集合整体框架图
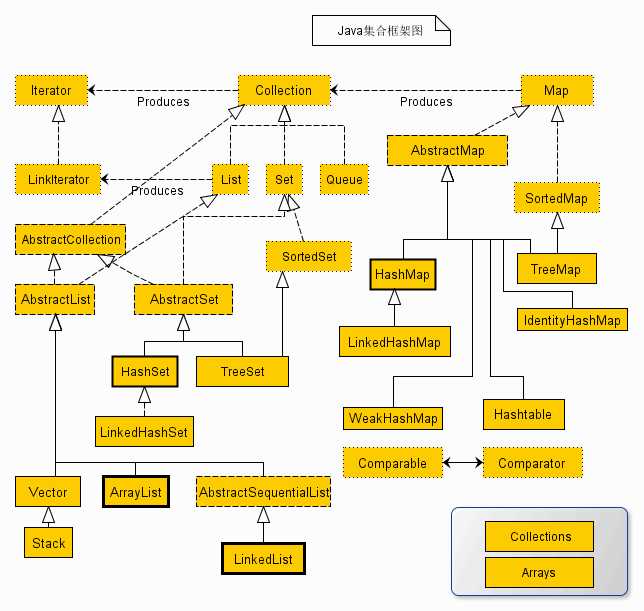
各集合框架的概述
1. Collection(常用List和Set,不常用Queue和Vector),单元素集合。
2. Map(常用HashMap和TreeMap,不常用HashTable),key-value映射关系。
3. Iterator(迭代器)
4. Comparable和Comparator比较器
5. Collections和Arrays工具类
Java中结合和数组的比较
1. 数组的长度在初始化时指定,只能保存定长的数据。
而集合可以保存不确定长度的数据。同时可以保存具有映射关系的数据(即关联数组,键值对key-value)。
2. 数据元素既可以是基本类型的值,也可以是对象,集合只能保存对象(实际上是只保存对象的引用变量),基本数据类型的变量要转换成对应的包装类才能放入集合中。
常用集合特性概述
List系
List的特点:元素有放入顺序,元素可以重复。
List接口的三个实现类:ArrayList、LinkedList和Vector。
ArrayList、LinkedList和Vector的区别
LinkedList:底层是基于链表实现,链表内存是散乱的,每一个元素存储本身内存地址的同时也存储下一个元素的内存地址。链表增删快,查找慢。
ArrayList和Vector:两者底层都是基于数组实现的,查询快,增删慢。两者之间的区别是ArrayList是线程非安全的,效率高;而Vector是线程安全的,效率低。
ArrayList的初始化大小是10,扩容策略是1.5倍原元素数量的大小。
选择标准
如果涉及到“动态数组”、“栈”、“队列”、“链表”等结构,应该考虑用List,具体选择哪个List实现类,根据下面的标准来取舍:
1. 对于需要快速插入、删除元素,应该使用LinkedList。
2. 对于需要快速随机访问元素,应该使用ArrayList。
3. 对于“单线程环境”或者“多线程环境,但List仅仅只会被单个线程操作”,此时应该使用非同步的类(如ArrayList)。对于“多线程环境,且List可能同时被多个线程操作”,此时,应该使用同步的类(如Vector)。
Set系
Set的特点:元素放入无顺序,元素不可重复。
Set接口的三个实现类:LinkedSet、HashSet和LinkedHashSet。
HashSet(底层是通过HashMap实现)底层通过HashCode和equals去重。
HashSet中判断集合元素相等
两个对象比较 具体分为如下四个情况:
1.如果有两个元素通过equal()方法比较返回false,且它们的hashCode()方法返回不相等,HashSet将会把它们存储在不同的位置。
2.如果有两个元素通过equal()方法比较返回true,但它们的hashCode()方法返回不相等,HashSet将会把它们存储在不同的位置。
3.如果两个对象通过equals()方法比较不相等,但hashCode()方法比较相等,HashSet将会把它们存储在相同的位置,在这个位置以链表式结构来保存多个对象。这是因为当向HashSet集合中存入一个元素时,HashSet会调用对象的hashCode()方法来得到对象的hashCode值,然后根据该hashCode值来决定该对象存储在HashSet中存储位置。
4.如果有两个元素通过equal()方法比较返回true,且它们的hashCode()方法返回true,HashSet将不予添加。
HashSet判断两个元素相等的标准:两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法返回值也相等。
注意:HashSet是根据元素的hashCode值来快速定位的,如果HashSet中两个以上的元素具有相同的hashCode值,将会导致性能下降。所以如果重写类的equals()方法和hashCode()方法时,应尽量保证两个对象通过hashCode()方法返回值相等时,通过equals()方法比较返回true。
LinkedHashSet类
LinkedHashSet是HashSet对的子类,也是根据元素的hashCode值来决定元素的存储位置,同时使用链表维护元素的次序,使得元素是以插入的顺序来保存的。当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。但是由于要维护元素的插入顺序,在性能上略低与HashSet,但在迭代访问Set里的全部元素时有很好的性能。
注意:LinkedHashSet依然不允许元素重复,判断重复标准与HashSet一致。
补充:HashSet的实质是一个HashMap。HashSet的所有集合元素,构成了HashMap的key,其value为一个静态Object对象。因此HashSet的所有性质,HashMap的key所构成的集合都具备。可以参考后续文章中HashMap的相关内容进行比对。
TreeSet类
TreeSet是SortedSet接口的实现类,正如SortedSet名字所暗示的,TreeSet可以确保集合元素处于排序状态。此外,TreeSet还提供了几个额外的方法。
1 comparator():返回对此 set 中的元素进行排序的比较器;如果此 set 使用其元素的自然顺序,则返回null。 2 first():返回此 set 中当前第一个(最低)元素。 3 last(): 返回此 set 中当前最后一个(最高)元素。 4 lower(E e):返回此 set 中严格小于给定元素的最大元素;如果不存在这样的元素,则返回 null。 5 higher(E e):返回此 set 中严格大于给定元素的最小元素;如果不存在这样的元素,则返回 null。 6 subSet(E fromElement, E toElement):返回此 set 的部分视图,其元素从 fromElement(包括)到 toElement(不包括)。 7 headSet(E toElement):返回此 set 的部分视图,其元素小于toElement。 8 tailSet(E fromElement):返回此 set 的部分视图,其元素大于等于 fromElement。
Map系
Map的特点:存储的元素是键值对,在JDK1.8版本中是Node,在老版本中是Entry。
Map接口有四个实现类:HashMap、HashTable、LinkedHashMap和ConcurrentHashMap。
HashMap类
HashMap是非线程安全,高效,支持null的key和value,底层实现是数组和链表,通过HashCode方法和equals方法保证键的唯一性。
如果需要使用线程安全的Map可以有两种方式:
1. 采用HashTable
2. 采用Collections.synchronizedMap(hashMap)方式进行同步。
解决冲突主要有三种方法:定址法、拉链发和再散列发。
HashMap是采用拉链法解决哈希冲突的,拉链法是将相同hash值的对象组成一个链表放在hash值对应的槽位。
HashMap的初始化大小是16,扩展因子是0.75,扩容策略是2倍原容量的大小。
put的大致流程
1. 通过hashCode方法计算出key的hash值
2. 通过hash%length计算出存储在table中的index(源码中是使用hash&(length-1),这样结果相同,但是更快)。
3. 如果此时table[index]的值为空,那么就直接存储,如果不为空那么就链接到这个数所在的链表的头部。(在JDK1.8中,如果链表长度大于8就转化成红黑树)
get的大致流程
1. 通过通过hashCode方法计算出key的hash值
2. 通过hash%length计算出存储在table中的index(源码中是使用hash&(length-1),这样结果相同,但是更快)。
3. 遍历table[index]所在的链表,只有当key与该节点中的key的值相同时才取出。
ConcurrentHashMap类
是从JDK1.5之后提供的一个HashTable的替代实现,采用分段锁机制,一个map中的元素分成很多的segment,通过lock机制可以对每个segment加读写锁,从而提高map的效率,底层实现采用数组+链表+红黑树的存储结构。
HashTable类
线程安全,低效,不支持null的key和value。
SortedMap类
有一个实现类:TreeMap会存储放入元素的顺序。