最近使用scrapy模拟登陆知乎,发现所有接口都发生变化了,包括验证码也发生了很大变化,通过抓包分析,记录下改版后的知乎模拟登陆,废话不多说,直接上代码,亲测有效
# -*- coding: utf-8 -*-
from PIL import Image
from scrapy.exceptions import CloseSpider
import scrapy
import json
import base64
class ZhihuSpider(scrapy.Spider):
name = ‘zhihu‘
allowed_domains = [‘www.zhihu.com‘]
start_urls = [‘http://www.zhihu.com/‘]
handle_httpstatus_list = [401, 403]
client_id = ‘c3cef7c66a1843f8b3a9e6a1e3160e20‘ #固定不变
signature = ‘b858d0c8b1f2e86c6cb0d93d4055963bcf1121ec‘ #抓包获取
timestamp = ‘1519567594106‘ #抓包获取
headers = {
"HOST": "www.zhihu.com",
"Referer": "https://www.zhihu.com/signup?next=%2F",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36Name",
"authorization": "oauth c3cef7c66a1843f8b3a9e6a1e3160e20",
}
def parse(self, response):
pass
def start_requests(self):
‘‘‘
获取登陆页面,set_cookie
:return:
‘‘‘
return [scrapy.Request(url=‘https://www.zhihu.com/signup?next=%2F‘,
headers=self.headers,
method="GET",
meta={‘cookiejar‘:1},
callback=self.post_captchareq,
dont_filter=True,
)]
def post_captchareq(self, response):
‘‘‘
发送获取验证码请求
:param response:
:return:
‘‘‘
return [scrapy.Request(
url=‘https://www.zhihu.com/api/v3/oauth/captcha?lang=en‘,
headers=self.headers,
meta={‘cookiejar‘: response.meta[‘cookiejar‘]},
dont_filter=True,
callback=self.deal_captchareq,
)]
def deal_captchareq(self, response):
‘‘‘
判断是否需要验证码
:param response:
:return:
‘‘‘
json_res = json.loads(response.text)
post_data = {
"client_id": self.client_id,
"grant_type":"password",
"timestamp": self.timestamp,
"source": "com.zhihu.web",
"signature": self.signature,
"username": ‘+86你的手机号码‘,
"password":‘密码‘,
"captcha": ‘‘,
"lang":"en",
"ref_source":"homepage",
"utm_source":""
}
if json_res.get("show_captcha", None):
return [
scrapy.Request(
url=‘https://www.zhihu.com/api/v3/oauth/captcha?lang=en‘,
headers=self.headers,
method=‘PUT‘,
meta={‘cookiejar‘: response.meta[‘cookiejar‘],
‘post_data‘:post_data},
callback=self.get_captchaimg
)
]
return [
scrapy.FormRequest(
url="https://www.zhihu.com/api/v3/oauth/sign_in",
formdata=post_data,
method="POST",
headers=self.headers,
meta={‘cookiejar‘: response.meta[‘cookiejar‘]},
callback=self.check_login,
dont_filter=True,
)
]
def get_captchaimg(self, response):
‘‘‘
获取验证码图片流数据,手动输入验证码
:param response:
:return:
‘‘‘
post_data = response.meta[‘post_data‘]
try:
json_img = json.loads(response.text)
bs64_img = json_img["img_base64"]
bs64_img = bs64_img.encode(‘utf-8‘)
img_steam = base64.b64decode(bs64_img)
with open("zhihucaptcha.jpg", ‘wb‘) as f:
f.write(img_steam)
img = Image.open("zhihucaptcha.jpg")
img.show()
input_captcha = input("请输入图中验证码:").strip()
post_data[‘captcha‘] = input_captcha
img.close()
post_code = {
"input_text":input_captcha,
}
return [
scrapy.FormRequest(
url="https://www.zhihu.com/api/v3/oauth/captcha?lang=en",
formdata=post_code,
headers=self.headers,
method=‘POST‘,
meta={‘cookiejar‘: response.meta[‘cookiejar‘],
‘post_data‘:post_data},
callback=self.post_captcha,
dont_filter=True,
)
]
except Exception as e:
raise CloseSpider(‘获取验证码发生错误:{error}‘.format(error=e))
def post_captcha(self, response):
‘‘‘
发送用户认证信息登陆
:param response:
:return:
‘‘‘
post_data = response.meta.get(‘post_data‘)
if json.loads(response.text).get(‘success‘):
return [
scrapy.FormRequest(
url="https://www.zhihu.com/api/v3/oauth/sign_in",
formdata=post_data,
headers=self.headers,
method=‘POST‘,
meta={‘cookiejar‘: response.meta[‘cookiejar‘]},
callback=self.check_login,
dont_filter=True,
)
]
else:
raise CloseSpider(‘验证码不正确‘)
def check_login(self, response):
#验证是否登陆成功
print(‘==============>‘,response.text)
print(response.status)
if response.status == 201:
self.logger.info("登陆成功!")
else:
raise CloseSpider(‘登陆信息有误!‘)
其中,其它参数如client_id, oauth等都是固定的,signature与timestamp是随着时间戳变化的,它是用于验证合法用户的token,实质也是一段客户端的js运行生成的,这里为了方便,直接通过抓包获取某个固定时间戳对应的signature
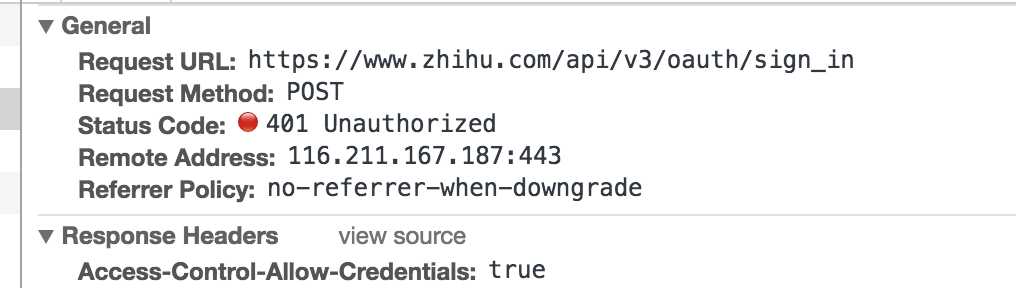
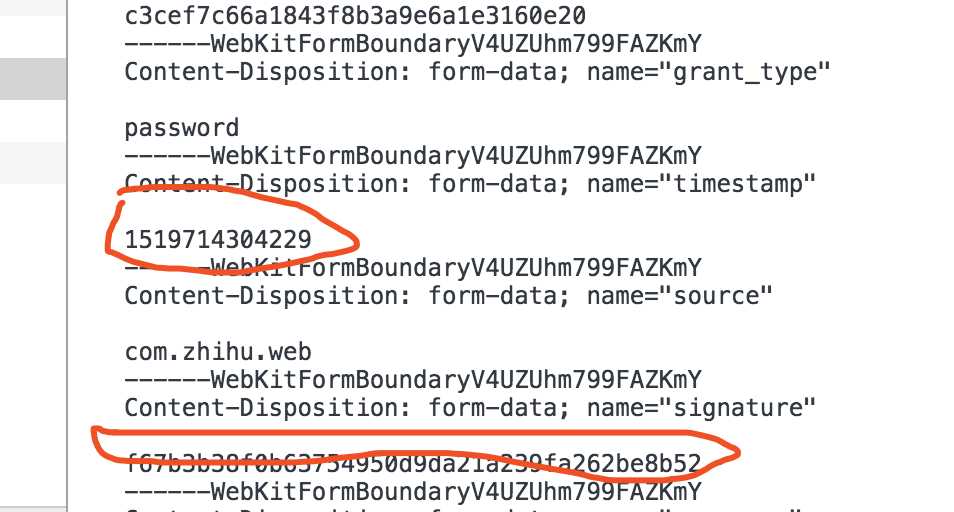
先在pc端输入错误账户信息,抓包获取timestamp与signature,替换对应的即可