下面,我再写一个例子,加强对正则表达式的理解。还是回到我们下载的那个二手房网页,在实际中,我们并不需要整个网页的内容,因此我们来改进这个程序,对网页上的信息进行过滤筛选,并保存我们需要的内容。打开chrome浏览器,右键检查。
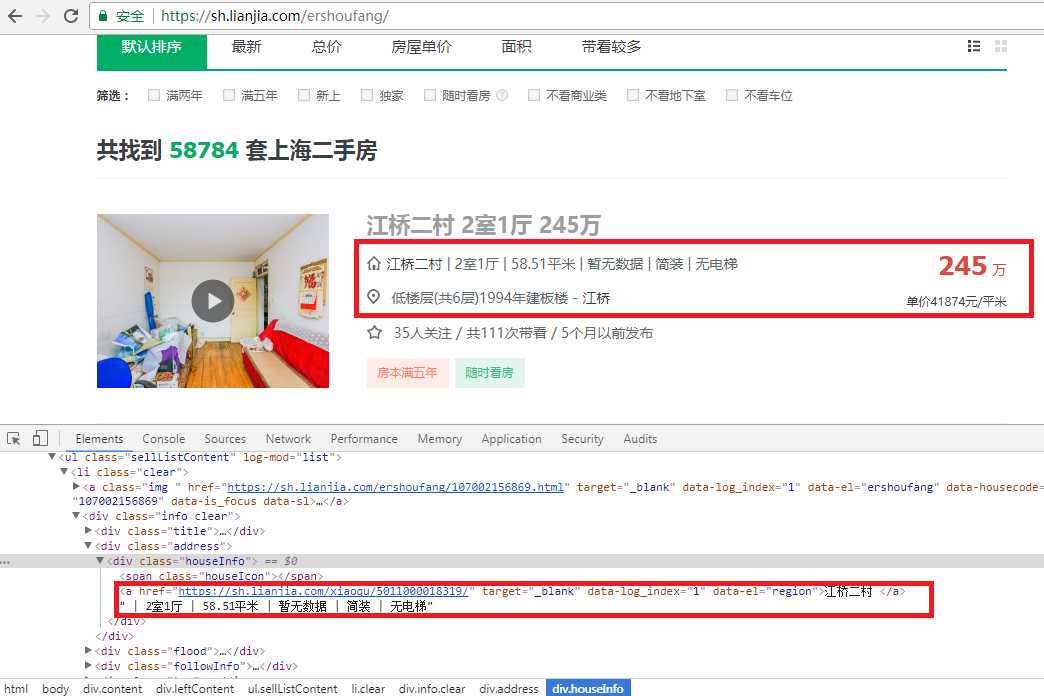
在网页源码中找到了我们所需要的内容。为了调试程序,我们可以在 http://tool.oschina.net/regex/ 上测试编译好的正则表达式。
对于 houseinfo:pattern=r‘ data-el="region">(.+?)</div>‘
对于 price:pattern=r‘<div class="totalPrice"><span>\d+</span>万‘
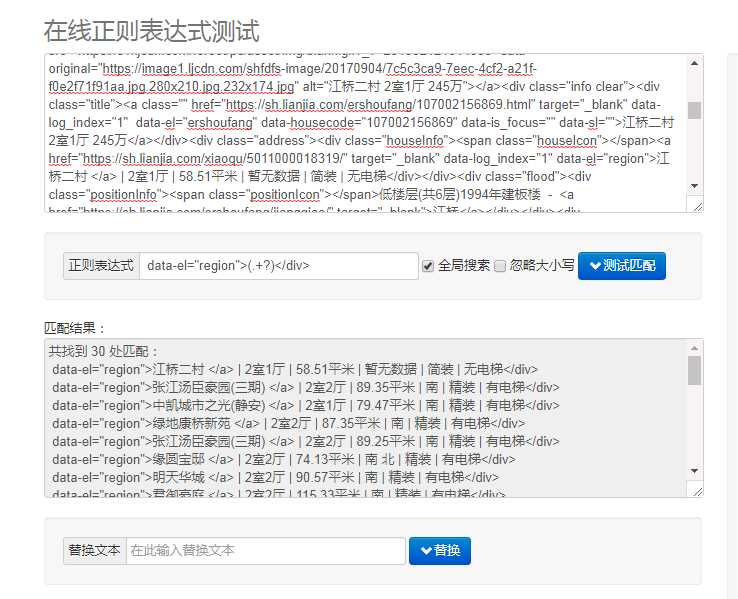
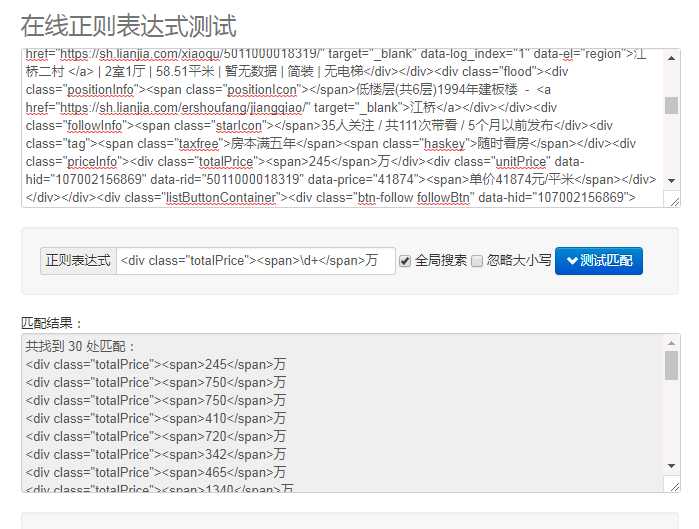
我们用正则提取的内容是有冗余部分的,可以联想到用切片的方法处理提取内容。上源码:
1 from urllib import request 2 import re 3 4 def HTMLspider(url,startPage,endPage): 5 6 #作用:负责处理URL,分配每个URL去发送请求 7 8 for page in range(startPage,endPage+1): 9 filename="第" + str(page) + "页.html" 10 11 #组合为完整的url 12 fullurl=url + str(page) 13 14 #调用loadPage()发送请求,获取HTML页面 15 html=loadPage(fullurl,filename) 16 17 18 19 def loadPage(fullurl,filename): 20 #获取页面 21 response=request.urlopen(fullurl) 22 Html=response.read().decode(‘utf-8‘) 23 #print(Html) 24 25 #正则编译,获取房产信息 26 info_pattern=r‘data-el="region">(.+?)</div>‘ 27 info_list=re.findall(info_pattern,Html) 28 #print(info_list) 29 #正则编译,获取房产价格 30 price_pattern=r‘<div class="totalPrice"><span>\d+</span>万‘ 31 price_list=re.findall(price_pattern,Html) 32 #print(price_list) 33 34 writePage(price_list,info_list,filename) 35 36 37 38 39 def writePage(price_list,info_list,filename): 40 """ 41 将服务器的响应文件保存到本地磁盘 42 """ 43 list1=[] 44 list2=[] 45 for i in price_list: 46 i=‘-------------->>>>>Price:‘ + i[30:-8] + ‘万‘ 47 list1.append(i) 48 #print(i[30:-8]) 49 for j in info_list: 50 j=j.replace(‘</a>‘,‘ ‘*10) 51 j=j[:10] + ‘ ‘*5 + ‘---------->>>>>Deatil information: ‘ + j[10:] + ‘ ‘*5 52 list2.append(j) 53 #print(j) 54 55 for each in zip(list2,list1): 56 print(each) 57 58 59 60 print("正在存储"+filename) 61 #with open(filename,‘wb‘) as f: 62 # f.write(html) 63 64 65 print("--"*30) 66 67 68 if __name__=="__main__": 69 #输入需要下载的起始页和终止页,注意转换成int类型 70 startPage=int(input("请输入起始页:")) 71 endPage=int(input("请输入终止页:")) 72 73 url="https://sh.lianjia.com/ershoufang/" 74 75 HTMLspider(url,startPage,endPage) 76 77 print("下载完成!")
这是程序运行后的结果。我只是将其打印在终端,也可以使用json.dumps(),将爬取到的内容保存到本地中。
实际上这种数据提取还有其他方法,这将在以后会讲到。