1、前言
我从事Linux系统下网络开发将近4年了,经常还是遇到一些问题,只是知其然而不知其所以然,有时候和其他人交流,搞得非常尴尬。如今计算机都是多核了,网络编程框架也逐步丰富多了,我所知道的有多进程、多线程、异步事件驱动常用的三种模型。最经典的模型就是Nginx中所用的Master-Worker多进程异步驱动模型。今天和大家一起讨论一下网络开发中遇到的“惊群”现象。之前只是听说过这个现象,网上查资料也了解了基本概念,在实际的工作中还真没有遇到过。今天周末,结合自己的理解和网上的资料,彻底将“惊群”弄明白。需要弄清楚如下几个问题:
(1)什么是“惊群”,会产生什么问题?
(2)“惊群”的现象怎么用代码模拟出来?
(3)如何处理“惊群”问题,处理“惊群”后的现象又是怎么样呢?
2、何为惊群
如今网络编程中经常用到多进程或多线程模型,大概的思路是父进程创建socket,bind、listen后,通过fork创建多个子进程,每个子进程继承了父进程的socket,调用accpet开始监听等待网络连接。这个时候有多个进程同时等待网络的连接事件,当这个事件发生时,这些进程被同时唤醒,就是“惊群”。这样会导致什么问题呢?我们知道进程被唤醒,需要进行内核重新调度,这样每个进程同时去响应这一个事件,而最终只有一个进程能处理事件成功,其他的进程在处理该事件失败后重新休眠或其他。网络模型如下图所示:
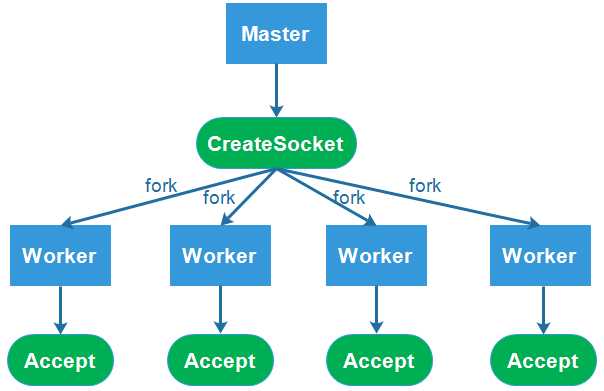
简而言之,惊群现象(thundering herd)就是当多个进程和线程在同时阻塞等待同一个事件时,如果这个事件发生,会唤醒所有的进程,但最终只可能有一个进程/线程对该事件进行处理,其他进程/线程会在失败后重新休眠,这种性能浪费就是惊群。
3、编码模拟“惊群”现象
我们已经知道了“惊群”是怎么回事,那么就按照上面的图编码实现看一下效果。我尝试使用多进程模型,创建一个父进程绑定一个端口监听socket,然后fork出多个子进程,子进程们开始循环处理(比如accept)这个socket。测试代码如下所示:

1 #include <stdio.h>
2 #include <unistd.h>
3 #include <sys/types.h>
4 #include <sys/socket.h>
5 #include <netinet/in.h>
6 #include <arpa/inet.h>
7 #include <assert.h>
8 #include <sys/wait.h>
9 #include <string.h>
10 #include <errno.h>
11
12 #define IP "127.0.0.1"
13 #define PORT 8888
14 #define WORKER 4
15
16 int worker(int listenfd, int i)
17 {
18 while (1) {
19 printf("I am worker %d, begin to accept connection.\n", i);
20 struct sockaddr_in client_addr;
21 socklen_t client_addrlen = sizeof( client_addr );
22 int connfd = accept( listenfd, ( struct sockaddr* )&client_addr, &client_addrlen );
23 if (connfd != -1) {
24 printf("worker %d accept a connection success.\t", i);
25 printf("ip :%s\t",inet_ntoa(client_addr.sin_addr));
26 printf("port: %d \n",client_addr.sin_port);
27 } else {
28 printf("worker %d accept a connection failed,error:%s", i, strerror(errno));
close(connfd);
29 }
30 }
31 return 0;
32 }
33
34 int main()
35 {
36 int i = 0;
37 struct sockaddr_in address;
38 bzero(&address, sizeof(address));
39 address.sin_family = AF_INET;
40 inet_pton( AF_INET, IP, &address.sin_addr);
41 address.sin_port = htons(PORT);
42 int listenfd = socket(PF_INET, SOCK_STREAM, 0);
43 assert(listenfd >= 0);
44
45 int ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
46 assert(ret != -1);
47
48 ret = listen(listenfd, 5);
49 assert(ret != -1);
50
51 for (i = 0; i < WORKER; i++) {
52 printf("Create worker %d\n", i+1);
53 pid_t pid = fork();
54 /*child process */
55 if (pid == 0) {
56 worker(listenfd, i);
57 }
58
59 if (pid < 0) {
60 printf("fork error");
61 }
62 }
63
64 /*wait child process*/
65 int status;
66 wait(&status);
67 return 0;
68 }
编译执行,在本机上使用telnet 127.0.0.1 8888测试,结果如下所示:
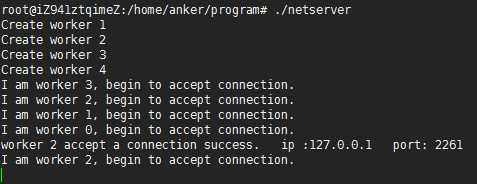
按照“惊群"现象,期望结果应该是4个子进程都会accpet到请求,其中只有一个成功,另外三个失败的情况。而实际的结果显示,父进程开始创建4个子进程,每个子进程开始等待accept连接。当telnet连接来的时候,只有worker2 子进程accpet到请求,而其他的三个进程并没有接收到请求。
这是什么原因呢?难道惊群现象是假的吗?于是赶紧google查一下,惊群到底是怎么出现的。
其实在Linux2.6版本以后,内核内核已经解决了accept()函数的“惊群”问题,大概的处理方式就是,当内核接收到一个客户连接后,只会唤醒等待队列上的第一个进程或线程。所以,如果服务器采用accept阻塞调用方式,在最新的Linux系统上,已经没有“惊群”的问题了。
但是,对于实际工程中常见的服务器程序,大都使用select、poll或epoll机制,此时,服务器不是阻塞在accept,而是阻塞在select、poll或epoll_wait,这种情况下的“惊群”仍然需要考虑。接下来以epoll为例分析:
使用epoll非阻塞实现代码如下所示:
1 #include <sys/types.h>
2 #include <sys/socket.h>
3 #include <sys/epoll.h>
4 #include <netdb.h>
5 #include <string.h>
6 #include <stdio.h>
7 #include <unistd.h>
8 #include <fcntl.h>
9 #include <stdlib.h>
10 #include <errno.h>
11 #include <sys/wait.h>
12 #include <unistd.h>
13
14 #define IP "127.0.0.1"
15 #define PORT 8888
16 #define PROCESS_NUM 4
17 #define MAXEVENTS 64
18
19 static int create_and_bind ()
20 {
21 int fd = socket(PF_INET, SOCK_STREAM, 0);
22 struct sockaddr_in serveraddr;
23 serveraddr.sin_family = AF_INET;
24 inet_pton( AF_INET, IP, &serveraddr.sin_addr);
25 serveraddr.sin_port = htons(PORT);
26 bind(fd, (struct sockaddr*)&serveraddr, sizeof(serveraddr));
27 return fd;
28 }
29
30 static int make_socket_non_blocking (int sfd)
31 {
32 int flags, s;
33 flags = fcntl (sfd, F_GETFL, 0);
34 if (flags == -1) {
35 perror ("fcntl");
36 return -1;
37 }
38 flags |= O_NONBLOCK;
39 s = fcntl (sfd, F_SETFL, flags);
40 if (s == -1) {
41 perror ("fcntl");
42 return -1;
43 }
44 return 0;
45 }
46
47 void worker(int sfd, int efd, struct epoll_event *events, int k) {
48 /* The event loop */
49 while (1) {
50 int n, i;
51 n = epoll_wait(efd, events, MAXEVENTS, -1);
52 printf("worker %d return from epoll_wait!\n", k);
53 for (i = 0; i < n; i++) {
54 if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) || (!(events[i].events &EPOLLIN))) {
55 /* An error has occured on this fd, or the socket is not ready for reading (why were we notified then?) */
56 fprintf (stderr, "epoll error\n");
57 close (events[i].data.fd);
58 continue;
59 } else if (sfd == events[i].data.fd) {
60 /* We have a notification on the listening socket, which means one or more incoming connections. */
61 struct sockaddr in_addr;
62 socklen_t in_len;
63 int infd;
64 char hbuf[NI_MAXHOST], sbuf[NI_MAXSERV];
65 in_len = sizeof in_addr;
66 infd = accept(sfd, &in_addr, &in_len);
67 if (infd == -1) {
68 printf("worker %d accept failed!\n", k);
69 break;
70 }
71 printf("worker %d accept successed!\n", k);
72 /* Make the incoming socket non-blocking and add it to the list of fds to monitor. */
73 close(infd);
74 }
75 }
76 }
77 }
78
79 int main (int argc, char *argv[])
80 {
81 int sfd, s;
82 int efd;
83 struct epoll_event event;
84 struct epoll_event *events;
85 sfd = create_and_bind();
86 if (sfd == -1) {
87 abort ();
88 }
89 s = make_socket_non_blocking (sfd);
90 if (s == -1) {
91 abort ();
92 }
93 s = listen(sfd, SOMAXCONN);
94 if (s == -1) {
95 perror ("listen");
96 abort ();
97 }
98 efd = epoll_create(MAXEVENTS);
99 if (efd == -1) {
100 perror("epoll_create");
101 abort();
102 }
103 event.data.fd = sfd;
104 event.events = EPOLLIN;
105 s = epoll_ctl(efd, EPOLL_CTL_ADD, sfd, &event);
106 if (s == -1) {
107 perror("epoll_ctl");
108 abort();
109 }
110
111 /* Buffer where events are returned */
112 events = calloc(MAXEVENTS, sizeof event);
113 int k;
114 for(k = 0; k < PROCESS_NUM; k++) {
115 printf("Create worker %d\n", k+1);
116 int pid = fork();
117 if(pid == 0) {
118 worker(sfd, efd, events, k);
119 }
120 }
121 int status;
122 wait(&status);
123 free (events);
124 close (sfd);
125 return EXIT_SUCCESS;
126 }
父进程中创建套接字,并设置为非阻塞,开始listen。然后fork出4个子进程,在worker中调用epoll_wait开始accpet连接。使用telnet测试结果如下:
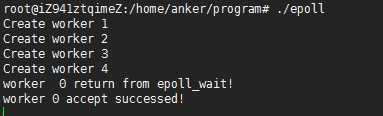
从结果看出,与上面是一样的,只有一个进程接收到连接,其他三个没有收到,说明没有发生惊群现象。这又是为什么呢?
在早期的Linux版本中,内核对于阻塞在epoll_wait的进程,也是采用全部唤醒的机制,所以存在和accept相似的“惊群”问题。新版本的的解决方案也是只会唤醒等待队列上的第一个进程或线程,所以,新版本Linux 部分的解决了epoll的“惊群”问题。所谓部分的解决,意思就是:对于部分特殊场景,使用epoll机制,已经不存在“惊群”的问题了,但是对于大多数场景,epoll机制仍然存在“惊群”。
epoll存在惊群的场景如下:在worker保持工作的状态下,都会被唤醒,例如在epoll_wait后调用sleep一次。改写woker函数如下:
void worker(int sfd, int efd, struct epoll_event *events, int k) {
/* The event loop */
while (1) {
int n, i;
n = epoll_wait(efd, events, MAXEVENTS, -1);
/*keep running*/
sleep(2);
printf("worker %d return from epoll_wait!\n", k);
for (i = 0; i < n; i++) {
if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP) || (!(events[i].events &EPOLLIN))) {
/* An error has occured on this fd, or the socket is not ready for reading (why were we notified then?) */
fprintf (stderr, "epoll error\n");
close (events[i].data.fd);
continue;
} else if (sfd == events[i].data.fd) {
/* We have a notification on the listening socket, which means one or more incoming connections. */
struct sockaddr in_addr;
socklen_t in_len;
int infd;
char hbuf[NI_MAXHOST], sbuf[NI_MAXSERV];
in_len = sizeof in_addr;
infd = accept(sfd, &in_addr, &in_len);
if (infd == -1) {
printf("worker %d accept failed,error:%s\n", k, strerror(errno));
break;
}
printf("worker %d accept successed!\n", k);
/* Make the incoming socket non-blocking and add it to the list of fds to monitor. */
close(infd);
}
}
}
}
测试结果如下所示:
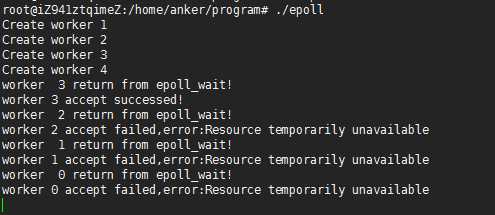
终于看到惊群现象的出现了。
4、解决惊群问题
Nginx中使用mutex互斥锁解决这个问题,具体措施有使用全局互斥锁,每个子进程在epoll_wait()之前先去申请锁,申请到则继续处理,获取不到则等待,并设置了一个负载均衡的算法(当某一个子进程的任务量达到总设置量的7/8时,则不会再尝试去申请锁)来均衡各个进程的任务量。后面深入学习一下Nginx的惊群处理过程。
5、参考网址
先来看看什么是“惊群”?简单说来,多线程/多进程(linux下线程进程也没多大区别)等待同一个socket事件,当这个事件发生时,这些线程/进程被同时唤醒,就是惊群。可以想见,效率很低下,许多进程被内核重新调度唤醒,同时去响应这一个事件,当然只有一个进程能处理事件成功,其他的进程在处理该事件失败后重新休眠(也有其他选择)。这种性能浪费现象就是惊群。
惊群通常发生在server 上,当父进程绑定一个端口监听socket,然后fork出多个子进程,子进程们开始循环处理(比如accept)这个socket。每当用户发起一个TCP连接时,多个子进程同时被唤醒,然后其中一个子进程accept新连接成功,余者皆失败,重新休眠。
那么,我们不能只用一个进程去accept新连接么?然后通过消息队列等同步方式使其他子进程处理这些新建的连接,这样惊群不就避免了?没错,惊群是避免了,但是效率低下,因为这个进程只能用来accept连接。对多核机器来说,仅有一个进程去accept,这也是程序员在自己创造accept瓶颈。所以,我仍然坚持需要多进程处理accept事件。
其实,在linux2.6内核上,accept系统调用已经不存在惊群了(至少我在2.6.18内核版本上已经不存在)。大家可以写个简单的程序试下,在父进程中bind,listen,然后fork出子进程,所有的子进程都accept这个监听句柄。这样,当新连接过来时,大家会发现,仅有一个子进程返回新建的连接,其他子进程继续休眠在accept调用上,没有被唤醒。
但是很不幸,通常我们的程序没那么简单,不会愿意阻塞在accept调用上,我们还有许多其他网络读写事件要处理,linux下我们爱用epoll解决非阻塞socket。所以,即使accept调用没有惊群了,我们也还得处理惊群这事,因为epoll有这问题。上面说的测试程序,如果我们在子进程内不是阻塞调用accept,而是用epoll_wait,就会发现,新连接过来时,多个子进程都会在epoll_wait后被唤醒!
手头原来有一个单进程的linux epoll服务器程序,近来希望将它改写成多进程版本,主要原因有:
- 在服务高峰期间 并发的 网络请求非常海量,目前的单进程版本的程序有点吃不消:单进程时只有一个循环先后处理epoll_wait()到的事件,使得某些不幸排队靠后的socket fd的网络事件处理不及时(担心有些socket客户端等不耐烦而超时断开);
- 希望充分利用到服务器的多颗CPU;
- 主进程先监听端口, listen_fd = socket(...);
- 创建epoll,epoll_fd = epoll_create(...);
- 然后开始fork(),每个子进程进入大循环,去等待new accept,epoll_wait(...),处理事件等。
- 实际情况中,在发生惊群时,并非全部子进程都会被唤醒,而是一部分子进程被唤醒。但被唤醒的进程仍然只有1个成功accept,其他皆失败。
- 所有基于linux epoll机制的服务器程序在多进程时都受惊群问题的困扰,包括 lighttpd 和nginx 等程序,各家程序的处理办法也不一样。
- lighttpd的解决思路:无视惊群。采用Watcher/Workers模式,具体措施有优化fork()与epoll_create()的位置(让每个子进程自己去epoll_create()和epoll_wait()),捕获accept()抛出来的错误并忽视等。这样子一来,当有新accept时仍将有多个lighttpd子进程被唤醒。
- nginx的解决思路:避免惊群。具体措施有使用全局互斥锁,每个子进程在epoll_wait()之前先去申请锁,申请到则继续处理,获取不到则等待,并设置了一个负载均衡的算法(当某一个子进程的任务量达到总设置量的7/8时,则不会再尝试去申请锁)来均衡各个进程的任务量。
- 一款国内的优秀商业MTA服务器程序(不便透露名称):采用Leader/Followers线程模式,各个线程地位平等,轮流做Leader来响应请求。
- 对比lighttpd和nginx两套方案,前者实现方便,逻辑简单,但那部分无谓的进程唤醒带来的资源浪费的代价如何仍待商榷(有网友测试认为这部分开销不大 http://www.iteye.com/topic/382107)。后者逻辑较复杂,引入互斥锁和负载均衡算分也带来了更多的程序开销。所以这两款程序在解决问题的同时,都有其他一部分计算开销,只是哪一个开销更大,未有数据对比。
- 坊间也流传Linux 2.6.x之后的内核,就已经解决了accept的惊群问题,论文地址 http://static.usenix.org/event/usenix2000/freenix/full_papers/molloy/molloy.pdf 。
- 但其实不然,这篇论文里提到的改进并未能彻底解决实际生产环境中的惊群问题,因为大多数多进程服务器程序都是在fork()之后,再对epoll_wait(listen_fd,...)的事件,这样子当listen_fd有新的accept请求时,进程们还是会被唤醒。论文的改进主要是在内核级别让accept()成为原子操作,避免被多个进程都调用了。
- 主进程先监听端口, listen_fd = socket(...); ,setsockopt(listen_fd, SOL_SOCKET, SO_REUSEADDR,...),setnonblocking(listen_fd),listen(listen_fd,...)。
- 开始fork(),到达子进程数上限(建议根据服务器实际的CPU核数来配置)后,主进程变成一个Watcher,只做子进程维护和信号处理等全局性工作。
- 每一个子进程(Worker)中,都创建属于自己的epoll,epoll_fd = epoll_create(...);,接着将listen_fd加入epoll_fd中,然后进入大循环,epoll_wait()等待并处理事件。千万注意, epoll_create()这一步一定要在fork()之后。
- 大胆设想(未实现):每个Worker进程采用多线程方式来提高大循环的socket fd处理速度,必要时考虑加入互斥锁来做同步,但也担心这样子得不偿失(进程+线程频繁切换带来的额外操作系统开销),这一步尚未实现和测试,但看到nginx源码中貌似有此逻辑。
accept与epoll惊群
今天打开 OneNote,发现里面躺着一篇很久以前写的笔记,现在将它贴出来。
1. 什么叫惊群现象
首先,我们看看维基百科对惊群的定义:
The thundering herd problem occurs when a large number of processes waiting for an event are awoken when that event occurs, but only one process is able to proceed at a time. After the processes wake up, they all demand the resource and a decision must be made as to which process can continue. After the decision is made, the remaining processes are put back to sleep, only to all wake up again to request access to the resource.
This occurs repeatedly, until there are no more processes to be woken up. Because all the processes use system resources upon waking, it is more efficient if only one process was woken up at a time.
This may render the computer unusable, but it can also be used as a technique if there is no other way to decide which process should continue (for example when programming with semaphores).
简而言之,惊群现象(thundering herd)就是当多个进程和线程在同时阻塞等待同一个事件时,如果这个事件发生,会唤醒所有的进程,但最终只可能有一个进程/线程对该事件进行处理,其他进程/线程会在失败后重新休眠,这种性能浪费就是惊群。
2. accept 惊群
考虑如下场景:
主进程创建socket, bind,
listen之后,fork出多个子进程,每个子进程都开始循环处理(accept)这个socket。每个进程都阻塞在accpet上,当一个新的连接到来时,所有的进程都会被唤醒,但其中只有一个进程会accept成功,其余皆失败,重新休眠。这就是accept惊群。
那么这个问题真的存在吗?
事实上,历史上,Linux 的 accpet 确实存在惊群问题,但现在的内核都解决该问题了。即,当多个进程/线程都阻塞在对同一个 socket 的 accept 调用上时,当有一个新的连接到来,内核只会唤醒一个进程,其他进程保持休眠,压根就不会被唤醒。
测试代码如下:
当我们对该服务器发起连接请求(用 telnet/curl 等模拟)时,会看到只有一个进程被唤醒。
关于 accept 惊群的一些帖子或文章:
- 惊群问题在 linux 上可能是莫须有的问题
- Does the Thundering Herd Problem exist on Linux anymore?
- 历史上解决 linux accept 惊群的补丁讨论
3. epoll惊群
如上所述,accept 已经不存在惊群问题,但 epoll 上还是存在惊群问题。即,如果多个进程/线程阻塞在监听同一个 listening socket fd 的 epoll_wait 上,当有一个新的连接到来时,所有的进程都会被唤醒。
考虑如下场景:
主进程创建 socket, bind, listen 后,将该 socket 加入到 epoll 中,然后 fork 出多个子进程,每个进程都阻塞在 epoll_wait 上,如果有事件到来,则判断该事件是否是该 socket 上的事件,如果是,说明有新的连接到来了,则进行 accept 操作。为了简化处理,忽略后续的读写以及对 accept 返回的新的套接字的处理,直接断开连接。
那么,当新的连接到来时,是否每个阻塞在 epoll_wait 上的进程都会被唤醒呢?
很多博客中提到,测试表明虽然 epoll_wait 不会像 accept 那样只唤醒一个进程/线程,但也不会把所有的进程/线程都唤醒。例如这篇文章:关于多进程 epoll 与 “惊群”问题。
为了验证这个问题,我自己写了一个测试程序:
发现确实如上面那篇博客里所说,当我模拟发起一个请求时,只有一个或少数几个进程被唤醒了。
也就是说,到目前为止,还没有得到一个确定的答案。但后来,在下面这篇博客中看到这样一个评论:http://blog.csdn.net/spch2008/article/details/18301357
这个总结,需要进一步阐述,你的实验,看上去是只有4个进程唤醒了,而事实上,其余进程没有被唤醒的原因是你的某个进程已经处理完这个 accept,内核队列上已经没有这个事件,无需唤醒其他进程。你可以在 epoll 获知这个 accept 事件的时候,不要立即去处理,而是 sleep 下,这样所有的进程都会被唤起
看到这个评论后,我顿时如醍醐灌顶,重新修改了上面的测试程序,即在 epoll_wait 返回后,加了个 sleep 语句,这时再测试,果然发现所有的进程都被唤醒了。
所以,epoll_wait上的惊群确实是存在的。
4. 为什么内核不处理 epoll 惊群
看到这里,我们可能有疑惑了,为什么内核对 accept 的惊群做了处理,而现在仍然存在 epoll 的惊群现象呢?
我想,应该是这样的:
accept 确实应该只能被一个进程调用成功,内核很清楚这一点。但 epoll 不一样,他监听的文件描述符,除了可能后续被 accept
调用外,还有可能是其他网络 IO 事件的,而其他 IO
事件是否只能由一个进程处理,是不一定的,内核不能保证这一点,这是一个由用户决定的事情,例如可能一个文件会由多个进程来读写。所以,对 epoll
的惊群,内核则不予处理。
5. Nginx 是如何处理惊群问题的
在思考这个问题之前,我们应该以前对前面所讲几点有所了解,即先弄清楚问题的背景,并能自己复现出来,而不仅仅只是看书或博客,然后再来看看 Nginx 的解决之道。这个顺序不应该颠倒。
首先,我们先大概梳理一下 Nginx 的网络架构,几个关键步骤为:
- Nginx 主进程解析配置文件,根据 listen 指令,将监听套接字初始化到全局变量 ngx_cycle 的 listening 数组之中。此时,监听套接字的创建、绑定工作早已完成。
- Nginx 主进程 fork 出多个子进程。
- 每个子进程在 ngx_worker_process_init 方法里依次调用各个 Nginx 模块的 init_process 钩子,其中当然也包括 NGX_EVENT_MODULE 类型的 ngx_event_core_module 模块,其 init_process 钩子为 ngx_event_process_init。
- ngx_event_process_init 函数会初始化 Nginx 内部的连接池,并把 ngx_cycle 里的监听套接字数组通过连接池来获得相应的表示连接的 ngx_connection_t 数据结构,这里关于 Nginx 的连接池先略过。我们主要看 ngx_event_process_init 函数所做的另一个工作:如果在配置文件里没有开启accept_mutex锁,就通过 ngx_add_event 将所有的监听套接字添加到 epoll 中。
- 每一个 Nginx 子进程在执行完 ngx_worker_process_init 后,会在一个死循环中执行 ngx_process_events_and_timers,这就进入到事件处理的核心逻辑了。
- 在 ngx_process_events_and_timers 中,如果在配置文件里开启了 accept_mutext 锁,子进程就会去获取 accet_mutext 锁。如果获取成功,则通过 ngx_enable_accept_events 将监听套接字添加到 epoll 中,否则,不会将监听套接字添加到 epoll 中,甚至有可能会调用 ngx_disable_accept_events 将监听套接字从 epoll 中删除(如果在之前的连接中,本worker子进程已经获得过accept_mutex锁)。
- ngx_process_events_and_timers 继续调用 ngx_process_events,在这个函数里面阻塞调用 epoll_wait。
至此,关于 Nginx 如何处理 fork 后的监听套接字,我们已经差不多理清楚了,当然还有一些细节略过了,比如在每个 Nginx 在获取 accept_mutex 锁前,还会根据当前负载来判断是否参与 accept_mutex 锁的争夺。
把这个过程理清了之后,Nginx 解决惊群问题的方法也就出来了,就是利用 accept_mutex 这把锁。
如果配置文件中没有开启 accept_mutex,则所有的监听套接字不管三七二十一,都加入到每子个进程的 epoll中,这样当一个新的连接来到时,所有的 worker 子进程都会惊醒。
如果配置文件中开启了 accept_mutex,则只有一个子进程会将监听套接字添加到 epoll 中,这样当一个新的连接来到时,当然就只有一个 worker 子进程会被唤醒了。
6. 小结
现在我们对惊群及 Nginx 的处理总结如下:
- accept 不会有惊群,epoll_wait 才会。
- Nginx 的 accept_mutex,并不是解决 accept 惊群问题,而是解决 epoll_wait 惊群问题。
- 说Nginx 解决了 epoll_wait 惊群问题,也是不对的,它只是控制是否将监听套接字加入到epoll 中。监听套接字只在一个子进程的 epoll 中,当新的连接来到时,其他子进程当然不会惊醒了。