很多材料上面讲道“引入Soft Margin的原因是因为数据线性不可分”,个人认为有些错误,其实再难以被分解的数据,如果我们用很复杂的弯弯绕曲线去做,还是可以被分解,并且映射到高维空间后认为其线性可分。但如果我们细细思考,其实很多算法都有一样的索求:寻求一种之于“最大限度拟合训练集”and“获得更好归纳能力”的平横,也就是所谓的Overfitting and Underfitting。也像人的性格,太过纠结细节或者神经太过大条,都难以和人相处愉快。那让我们的训练集的数据,必须要用很复杂的曲线才可以分割时,我们引入soft margin的概念。
在未引入Soft Margin的SVM中,我们希望每个训练集中的数据点至少满足如下条件,即距离Margin的函数距离大于0,也即距离Hyperplane的函数距离大于1
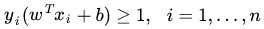
而考虑到,如果有部分outliers点的函数距离小于我们的期望值了,该偏离为ξ,那么这些点满足的条件是:
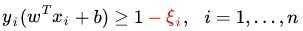
那么,我们把之前的优化问题如下:
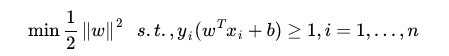
转化为了:
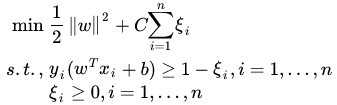
也就是说,一方面我们需要优化ω,使得margin=1/|| ω||值达到最大化,另一方面我们选择的 ω又要使得outliers的偏离值之和最小,在二者之间寻求一种平衡。C是平衡系数,用于调整两部分调整项之间的权重。该优化的拉格朗日函数为:
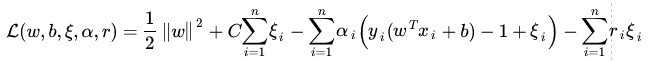
经过求对偶,利用KKT条件:
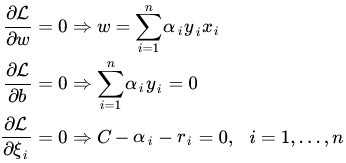
带回到原L函数中,ξ的系数会变成C-α-r=0,因而被消去,所以经过推导,Dual问题变为:
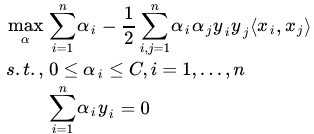
可以看到,形式几乎和原问题一样,知识在α的条件上加了个上限C。