功能
MongoDB作为一款通用型数据库,除了能够创建、读取、更新和删除数据之外,还提供了一系列不断扩展的独特功能 #1、索引 支持通用二级索引,允许多种快速查询,且提供唯一索引、复合索引、地理空间索引、全文索引 #2、聚合 支持聚合管道,用户能通过简单的片段创建复杂的集合,并通过数据库自动优化 #3、特殊的集合类型 支持存在时间有限的集合,适用于那些将在某个时刻过期的数据,如会话session。类似地,MongoDB也支持固定大小的集合
,用于保存近期数据,如日志 #4、文件存储 支持一种非常易用的协议,用于存储大文件和文件元数据。MongoDB并不具备一些在关系型数据库中很普遍的功能,
如链接join和复杂的多行事务。省略 这些的功能是处于架构上的考虑,或者说为了得到更好的扩展性,因为在分布式系统中这两个功能难以高效地实现
4、卓越的性能
MongoDB的一个主要目标是提供卓越的性能,这很大程度上决定了MongoDB的设计。MongoDB把尽可能多的内存用作缓存cache,
视图为每次查询自动选择正确的索引。 总之各方面的设计都旨在保持它的高性能 虽然MongoDB非常强大并试图保留关系型数据库的很多特性,但它并不追求具备关系型数据库的所有功能。
只要有可能,数据库服务器就会将处理逻辑交给客户端
。这种精简方式的设计是MongoDB能够实现如此高性能的原因之一
二、MongoDB基础知识
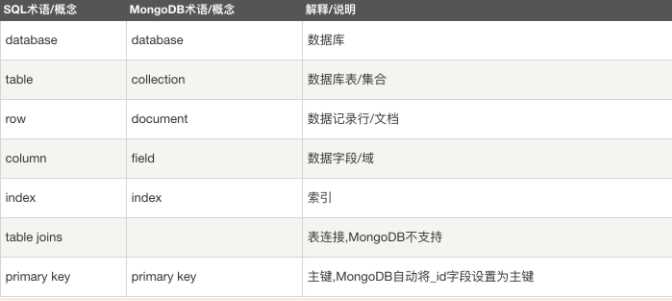
1、文档是MongoDB的核心概念。文档就是键值对的一个有序集{‘msg‘:‘hello‘,‘foo‘:3}。类似于python中的有序字典。
需要注意的是: #1、文档中的键/值对是有序的。 #2、文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。 #3、MongoDB区分类型和大小写。 #4、MongoDB的文档不能有重复的键。 #5、文档中的值可以是多种不同的数据类型,也可以是一个完整的内嵌文档。文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。 文档键命名规范: #1、键不能含有\0 (空字符)。这个字符用来表示键的结尾。 #2、.和$有特别的意义,只有在特定环境下才能使用。 #3、以下划线"_"开头的键是保留的(不是严格要求的)。
2、集合就是一组文档。如果将MongoDB中的一个文档比喻为关系型数据的一行,那么一个集合就是相当于一张表
#1、集合存在于数据库中,通常情况下为了方便管理,不同格式和类型的数据应该插入到不同的集合,但其实集合没有固定的结构,
这意味着我们完全可以把不同格式和类型的数据统统插入一个集合中。 #2、组织子集合的方式就是使用“.”,分隔不同命名空间的子集合。 比如一个具有博客功能的应用可能包含两个集合,分别是blog.posts和blog.authors,这是为了使组织结构更清晰,
这里的blog集合(这个集合甚至不需要存在)跟它的两个子集合没有任何关系。 在MongoDB中,使用子集合来组织数据非常高效,值得推荐 #3、当第一个文档插入时,集合就会被创建。合法的集合名: 集合名不能是空字符串""。 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。 集合名不能以"system."开头,这是为系统集合保留的前缀。 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。
除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
3、数据库:在MongoDB中,多个文档组成集合,多个集合可以组成数据库
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串: #1、不能是空字符串("")。 #2、不得含有‘ ‘(空格)、.、$、/、\和\0 (空字符)。 #3、应全部小写。 #4、最多64字节。 有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。 #1、admin: 从身份认证的角度讲,这是“root”数据库,如果将一个用户添加到admin数据库,这个用户将自动获得所有数据库的权限。再者,一些特定的服务器端命令也只能从admin数据库运行,如列出所有数据库或关闭服务器 #2、local: 这个数据库永远都不可以复制,且一台服务器上的所有本地集合都可以存储在这个数据库中 #3、config: MongoDB用于分片设置时,分片信息会存储在config数据库
4、强调:把数据库名添加到集合名前,得到集合的完全限定名,即命名空间
例如: 如果要使用cms数据库中的blog.posts集合,这个集合的命名空间就是 cms.blog.posts。命名空间的长度不得超过121个字节,且在实际使用中应该小于100个字节

三、安装
1、安装
#1、安装路径为D:\MongoDB,将D:\MongoDB\bin目录加入环境变量
#2、新建目录与文件
D:\MongoDB\data\db
D:\MongoDB\log\mongod.log
#3、新建配置文件mongod.cfg,参考:https://docs.mongodb.com/manual/reference/configuration-options/
systemLog:
destination: file
path: "D:\MongoDB\log\mongod.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "D:\MongoDB\data\db"
net:
bindIp: 0.0.0.0
port: 27017
setParameter:
enableLocalhostAuthBypass: false
#4、制作系统服务
mongod --config "D:\MongoDB\mongod.cfg" --bind_ip 0.0.0.0 --install
或者直接在命令行指定配置
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install
#5、启动\关闭 net start MongoDB net stop MongoDB #6、登录 mongo 链接:http://www.runoob.com/mongodb/mongodb-window-install.html
当没有账号密码登录的时候,默认就是管理员登录。,因为刚刚做系统服务install的时候没有指定
--auth(没有指定则没有权限认证这一说),(相当于mysql跳过授权表启动一样)
2、账号管理
#账号管理:https://docs.mongodb.com/master/tutorial/enable-authentication/ #1、创建有权限的用户
use admin
db.createUser(
{
user: "root", #这个root可以随便写
pwd: "123",
roles: [ { role: "root", db: "admin" } ] #权限,role是root说明是管理员,
}
)
use test
db.createUser(
{
user: "egon",
pwd: "123",
roles: [ { role: "readWrite", db: "test" }, #针对test库有读写权限,操作自己的库有读写权限
{ role: "read", db: "db1" } ] #针对db1库读权限,操作其他库有读权限
}
)
#2、重启数据库 mongod --remove mongod --config "C:\mongodb\mongod.cfg" --bind_ip 0.0.0.0 --install --auth
或者
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath
D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install --auth
#3、登录:注意使用双引号而非单引号 mongo --port 27017 -u "root" -p "123" --authenticationDatabase "admin" 也可以在登录之后用db.auth("账号","密码")登录 mongo use admin db.auth("root","123") #推荐博客:https://www.cnblogs.com/zhoujinyi/p/4610050.html 创建账号密码+开启认证机制
3、命令行shell
#1、mongo 127.0.0.1:27017/config #连接到任何数据库config #2、mongo --nodb #不连接到任何数据库 #3、启动之后,在需要时运行new Mongo(hostname)命令就可以连接到想要的mongod了: > conn=new Mongo(‘127.0.0.1:27017‘) connection to 127.0.0.1:27017 > db=conn.getDB(‘admin‘) admin #4、help查看帮助 #5、mongo时一个简化的JavaScript shell,是可以执行JavaScript脚本的
四、基本数据类型
1、在概念上,MongoDB的文档与Javascript的对象相近,因而可以认为它类似于JSON。JSON(http://www.json.org)是一种简单的数据表示方式:其规范仅用一段文字就能描述清楚(其官网证明了这点),且仅包含六种数据类型。
2、这样有很多好处:易于理解、易于解析、易于记忆。然而从另一方面说,因为只有null、布尔、数字、字符串、数字和对象这几种数据类型,所以JSON的表达能力有一定的局限。
3、虽然JSON具备的这些类型已经具有很强的表现力,但绝大数应用(尤其是在于数据库打交道时)都还需要其他一些重要的类型。例如,JSON没有日期类型,这使得原本容易日期处理变得烦人。另外,JSON只有一种数字类型,无法区分浮点数和整数,更别区分32位和64位了。再者JSON无法表示其他一些通用类型,如正则表达式或函数。
4、MongoDB在保留了JSON基本键/值对特性的基础上,添加了其他一些数据类型。在不同的编程语言下,这些类型的确切表示有些许差异。下面说明了MongoDB支持的其他通用类型,以及如何正在文档中使用它们
5、数据类型
#1、null:用于表示空或不存在的字段 d={‘x‘:null} #2、布尔型:true和false d={‘x‘:true,‘y‘:false} #3、数值 d={‘x‘:3,‘y‘:3.1415926} #4、字符串 d={‘x‘:‘egon‘} #5、日期 d={‘x‘:new Date()} d.x.getHours() #6、正则表达式 d={‘pattern‘:/^egon.*?nb$/i} 正则写在//内,后面的i代表: i 忽略大小写 m 多行匹配模式 x 忽略非转义的空白字符 s 单行匹配模式 #7、数组 d={‘x‘:[1,‘a‘,‘v‘]} #8、内嵌文档 user={‘name‘:‘egon‘,‘addr‘:{‘country‘:‘China‘,‘city‘:‘YT‘}} user.addr.country #9、对象id:是一个12字节的ID,是文档的唯一标识,不可变 d={‘x‘:ObjectId()}
6、_id和ObjectId
MongoDB中存储的文档必须有一个"_id"键。这个键的值可以是任意类型,默认是个ObjectId对象。 在一个集合里,每个文档都有唯一的“_id”,确保集合里每个文档都能被唯一标识。 不同集合"_id"的值可以重复,但同一集合内"_id"的值必须唯一 #1、ObjectId ObjectId是"_id"的默认类型。因为设计MongoDb的初衷就是用作分布式数据库,所以能够在分片环境中生成 唯一的标识符非常重要,而常规的做法:在多个服务器上同步自动增加主键既费时又费力,这就是MongoDB采用 ObjectId的原因。 ObjectId采用12字节的存储空间,是一个由24个十六进制数字组成的字符串 0|1|2|3| 4|5|6| 7|8 9|10|11 时间戳 机器 PID 计数器 如果快速创建多个ObjectId,会发现每次只有最后几位有变化。另外,中间的几位数字也会变化(要是在创建过程中停顿几秒)。 这是ObjectId的创建方式导致的,如上图 时间戳单位为秒,与随后5个字节组合起来,提供了秒级的唯一性。这个4个字节隐藏了文档的创建时间,绝大多数驱动程序都会提供 一个方法,用于从ObjectId中获取这些信息。 因为使用的是当前时间,很多用户担心要对服务器进行时钟同步。其实没必要,因为时间戳的实际值并不重要,只要它总是不停增加就好。 接下来3个字节是所在主机的唯一标识符。通常是机器主机名的散列值。这样就可以保证不同主机生成不同的ObjectId,不产生冲突 接下来连个字节确保了在同一台机器上并发的多个进程产生的ObjectId是唯一的 前9个字节确保了同一秒钟不同机器不同进程产生的ObjectId是唯一的。最后3个字节是一个自动增加的 计数器。确保相同进程的同一秒产生的 ObjectId也是不一样的。 #2、自动生成_id 如果插入文档时没有"_id"键,系统会自帮你创建 一个。可以由MongoDb服务器来做这件事。 但通常会在客户端由驱动程序完成。这一做法非常好地体现了MongoDb的哲学:能交给客户端驱动程序来做的事情就不要交给服务器来做。 这种理念背后的原因是:即便是像MongoDB这样扩展性非常好的数据库,扩展应用层也要比扩展数据库层容易的多。将工作交给客户端做就 减轻了数据库扩展的负担。
五、增删改查操作
1、数据库的增删改
增:use db1 :#有则切换,无则新 增
查:
- show dbs #查看所有数据库
- db #查看当前库
删:db.dropDatabase()
#不会就用help
2、集合(表)的增删改
增:
- db.user.info #user.info表
- db.user #user表
- db.user.auth ##user.auth表
当第一个文档插入时,集合就会被创建
> use database1
switched to db database1
> db.table1.insert({‘a‘:1})
WriteResult({ "nInserted" : 1 })
> db.table2.insert({‘b‘:2})
WriteResult({ "nInserted" : 1 })
查:
- show collections
- show tables #这两个是一样的
#只要是空不显示
删:
- db.user.info.help() #查看帮助
- db.user.info.drop()
3、文档(记录)的增删改
增
#单条插入与多条插入 #1、没有指定_id则默认ObjectId,_id不能重复,且在插入后不可变 #2、插入单条 user0={ "name":"egon", "age":10, ‘hobbies‘:[‘music‘,‘read‘,‘dancing‘], ‘addr‘:{ ‘country‘:‘China‘, ‘city‘:‘BJ‘ } } db.test.insert(user0) db.test.find() #3、插入多条 user1={ "_id":1, "name":"alex", "age":10, ‘hobbies‘:[‘music‘,‘read‘,‘dancing‘], ‘addr‘:{ ‘country‘:‘China‘, ‘city‘:‘weifang‘ } } user2={ "_id":2, "name":"wupeiqi", "age":20, ‘hobbies‘:[‘music‘,‘read‘,‘run‘], ‘addr‘:{ ‘country‘:‘China‘, ‘city‘:‘hebei‘ } } user3={ "_id":3, "name":"yuanhao", "age":30, ‘hobbies‘:[‘music‘,‘drink‘], ‘addr‘:{ ‘country‘:‘China‘, ‘city‘:‘heibei‘ } } user4={ "_id":4, "name":"jingliyang", "age":40, ‘hobbies‘:[‘music‘,‘read‘,‘dancing‘,‘tea‘], ‘addr‘:{ ‘country‘:‘China‘, ‘city‘:‘BJ‘ } } user5={ "_id":5, "name":"jinxin", "age":50, ‘hobbies‘:[‘music‘,‘read‘,], ‘addr‘:{ ‘country‘:‘China‘, ‘city‘:‘henan‘ } } db.user.insertMany([user1,user2,user3,user4,user5])
- db.user.insert({"_id":1,"name":"haiyan"})
- db.user.info.insert({"x":new Date(),"pattern":"/^egon.*?$/i","z":Object()})
- 单条插入insert(user0)
- 多条插入:如上insertMany([user1,user2,user3,user4,])
#如果user0没写id,也可以吧user0插进去,因为没有指定id,
#会生成一条新的,只要id不冲突就能插进去
db.t1.insert({"_id":1,"a":1,"b":2,"c":3})
#有相同的id则覆盖,无相同的id则新增,可以指定_id,也可以不指定id,默认是Obiectid()
db.t1.save({"_id":1,"z":6}) #有了就把原来的覆盖了
db.t1.save({"_id":2,"z":6}) #如果没有id,就会新增一个
#如果用insert会告诉你有重复的key了,但是用save就不一样了,会把"a":1,"b":2,"c":3直接给覆盖了
查
#比较运算
# SQL:=,!=,>,<,>=,<=
# MongoDB:{key:value}代表什么等于什么,"$ne","$gt","$lt","gte","lte",其中"$ne"能用于所有数据类型
- db.user.info.find() #查看所有的记录
- db.user.info.find().pertty #美化
#注意
#这里面会自动创建一个_id字段,默认就是创建的Object类型的
#你创建的z字段也是一样的,推荐还是用人家默认的
#一模一样的id是不让插的,
#自带Obiect是为了让mongodb能够比较好的实现分布式的功能来提供依据的
- db.t1.findOne() #查一条
比较运算:=,!=,>,<,<=,>=
#1、select * from db1.usesr where id=3
db.user.find({"_id":3})
#1、select * from db1.usesr where id!=3
db.user.find({"_id":{"$ne":3}})
,
#1、select * from db1.usesr where id<3
db.user.find({"_id":{"$lt":3}})
#1、select * from db1.usesr where id>3
db.user.find({"_id":{"$gt":3}})
#1、select * from db1.usesr where id>=3
db.user.find({"_id":{"$gte":3}})
#1、select * from db1.usesr where id<=3
db.user.find({"_id":{"$lte":3}})
#逻辑运算:$and,$or,$not
#1 select * from db1.user where id >=3 and id <=4;
db.user.find({"_id":{"$gte":3,"$lte":4}})
#2 select * from db1.user where id >=3 and id <=4 and age >=40;
db.user.find({
"_id":{"$gte":3,"$lte":4},
"age":{"$gte":40} #结束就不要加逗号了
})
或者
db.user.find({"$and":[
{"_id":{"$gte":3,"$lte":4}}, #一个字典就是一个条件
{"age":{"$gte":40}}
]})
#3 select * from db1.user where id >=0 and id <=1 or id >=4 or name = "yuanhao";
db.user.find({"$or":[
{"_id":{"$lte":1,"$gte":0}},
{"_id":{"$gte":4}},
{"name":"yuanhao"}
]})
#4 select * from db1.user where id % 2 = 1; #奇数
db.user.find({"_id":{"$mod":[2,1]}}) #取模运算,id对2取模
#取反,偶数
db.user.find({
"_id":{"$not":{"$mod":[2,1]}}
})
#成员运算
# SQL:in,not in
# MongoDB:"$in","$nin"
#1、select * from db1.user where age in (20,30,31);
db.user.find({"age":{"$in":[20,30,31]}})
#2、select * from db1.user where name not in (‘huahua‘,‘xxx‘);
db.user.find({"name":{"$nin":[‘hauhua‘,‘xxx‘]}})
#正则匹配
select * from db1.user where name regexp "^jin.*?(g|n)$";
db.user.find({
"name":/^jin.*?(g|n)$/i
})
#查看指定字段
select name,age from db1.user where name regexp "^jin.*?(g|n)$"; #jin开头匹配到g或者n结尾的
db.user.find({
"name":/^jin.*?(g|n)$/i #//i,i代表忽略大小写
},
{ #显示匹配成功的字段
"_id":0, #不要
"name":1, #要
"age":1 #要
}
)
排序、分页、获取数量待补充……
#其他
#1、{‘key‘:null} 匹配key的值为null或者没有这个key
db.t2.insert({‘a‘:10,‘b‘:111})
db.t2.insert({‘a‘:20})
db.t2.insert({‘b‘:null})
> db.t2.find({"b":null})
{ "_id" : ObjectId("5a5cc2a7c1b4645aad959e5a"), "a" : 20 }
{ "_id" : ObjectId("5a5cc2a8c1b4645aad959e5b"), "b" : null }
#2、查找所有
db.user.find() #等同于db.user.find({})
db.user.find().pretty()
#3、查找一个,与find用法一致,只是只取匹配成功的第一个
db.user.findOne({"_id":{"$gt":3}})
#查询数组相关
#查询数组相关
db.user.find({ #查看有跳舞爱好的这些人,有就可以
"hobbies":"dancing"
})
db.user.find({ #既有喝茶爱好,又有跳舞爱好
"hobbies":{"$all":["dancing","tea"]}
})
db.user.find({ #第三个爱好是跳舞的
"hobbies.2":"dancing"
})
db.user.find( #查询所有人的后两个爱好
{}, #空就代表匹配到所有人了
{
"_id":0,
"name":0,
"age":0,
"addr":0,
"hobbies":{"$slice":-2}, #切最后一个到最后二个
}
)
db.user.find( #查询所有人的第一个和第二个爱好
{}, #空就代表匹配到所有人了
{
"_id":0,
"name":0,
"age":0,
"addr":0,
"hobbies":{"$slice":[1,2]}, #切第一个到第二个
}
)
db.user.find( #找前两个爱好
{},
{
"_id":0,
"name":0,
"age":0,
"addr":0,
"hobbies":{"$slice":2},
}
)
db.user.find( #找出国家是中国的
{
"addr.country":"China"
}
)
改
#update语法介绍
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:对比update db1.t1 set name=‘EGON‘,sex=‘Male‘ where name=‘egon‘ and age=18;
query : 相当于where条件。
update : update的对象和一些更新的操作符(如$,$inc...等,相当于set后面的
upsert : 可选,默认为false,代表如果不存在update的记录不更新也不插入,设置为true代表插入。
multi : 可选,默认为false,代表只更新找到的第一条记录,设为true,代表更新找到的全部记录。
writeConcern :可选,抛出异常的级别。
更新操作是不可分割的:若两个更新同时发送,先到达服务器的先执行,然后执行另外一个,不会破坏文档。
#覆盖式
#注意:除非是删除,否则_id是始终不会变的
#1、覆盖式:
db.user.update({‘age‘:20},{"name":"Wxx","hobbies_count":3})
是用{"_id":2,"name":"Wxx","hobbies_count":3}覆盖原来的记录
#2、一种最简单的更新就是用一个新的文档完全替换匹配的文档。这适用于大规模式迁移的情况。例如
var obj=db.user.findOne({"_id":2})
obj.username=obj.name+‘SB‘
obj.hobbies_count++
delete obj.age
db.user.update({"_id":2},obj)
#设置:$set
通常文档只会有一部分需要更新。可以使用原子性的更新修改器,指定对文档中的某些字段进行更新。
更新修改器是种特殊的键,用来指定复杂的更新操作,比如修改、增加后者删除
#1、update db1.user set name="WXX" where id = 2
db.user.update({‘_id‘:2},{"$set":{"name":"WXX",}})
#2、没有匹配成功则新增一条{"upsert":true}
db.user.update({‘_id‘:6},{"$set":{"name":"egon","age":18}},{"upsert":true})
#3、默认只改匹配成功的第一条,{"multi":改多条}
db.user.update({‘_id‘:{"$gt":4}},{"$set":{"age":28}})
db.user.update({‘_id‘:{"$gt":4}},{"$set":{"age":38}},{"multi":true})
#4、修改内嵌文档,把名字为alex的人所在的地址国家改成Japan
db.user.update({‘name‘:"alex"},{"$set":{"addr.country":"Japan"}})
#5、把名字为alex的人的地2个爱好改成piao
db.user.update({‘name‘:"alex"},{"$set":{"hobbies.1":"piao"}})
#6、删除alex的爱好,$unset
db.user.update({‘name‘:"alex"},{"$unset":{"hobbies":""}})
#1、删除多个中的第一个
db.user.deleteOne({ ‘age‘: 8 })
#2、删除国家为China的全部
db.user.deleteMany( {‘addr.country‘: ‘China‘} )
#3、删除全部
db.user.deleteMany({})
#增加和减少:$inc
#1、所有人年龄增加一岁
db.user.update({},
{
"$inc":{"age":1}
},
{
"multi":true
}
)
#2、所有人年龄减少5岁
db.user.update({},
{
"$inc":{"age":-5}
},
{
"multi":true
}
)
#添加删除数组内元素:$push,$pop,$pull
往数组内添加元素:$push
#1、为名字为yuanhao的人添加一个爱好read
db.user.update({"name":"yuanhao"},{"$push":{"hobbies":"read"}})
#2、为名字为yuanhao的人一次添加多个爱好tea,dancing
db.user.update({"name":"yuanhao"},{"$push":{
"hobbies":{"$each":["tea","dancing"]}
}})
按照位置且只能从开头或结尾删除元素:$pop
#3、{"$pop":{"key":1}} 从数组末尾删除一个元素
db.user.update({"name":"yuanhao"},{"$pop":{
"hobbies":1}
})
#4、{"$pop":{"key":-1}} 从头部删除
db.user.update({"name":"yuanhao"},{"$pop":{
"hobbies":-1}
})
#5、按照条件删除元素,:"$pull" 把符合条件的统统删掉,而$pop只能从两端删
db.user.update({‘addr.country‘:"China"},{"$pull":{
"hobbies":"read"}
},
{
"multi":true
}
)
#避免添加重复:"$addToSet"
db.urls.insert({"_id":1,"urls":[]})
db.urls.update({"_id":1},{"$addToSet":{"urls":‘http://www.baidu.com‘}})
db.urls.update({"_id":1},{"$addToSet":{"urls":‘http://www.baidu.com‘}})
db.urls.update({"_id":1},{"$addToSet":{"urls":‘http://www.baidu.com‘}})
db.urls.update({"_id":1},{
"$addToSet":{
"urls":{
"$each":[
‘http://www.baidu.com‘,
‘http://www.baidu.com‘,
‘http://www.xxxx.com‘
]
}
}
}
)
#1、了解:限制大小"$slice",只留最后n个
db.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",‘music‘,‘dancing‘],
"$slice":-2
}
}
})
#2、了解:排序The $sort element value must be either 1 or -1"
db.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",‘music‘,‘dancing‘],
"$slice":-1,
"$sort":-1
}
}
})
#注意:不能只将"$slice"或者"$sort"与"$push"配合使用,且必须使用"$eah"
聚合
如果你有数据存储在MongoDB中,你想做的可能就不仅仅是将数据提取出来那么简单了;你可能希望对数据进行分析并加以利用。MongoDB提供了以下聚合工具: #1、聚合框架 #2、MapReduce(详见MongoDB权威指南) #3、几个简单聚合命令:count、distinct和group。(详见MongoDB权威指南) #聚合框架: 可以使用多个构件创建一个管道,上一个构件的结果传给下一个构件。 这些构件包括(括号内为构件对应的操作符):筛选($match)、投射($project)、分组($group)、排序($sort)、限制($limit)、跳过($skip) 不同的管道操作符可以任意组合,重复使用
# 准备数据
from pymongo import MongoClient
import datetime
client=MongoClient(‘mongodb://root:123@localhost:27017‘)
table=client[‘db1‘][‘emp‘]
# table.drop()
l=[
(‘egon‘,‘male‘,18,‘20170301‘,‘老男孩驻沙河办事处外交大使‘,7300.33,401,1), #以下是教学部
(‘alex‘,‘male‘,78,‘20150302‘,‘teacher‘,1000000.31,401,1),
(‘wupeiqi‘,‘male‘,81,‘20130305‘,‘teacher‘,8300,401,1),
(‘yuanhao‘,‘male‘,73,‘20140701‘,‘teacher‘,3500,401,1),
(‘liwenzhou‘,‘male‘,28,‘20121101‘,‘teacher‘,2100,401,1),
(‘jingliyang‘,‘female‘,18,‘20110211‘,‘teacher‘,9000,401,1),
(‘jinxin‘,‘male‘,18,‘19000301‘,‘teacher‘,30000,401,1),
(‘成龙‘,‘male‘,48,‘20101111‘,‘teacher‘,10000,401,1),
(‘歪歪‘,‘female‘,48,‘20150311‘,‘sale‘,3000.13,402,2),#以下是销售部门
(‘丫丫‘,‘female‘,38,‘20101101‘,‘sale‘,2000.35,402,2),
(‘丁丁‘,‘female‘,18,‘20110312‘,‘sale‘,1000.37,402,2),
(‘星星‘,‘female‘,18,‘20160513‘,‘sale‘,3000.29,402,2),
(‘格格‘,‘female‘,28,‘20170127‘,‘sale‘,4000.33,402,2),
(‘张野‘,‘male‘,28,‘20160311‘,‘operation‘,10000.13,403,3), #以下是运营部门
(‘程咬金‘,‘male‘,18,‘19970312‘,‘operation‘,20000,403,3),
(‘程咬银‘,‘female‘,18,‘20130311‘,‘operation‘,19000,403,3),
(‘程咬铜‘,‘male‘,18,‘20150411‘,‘operation‘,18000,403,3),
(‘程咬铁‘,‘female‘,18,‘20140512‘,‘operation‘,17000,403,3)
]
for n,item in enumerate(l):
d={
"_id":n,
‘name‘:item[0],
‘sex‘:item[1],
‘age‘:item[2],
‘hire_date‘:datetime.datetime.strptime(item[3],‘%Y%m%d‘),
‘post‘:item[4],
‘salary‘:item[5]
}
table.save(d)
#筛选:$match
{"$match":{"字段":"条件"}},可以使用任何常用查询操作符$gt,$lt,$in等
#例1、select * from db1.emp where post=‘teacher‘;
db.emp.aggregate({"$match":{"post":"teacher"}})
#例2、select * from db1.emp where id > 3 group by post;
db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",‘avg_salary‘:{"$avg":"$salary"}}}
)
#例3、select * from db1.emp where id > 3 group by post having avg(salary) > 10000;
db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",‘avg_salary‘:{"$avg":"$salary"}}},
{"$match":{"avg_salary":{"$gt":10000}}}
)
#投射:$project
{"$project":{"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表达式"}}
#1、select name,post,(age+1) as new_age from db1.emp;
db.emp.aggregate(
{"$project":{
"name":1,
"post":1,
"new_age":{"$add":["$age",1]}
}
})
#2、表达式之数学表达式
{"$add":[expr1,expr2,...,exprN]} #相加
{"$subtract":[expr1,expr2]} #第一个减第二个
{"$multiply":[expr1,expr2,...,exprN]} #相乘
{"$divide":[expr1,expr2]} #第一个表达式除以第二个表达式的商作为结果
{"$mod":[expr1,expr2]} #第一个表达式除以第二个表达式得到的余数作为结果
#3、表达式之日期表达式:$year,$month,$week,$dayOfMonth,$dayOfWeek,$dayOfYear,$hour,$minute,$second
#例如:select name,date_format("%Y") as hire_year from db1.emp
db.emp.aggregate(
{"$project":{"name":1,"hire_year":{"$year":"$hire_date"}}}
)
#例如查看每个员工的工作多长时间
db.emp.aggregate(
{"$project":{"name":1,"hire_period":{
"$subtract":[
{"$year":new Date()},
{"$year":"$hire_date"}
]
}}}
)
#4、字符串表达式
{"$substr":[字符串/$值为字符串的字段名,起始位置,截取几个字节]}
{"$concat":[expr1,expr2,...,exprN]} #指定的表达式或字符串连接在一起返回,只支持字符串拼接
{"$toLower":expr}
{"$toUpper":expr}
db.emp.aggregate( {"$project":{"NAME":{"$toUpper":"$name"}}})
#5、逻辑表达式
$and
$or
$not
其他见Mongodb权威指南
#分组:$group
{"$group":{"_id":分组字段,"新的字段名":聚合操作符}}
#1、将分组字段传给$group函数的_id字段即可
{"$group":{"_id":"$sex"}} #按照性别分组
{"$group":{"_id":"$post"}} #按照职位分组
{"$group":{"_id":{"state":"$state","city":"$city"}}} #按照多个字段分组,比如按照州市分组
#2、分组后聚合得结果,类似于sql中聚合函数的聚合操作符:$sum、$avg、$max、$min、$first、$last
#例1:select post,max(salary) from db1.emp group by post;
db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"}}})
#例2:去每个部门最大薪资与最低薪资
db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}})
#例3:如果字段是排序后的,那么$first,$last会很有用,比用$max和$min效率高
db.emp.aggregate({"$group":{"_id":"$post","first_id":{"$first":"$_id"}}})
#例4:求每个部门的总工资
db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":"$salary"}}})
#例5:求每个部门的人数
db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}})
#3、数组操作符
{"$addToSet":expr}:不重复
{"$push":expr}:重复
#例:查询岗位名以及各岗位内的员工姓名:select post,group_concat(name) from db1.emp group by post;
db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}})
db.emp.aggregate({"$group":{"_id":"$post","names":{"$addToSet":"$name"}}})
#排序:$sort、限制:$limit、跳过:$skip
{"$sort":{"字段名":1,"字段名":-1}} #1升序,-1降序
{"$limit":n}
{"$skip":n} #跳过多少个文档
#例1、取平均工资最高的前两个部门
db.emp.aggregate(
{
"$group":{"_id":"$post","平均工资":{"$avg":"$salary"}}
},
{
"$sort":{"平均工资":-1}
},
{
"$limit":2
}
)
#例2、
db.emp.aggregate(
{
"$group":{"_id":"$post","平均工资":{"$avg":"$salary"}}
},
{
"$sort":{"平均工资":-1}
},
{
"$limit":2
},
{
"$skip":1
}
)
#随机选取n个:$sample
#集合users包含的文档如下
{ "_id" : 1, "name" : "dave123", "q1" : true, "q2" : true }
{ "_id" : 2, "name" : "dave2", "q1" : false, "q2" : false }
{ "_id" : 3, "name" : "ahn", "q1" : true, "q2" : true }
{ "_id" : 4, "name" : "li", "q1" : true, "q2" : false }
{ "_id" : 5, "name" : "annT", "q1" : false, "q2" : true }
{ "_id" : 6, "name" : "li", "q1" : true, "q2" : true }
{ "_id" : 7, "name" : "ty", "q1" : false, "q2" : true }
#下述操作时从users集合中随机选取3个文档
db.users.aggregate(
[ { $sample: { size: 3 } } ]
)
练习题:
1. 查询岗位名以及各岗位内的员工姓名 2. 查询岗位名以及各岗位内包含的员工个数 3. 查询公司内男员工和女员工的个数 4. 查询岗位名以及各岗位的平均薪资、最高薪资、最低薪资 5. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资 6. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数 7. 查询各岗位平均薪资大于10000的岗位名、平均工资 8. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资 9. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序 10. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列 11. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列,取前1个
#参考答案
1. 查询岗位名以及各岗位内的员工姓名
db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}})
2. 查询岗位名以及各岗位内包含的员工个数
db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}})
3. 查询公司内男员工和女员工的个数
db.emp.aggregate({"$group":{"_id":"$sex","count":{"$sum":1}}})
4. 查询岗位名以及各岗位的平均薪资、最高薪资、最低薪资
db.emp.aggregate({"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"},"max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}})
5. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
db.emp.aggregate({"$group":{"_id":"$sex","avg_salary":{"$avg":"$salary"}}})
6. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数
db.emp.aggregate(
{
"$group":{"_id":"$post","count":{"$sum":1},"names":{"$push":"$name"}}
},
{"$match":{"count":{"$lt":2}}},
{"$project":{"_id":0,"names":1,"count":1}}
)
7. 查询各岗位平均薪资大于10000的岗位名、平均工资
db.emp.aggregate(
{
"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}
},
{"$match":{"avg_salary":{"$gt":10000}}},
{"$project":{"_id":1,"avg_salary":1}}
)
8. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
db.emp.aggregate(
{
"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}
},
{"$match":{"avg_salary":{"$gt":10000,"$lt":20000}}},
{"$project":{"_id":1,"avg_salary":1}}
)
9. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序
db.emp.aggregate(
{"$sort":{"age":1,"hire_date":-1}}
)
10. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列
db.emp.aggregate(
{
"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}
},
{"$match":{"avg_salary":{"$gt":10000}}},
{"$sort":{"avg_salary":1}}
)
11. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列,取前1个
db.emp.aggregate(
{
"$group":{"_id":"$post","avg_salary":{"$avg":"$salary"}}
},
{"$match":{"avg_salary":{"$gt":10000}}},
{"$sort":{"avg_salary":-1}},
{"$limit":1},
{"$project":{"date":new Date,"平均工资":"$avg_salary","_id":0}}
)
六、可视化工具
七、pymongo
官网:http://api.mongodb.com/python/current/tutorial.html
from pymongo import MongoClient
#1、链接
client=MongoClient(‘mongodb://root:123@localhost:27017/‘)
# client = MongoClient(‘localhost‘, 27017)
#2、use 数据库
db=client[‘db2‘] #等同于:client.db1
#3、查看库下所有的集合
print(db.collection_names(include_system_collections=False))
#4、创建集合
table_user=db[‘userinfo‘] #等同于:db.user
#5、插入文档
import datetime
user0={
"_id":1,
"name":"egon",
"birth":datetime.datetime.now(),
"age":10,
‘hobbies‘:[‘music‘,‘read‘,‘dancing‘],
‘addr‘:{
‘country‘:‘China‘,
‘city‘:‘BJ‘
}
}
user1={
"_id":2,
"name":"alex",
"birth":datetime.datetime.now(),
"age":10,
‘hobbies‘:[‘music‘,‘read‘,‘dancing‘],
‘addr‘:{
‘country‘:‘China‘,
‘city‘:‘weifang‘
}
}
# res=table_user.insert_many([user0,user1]).inserted_ids
# print(res)
# print(table_user.count())
#6、查找
# from pprint import pprint#格式化细
# pprint(table_user.find_one())
# for item in table_user.find():
# pprint(item)
# print(table_user.find_one({"_id":{"$gte":1},"name":‘egon‘}))
#7、更新
table_user.update({‘_id‘:1},{‘name‘:‘EGON‘})
#8、传入新的文档替换旧的文档
table_user.save(
{
"_id":2,
"name":‘egon_xxx‘
}
)