1、前言
昨天总结了一下Linux下网络编程“惊群”现象,给出Nginx处理惊群的方法,使用互斥锁。为例发挥多核的优势,目前常见的网络编程模型就是多进程或多线程,根据accpet的位置,分为如下场景:
(1)单进程或线程创建socket,并进行listen和accept,接收到连接后创建进程和线程处理连接
(2)单进程或线程创建socket,并进行listen,预先创建好多个工作进程或线程accept()在同一个服务器套接字、
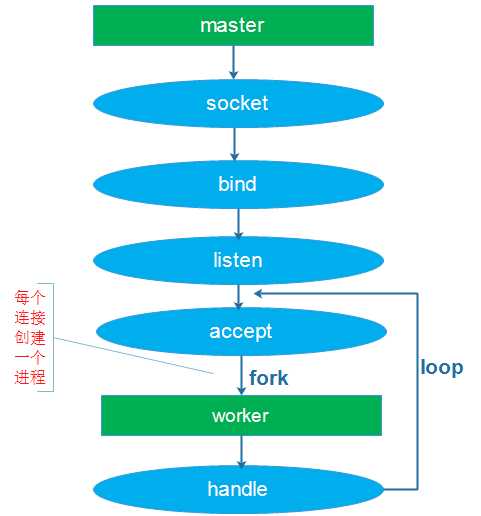
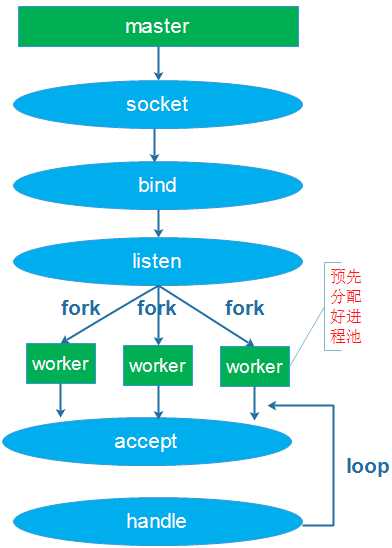
这两种模型解充分发挥了多核CPU的优势,虽然可以做到线程和CPU核绑定,但都会存在:
- 单一listener工作进程胡线程在高速的连接接入处理时会成为瓶颈
- 多个线程之间竞争获取服务套接字
- 缓存行跳跃
- 很难做到CPU之间的负载均衡
- 随着核数的扩展,性能并没有随着提升
参考:http://www.blogjava.net/yongboy/archive/2015/02/12/422893.html
Linux kernel 3.9带来了SO_REUSEPORT特性,可以解决以上大部分问题。
2、SO_REUSEPORT解决了什么问题
SO_REUSEPORT支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,解决的问题:
- 允许多个套接字 bind()/listen() 同一个TCP/UDP端口
- 每一个线程拥有自己的服务器套接字
- 在服务器套接字上没有了锁的竞争
- 内核层面实现负载均衡
- 安全层面,监听同一个端口的套接字只能位于同一个用户下面
其核心的实现主要有三点:
- 扩展 socket option,增加 SO_REUSEPORT 选项,用来设置 reuseport。
- 修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口
- 修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择。
有了SO_RESUEPORT后,每个进程可以自己创建socket、bind、listen、accept相同的地址和端口,各自是独立平等的。让多进程监听同一个端口,各个进程中accept socket fd不一样,有新连接建立时,内核只会唤醒一个进程来accept,并且保证唤醒的均衡性。
3、测试代码

1 include <stdio.h>
2 #include <unistd.h>
3 #include <sys/types.h>
4 #include <sys/socket.h>
5 #include <netinet/in.h>
6 #include <arpa/inet.h>
7 #include <assert.h>
8 #include <sys/wait.h>
9 #include <string.h>
10 #include <errno.h>
11 #include <stdlib.h>
12 #include <fcntl.h>
13
14 #define IP "127.0.0.1"
15 #define PORT 8888
16 #define WORKER 4
17 #define MAXLINE 4096
18
19 int worker(int i)
20 {
21 struct sockaddr_in address;
22 bzero(&address, sizeof(address));
23 address.sin_family = AF_INET;
24 inet_pton( AF_INET, IP, &address.sin_addr);
25 address.sin_port = htons(PORT);
26
27 int listenfd = socket(PF_INET, SOCK_STREAM, 0);
28 assert(listenfd >= 0);
29
30 int val =1;
31 /*set SO_REUSEPORT*/
32 if (setsockopt(listenfd, SOL_SOCKET, SO_REUSEPORT, &val, sizeof(val))<0) {
33 perror("setsockopt()");
34 }
35 int ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
36 assert(ret != -1);
37
38 ret = listen(listenfd, 5);
39 assert(ret != -1);
40 while (1) {
41 printf("I am worker %d, begin to accept connection.\n", i);
42 struct sockaddr_in client_addr;
43 socklen_t client_addrlen = sizeof( client_addr );
44 int connfd = accept( listenfd, ( struct sockaddr* )&client_addr, &client_addrlen );
45 if (connfd != -1) {
46 printf("worker %d accept a connection success. ip:%s, prot:%d\n", i, inet_ntoa(client_addr.sin_addr), client_addr.sin_port);
47 } else {
48 printf("worker %d accept a connection failed,error:%s", i, strerror(errno));
49 }
50 char buffer[MAXLINE];
51 int nbytes = read(connfd, buffer, MAXLINE);
52 printf("read from client is:%s\n", buffer);
53 write(connfd, buffer, nbytes);
54 close(connfd);
55 }
56 return 0;
57 }
58
59 int main()
60 {
61 int i = 0;
62 for (i = 0; i < WORKER; i++) {
63 printf("Create worker %d\n", i);
64 pid_t pid = fork();
65 /*child process */
66 if (pid == 0) {
67 worker(i);
68 }
69 if (pid < 0) {
70 printf("fork error");
71 }
72 }
73 /*wait child process*/
74 while (wait(NULL) != 0)
75 ;
76 if (errno == ECHILD) {
77 fprintf(stderr, "wait error:%s\n", strerror(errno));
78 }
79 return 0;
80 }
我的测试机器内核版本为:

测试结果如下所示:
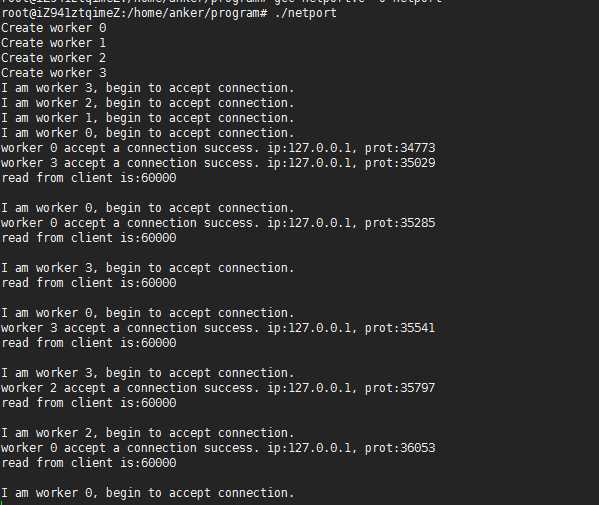
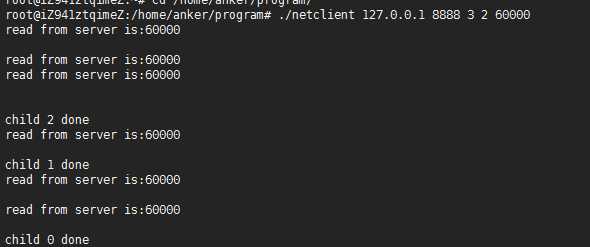

从结果可以看出,四个进程监听相同的IP和port。
4、参考资料
http://lists.dragonflybsd.org/pipermail/users/2013-July/053632.html
http://m.blog.chinaunix.net/uid-10167808-id-3807060.html
SO_REUSEPORT学习笔记
前言
本篇用于记录学习SO_REUSEPORT的笔记和心得,末尾还会提供一个bindp小工具也能为已有的程序享受这个新的特性。
当前Linux网络应用程序问题
运行在Linux系统上网络应用程序,为了利用多核的优势,一般使用以下比较典型的多进程/多线程服务器模型:
- 单线程listen/accept,多个工作线程接收任务分发,虽CPU的工作负载不再是问题,但会存在:
- 单线程listener,在处理高速率海量连接时,一样会成为瓶颈
- CPU缓存行丢失套接字结构(socket structure)现象严重
- 所有工作线程都accept()在同一个服务器套接字上呢,一样存在问题:
- 多线程访问server socket锁竞争严重
- 高负载下,线程之间处理不均衡,有时高达3:1不均衡比例
- 导致CPU缓存行跳跃(cache line bouncing)
- 在繁忙CPU上存在较大延迟
上面模型虽然可以做到线程和CPU核绑定,但都会存在:
- 单一listener工作线程在高速的连接接入处理时会成为瓶颈
- 缓存行跳跃
- 很难做到CPU之间的负载均衡
- 随着核数的扩展,性能并没有随着提升
比如HTTP CPS(Connection Per Second)吞吐量并没有随着CPU核数增加呈现线性增长: ")
Linux kernel 3.9带来了SO_REUSEPORT特性,可以解决以上大部分问题。
SO_REUSEPORT解决了什么问题
linux man文档中一段文字描述其作用:
The new socket option allows multiple sockets on the same host to bind to the same port, and is intended to improve the performance of multithreaded network server applications running on top of multicore systems.
SO_REUSEPORT支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,解决的问题:
- 允许多个套接字 bind()/listen() 同一个TCP/UDP端口
- 每一个线程拥有自己的服务器套接字
- 在服务器套接字上没有了锁的竞争
- 内核层面实现负载均衡
- 安全层面,监听同一个端口的套接字只能位于同一个用户下面
其核心的实现主要有三点:
- 扩展 socket option,增加 SO_REUSEPORT 选项,用来设置 reuseport。
- 修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口
- 修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择。
代码分析,可以参考引用资料 [多个进程绑定相同端口的实现分析[Google Patch]]。
CPU之间平衡处理,水平扩展
以前通过fork形式创建多个子进程,现在有了SO_REUSEPORT,可以不用通过fork的形式,让多进程监听同一个端口,各个进程中accept socket fd不一样,有新连接建立时,内核只会唤醒一个进程来accept,并且保证唤醒的均衡性。
模型简单,维护方便了,进程的管理和应用逻辑解耦,进程的管理水平扩展权限下放给程序员/管理员,可以根据实际进行控制进程启动/关闭,增加了灵活性。
这带来了一个较为微观的水平扩展思路,线程多少是否合适,状态是否存在共享,降低单个进程的资源依赖,针对无状态的服务器架构最为适合了。
新特性测试或多个版本共存
可以很方便的测试新特性,同一个程序,不同版本同时运行中,根据运行结果决定新老版本更迭与否。
针对对客户端而言,表面上感受不到其变动,因为这些工作完全在服务器端进行。
服务器无缝重启/切换
想法是,我们迭代了一版本,需要部署到线上,为之启动一个新的进程后,稍后关闭旧版本进程程序,服务一直在运行中不间断,需要平衡过度。这就像Erlang语言层面所提供的热更新一样。
想法不错,但是实际操作起来,就不是那么平滑了,还好有一个hubtime开源工具,原理为SIGHUP信号处理器+SO_REUSEPORT+LD_RELOAD,可以帮助我们轻松做到,有需要的同学可以检出试用一下。
SO_REUSEPORT已知问题
SO_REUSEPORT根据数据包的四元组{src ip, src port, dst ip, dst port}和当前绑定同一个端口的服务器套接字数量进行数据包分发。若服务器套接字数量产生变化,内核会把本该上一个服务器套接字所处理的客户端连接所发送的数据包(比如三次握手期间的半连接,以及已经完成握手但在队列中排队的连接)分发到其它的服务器套接字上面,可能会导致客户端请求失败,一般可以使用:
- 使用固定的服务器套接字数量,不要在负载繁忙期间轻易变化
- 允许多个服务器套接字共享TCP请求表(Tcp request table)
- 不使用四元组作为Hash值进行选择本地套接字处理,挑选隶属于同一个CPU的套接字
与RFS/RPS/XPS-mq协作,可以获得进一步的性能:
- 服务器线程绑定到CPUs
- RPS分发TCP SYN包到对应CPU核上
- TCP连接被已绑定到CPU上的线程accept()
- XPS-mq(Transmit Packet Steering for multiqueue),传输队列和CPU绑定,发送数据
- RFS/RPS保证同一个连接后续数据包都会被分发到同一个CPU上
- 网卡接收队列已经绑定到CPU,则RFS/RPS则无须设置
- 需要注意硬件支持与否
目的嘛,数据包的软硬中断、接收、处理等在一个CPU核上,并行化处理,尽可能做到资源利用最大化。
SO_REUSEPORT不是一贴万能膏药
虽然SO_REUSEPORT解决了多个进程共同绑定/监听同一端口的问题,但根据新浪林晓峰同学测试结果来看,在多核扩展层面也未能够做到理想的线性扩展:
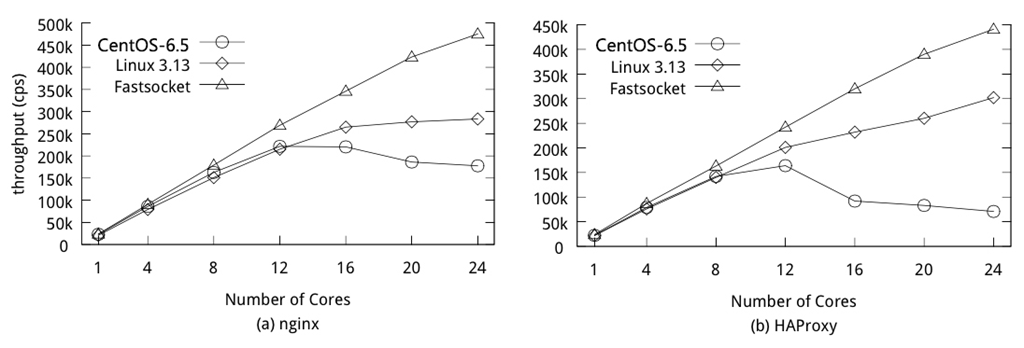
可以参考Fastsocket在其基础之上的改进,链接地址。
支持SO_REUSEPORT的Tengine
淘宝的Tengine已经支持了SO_REUSEPORT特性,在其测试报告中,有一个简单测试,可以看出来相对比SO_REUSEPORT所带来的性能提升:

使用SO_REUSEPORT以后,最明显的效果是在压力下不容易出现丢请求的情况,CPU均衡性平稳。
Java支持否?
JDK 1.6语言层面不支持,至于以后的版本,由于暂时没有使用到,不多说。
Netty
3/4版本默认都不支持SO_REUSEPORT特性,但Netty 4.0.19以及之后版本才真正提供了JNI方式单独包装的epoll
native transport版本(在Linux系统下运行),可以配置类似于SO_REUSEPORT等(JAVA
NIIO没有提供)选项,这部分是在io.netty.channel.epoll.EpollChannelOption中定义(在线代码部分)。
在linux环境下使用epoll native transport,可以获得内核层面网络堆栈增强的红利,如何使用可参考Native transports文档。
使用epoll native transport倒也简单,类名稍作替换:
NioEventLoopGroup → EpollEventLoopGroup
NioEventLoop → EpollEventLoop
NioServerSocketChannel → EpollServerSocketChannel
NioSocketChannel → EpollSocketChannel
比如写一个PING-PONG应用服务器程序,类似代码:
public void run() throws Exception {
EventLoopGroup bossGroup = new EpollEventLoopGroup();
EventLoopGroup workerGroup = new EpollEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
ChannelFuture f = b
.group(bossGroup, workerGroup)
.channel(EpollServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast(
new StringDecoder(CharsetUtil.UTF_8),
new StringEncoder(CharsetUtil.UTF_8),
new PingPongServerHandler());
}
}).option(ChannelOption.SO_REUSEADDR, true)
.option(EpollChannelOption.SO_REUSEPORT, true)
.childOption(ChannelOption.SO_KEEPALIVE, true).bind(port)
.sync();
f.channel().closeFuture().sync();
} finally {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
}
}
若不要这么折腾,还想让以往Java/Netty应用程序在不做任何改动的前提下顺利在Linux kernel >= 3.9下同样享受到SO_REUSEPORT带来的好处,不妨尝试一下bindp,更为经济,这一部分下面会讲到。
bindp,为已有应用添加SO_REUSEPORT特性
以前所写bindp小程序,可以为已有程序绑定指定的IP地址和端口,一方面可以省去硬编码,另一方面也为测试提供了一些方便。
另外,为了让以前没有硬编码SO_REUSEPORT的应用程序可以在Linux内核3.9以及之后Linux系统上也能够得到内核增强支持,稍做修改,添加支持。
但要求如下:
- Linux内核(>= 3.9)支持SO_REUSEPORT特性
- 需要配置
REUSE_PORT=1
不满足以上条件,此特性将无法生效。
使用示范:
REUSE_PORT=1 BIND_PORT=9999 LD_PRELOAD=./libbindp.so java -server -jar pingpongserver.jar &
当然,你可以根据需要运行命令多次,多个进程监听同一个端口,单机进程水平扩展。
使用示范
使用python脚本快速构建一个小的示范原型,两个进程,都监听同一个端口10000,客户端请求返回不同内容,仅供娱乐。
server_v1.py,简单PING-PONG:
# -*- coding:UTF-8 -*-
import socket
import os
PORT = 10000
BUFSIZE = 1024
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind((‘‘, PORT))
s.listen(1)
while True:
conn, addr = s.accept()
data = conn.recv(PORT)
conn.send(‘Connected to server[%s] from client[%s]\n‘ % (os.getpid(), addr))
conn.close()
s.close()
server_v2.py,输出当前时间:
# -*- coding:UTF-8 -*-
import socket
import time
import os
PORT = 10000
BUFSIZE = 1024
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind((‘‘, PORT))
s.listen(1)
while True:
conn, addr = s.accept()
data = conn.recv(PORT)
conn.send(‘server[%s] time %s\n‘ % (os.getpid(), time.ctime()))
conn.close()
s.close()
借助于bindp运行两个版本的程序:
REUSE_PORT=1 LD_PRELOAD=/opt/bindp/libindp.so python server_v1.py &
REUSE_PORT=1 LD_PRELOAD=/opt/bindp/libindp.so python server_v2.py &
模拟客户端请求10次:
for i in {1..10};do echo "hello" | nc 127.0.0.1 10000;done
看看结果吧:
Connected to server[3139] from client[(‘127.0.0.1‘, 48858)]
server[3140] time Thu Feb 12 16:39:12 2015
server[3140] time Thu Feb 12 16:39:12 2015
server[3140] time Thu Feb 12 16:39:12 2015
Connected to server[3139] from client[(‘127.0.0.1‘, 48862)]
server[3140] time Thu Feb 12 16:39:12 2015
Connected to server[3139] from client[(‘127.0.0.1‘, 48864)]
server[3140] time Thu Feb 12 16:39:12 2015
Connected to server[3139] from client[(‘127.0.0.1‘, 48866)]
Connected to server[3139] from client[(‘127.0.0.1‘, 48867)]
可以看出来,CPU分配很均衡,各自分配50%的请求量。
嗯,虽是小玩具,有些意思 :))
bindp的使用方法
更多使用说明,请参考README。
参考资料
- 《SO_REUSEPORT: Scaling Techniques for Servers with High Connection Rates》PPT
- huptime
- SO_REUSEPORT and accept(2) performance
- 多个进程绑定相同端口的实现分析[Google Patch]
多个进程绑定相同端口的实现分析[Google Patch]
Google REUSEPORT 新特性,支持多个进程或者线程绑定到相同的 IP 和端口,以提高 server 的性能。
1. 设计思路
该特性实现了 IPv4/IPv6 下 TCP/UDP 协议的支持, 已经集成到 kernel 3.9 中。
核心的实现主要有三点:
- 扩展 socket option,增加 SO_REUSEPORT 选项,用来设置 reuseport。
- 修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口
- 修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择。
共包含 7 个 patch,其中有两个为 buf fix
- 数据结构调整: 055dc21a1d1d219608cd4baac7d0683fb2cbbe8a
- TCP/IPv4: da5e36308d9f7151845018369148201a5d28b46d
- UDP/IPv4: ba418fa357a7b3c9d477f4706c6c7c96ddbd1360
- TCP/IPv6: 5ba24953e9707387cce87b07f0d5fbdd03c5c11b
- UDP/IPv6: 72289b96c943757220ccc681fe2e22b46e21aced
- bug fix: 7c0cadc69ca2ac8893aa162ee80d92a805840909 fix: UDP/IPv4
- bug fix: 5588d3742da9900323dc3d766845a53bacdfb5ab fix: 数据结构定义
下面根据该特性的实现,简单介绍 IPv4 下多个进程绑定相同 IP 和端口的逻辑分析。 kernel 代码版本:3.11-rc1。
2. 数据结构扩展
通用 sock 结构扩展,增加 skc_reuseport 成员,用于 socket option 配置是记录对应 结果:
--- a/include/net/sock.h
+++ b/include/net/sock.h
@@ -140,6 +140,7 @@ typedef __u64 __bitwise __addrpair;
* @skc_family: network address family
* @skc_state: Connection state
* @skc_reuse: %SO_REUSEADDR setting
+ * @skc_reuseport: %SO_REUSEPORT setting
* @skc_bound_dev_if: bound device index if != 0
* @skc_bind_node: bind hash linkage for various protocol lookup tables
* @skc_portaddr_node: second hash linkage for UDP/UDP-Lite protocol
@@ -179,7 +180,8 @@ struct sock_common {
unsigned short skc_family;
volatile unsigned char skc_state;
- unsigned char skc_reuse;
+ unsigned char skc_reuse:4;
+ unsigned char skc_reuseport:4;
int skc_bound_dev_if;
union {
struct hlist_node skc_bind_node;
@@ -297,6 +299,7 @@ struct sock {
#define sk_family __sk_common.skc_family
#define sk_state __sk_common.skc_state
#define sk_reuse __sk_common.skc_reuse
+#define sk_reuseport __sk_common.skc_reuseport
#define sk_bound_dev_if __sk_common.skc_bound_dev_if
#define sk_bind_node __sk_common.skc_bind_node
#define sk_prot __sk_common.skc_prot
--- a/net/core/sock.c
+++ b/net/core/sock.c
@@ -665,6 +665,9 @@ int sock_setsockopt(struct socket *sock, int level, int optname,
case SO_REUSEADDR:
sk->sk_reuse = (valbool ? SK_CAN_REUSE : SK_NO_REUSE);
break;
+ case SO_REUSEPORT:
+ sk->sk_reuseport = valbool;
+ break;
case SO_TYPE:
case SO_PROTOCOL:
case SO_DOMAIN:
bind socket 结构扩展,记录 fastreuseport 和 fastuid。这个会在执行 bind 时做相关 的初始化。其中,fastuid 应该是创建 fd 的 uid。
--- a/include/net/inet_hashtables.h
+++ b/include/net/inet_hashtables.h
@@ -81,7 +81,9 @@ struct inet_bind_bucket {
struct net *ib_net;
#endif
unsigned short port;
- signed short fastreuse;
+ signed char fastreuse;
+ signed char fastreuseport;
+ kuid_t fastuid;
int num_owners;
struct hlist_node node;
struct hlist_head owners;
对于 TCP 来讲,owners 记录了使用相同端口号的 sock 列表。这个列表中的 sock 也包含 了监听 IP 不同的情况。而我们要分析的相同 IP 和端口 sock 也在该列表中。
3. bind 系统调用
分析该函数的 callpath,就是为了明确 google patch 中如果是绑定相同 IP 和 端口号的 多个 socket 如何成功的通过 bind 系统调用。如果没有该 patch 的话,应该返回 Address in use 之类的错误。
sys_bind() -> inet_bind() (TCP) -> sk->sk_prot->get_port(TCP: inet_csk_get_port)
inet_csk_get_port() 根据 bind 参数中指定的端口,查表 hashinfo->bhash
3.1. 初次绑定某端口
初次绑定某个端口的话,应该查表找不到对应的 struct inet_bind_bucket tb,因此要调用 inet_bind_bucket_create 创建一个表项,并作 resue 方面的初始化:
216 tb_not_found:
217 ret = 1;
218 if (!tb && (tb = inet_bind_bucket_create(hashinfo->bind_bucket_cachep,
219 net, head, snum)) == NULL)
220 goto fail_unlock;
221 if (hlist_empty(&tb->owners)) {
222 if (sk->sk_reuse && sk->sk_state != TCP_LISTEN)
223 tb->fastreuse = 1;
224 else
225 tb->fastreuse = 0;
226 if (sk->sk_reuseport) {
227 tb->fastreuseport = 1;
228 tb->fastuid = uid;
229 } else
230 tb->fastreuseport = 0;
231 } else {
226-228 行: 如果 socket 设置了 reuseport 的话,则新建表项的 fastreuseport 置 1, fastuid 也记录下来,应该就是创建当前 socket fd 的 uid
接着调用 inet_bind_hash() 将当前的 sock 插入到 tb->owners 中,并增加计数
62 void inet_bind_hash(struct sock *sk, struct inet_bind_bucket *tb,
63 const unsigned short snum)
64 {
65 struct inet_hashinfo *hashinfo = sk->sk_prot->h.hashinfo;
66
67 atomic_inc(&hashinfo->bsockets);
68
69 inet_sk(sk)->inet_num = snum;
70 sk_add_bind_node(sk, &tb->owners);
71 tb->num_owners++;
72 inet_csk(sk)->icsk_bind_hash = tb;
73 }
并将 sock 对应 inet_connection_sock 的icsk_bind_hash 执行新分配的 tb。
3.2. 再次绑定相同端口
这次应该就可以找到对应的 tb,因此应该进行如下流程:
190 tb_found:
191 if (!hlist_empty(&tb->owners)) {
192 if (sk->sk_reuse == SK_FORCE_REUSE)
193 goto success;
194
195 if (((tb->fastreuse > 0 &&
196 sk->sk_reuse && sk->sk_state != TCP_LISTEN) ||
197 (tb->fastreuseport > 0 &&
198 sk->sk_reuseport && uid_eq(tb->fastuid, uid))) &&
199 smallest_size == -1) {
200 goto success;
201 } else {
202 ret = 1;
203 if (inet_csk(sk)->icsk_af_ops->bind_conflict(sk, tb, true)) {
204 if (((sk->sk_reuse && sk->sk_state != TCP_LISTEN) ||
205 (tb->fastreuseport > 0 &&
206 sk->sk_reuseport && uid_eq(tb->fastuid, uid))) &&
207 smallest_size != -1 && --attempts >= 0) {
208 spin_unlock(&head->lock);
209 goto again;
210 }
211
212 goto fail_unlock;
213 }
214 }
215 }
195-196 为 socket reuse 的判断,并且非 LISTEN 的认为可以 bind,如果已经处理 LISTEN 状态的话,这里的条件不成立
197-198 为 Google patch 的检测,tb 配置启用了 reuseport,并且当前 socket 也设置 了reuseport,且 tb 和当前 socket 的 UID 一样,可以认为当前 socket 也可以放到 bind hash 中,随后会调用 inet_bind_hash 将当前 sock 也加入到 tb->owners 链表中。
4. listen 系统调用
sys_listen -> inet_listen -> inet_csk_listen_start
关键的实现就在 inet_csk_listen_start 中。重要的检测主要是再次检查端口是否可用。 因为 bind 和 listen 的执行有时间差,完全有可能被别的进程占去:
769 sk->sk_state = TCP_LISTEN;
770 if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
771 inet->inet_sport = htons(inet->inet_num);
772
773 sk_dst_reset(sk);
774 sk->sk_prot->hash(sk);
775
776 return 0;
777 }
774 行调用 sk->sk_prot->hash(sk) 将对应的 sock 加入到 listening hash 中。 对于 TCP 而言, hash 指针指向 inet_hash()。这里记录下 listen socket 的 hash 的计算逻辑:
inet_hash ->__inet_hash(sk) ->inet_sk_listen_hashfn ->inet_lhashfn
238 /* These can have wildcards, don‘t try too hard. */
239 static inline int inet_lhashfn(struct net *net, const unsigned short num)
240 {
241 return (num + net_hash_mix(net)) & (INET_LHTABLE_SIZE - 1);
242 }
对于 listening socket,可以看出,应该是按照端口做 key 的,最终将 socket 放到了 listening_hash[] 中。
因此,绑定同一个端口的多个 listener sock 最后是放在了同一个 bucket 中。
5. 接受新连接
这里主要就是重点观察 TCP 协议栈将新建连接的请求分发给绑定了相同 IP 和端口的不同 listening socket。
tcp_v4_rcv -> __inet_lookup_skb -> __inet_lookup -> __inet_lookup_listener (新建连接,只能通过 listener hash 查到其所属 listener)
__inet_lookup_listener 函数增加两个参数,saddr 和 sport。没有 Google patch 之前, 查找 listener 的话是不需要这两个参数的:
177 struct sock *__inet_lookup_listener(struct net *net,
178 struct inet_hashinfo *hashinfo,
179 const __be32 saddr, __be16 sport,
180 const __be32 daddr, const unsigned short hnum,
181 const int dif)
182 {
... ...
191 begin:
192 result = NULL;
193 hiscore = 0;
194 sk_nulls_for_each_rcu(sk, node, &ilb->head) {
195 score = compute_score(sk, net, hnum, daddr, dif);
196 if (score > hiscore) {
197 result = sk;
198 hiscore = score;
199 reuseport = sk->sk_reuseport;
200 if (reuseport) {
201 phash = inet_ehashfn(net, daddr, hnum,
202 saddr, sport);
203 matches = 1;
204 }
205 } else if (score == hiscore && reuseport) {
206 matches++;
207 if (((u64)phash * matches) >> 32 == 0)
208 result = sk;
209 phash = next_pseudo_random32(phash);
210 }
211 }
该函数就是根据 sip+sport+dip+dport+dif 来查找合适的 listener。在没加入 google REUSEPORT patch 之前,是没有 sip 和 sport 的。这两个元素就是用来帮助在多个监 听相同 port 的 listener 之间做选择,并可能尽量保证公平。
这里有个函数调用 compute_score(),用来计算匹配的分数,得分最高的 listener 将作为 result 返回。计算的匹配分数主要是看 listener 的 portnum,rcv_saddr, 目的接口与 listener 的匹配程度。
196-204 行: 查到一个合适的 listener,而且得分比历史记录还高,记下该 sock。同时, 考虑到 reuseport 的问题,根据四元组计算一个 phash,match 置 1.
205 行: 走到这个分支,说明就是出现了 reuseport 的情况,而且是遍历到了第 N 个 (N>1)个监听相同端口的 listener。因此,其得分与历史得分肯定相等。
206-209 行:这几行代码就是实现了是否使用当前 listener 的逻辑。如果不使用的话, 那就继续遍历下一个。最终的结果就会在多个绑定相同端口的 listener 中使用其中一个。 因为 phash 的初次计算中加入了 saddr 和 sport,这个算法在 IP 地址及 port 足够多 的情况下保证了多个 listener 都会被平均分配到请求。
至此,google REUSEPORT 的 patch 简单的分析完毕。