额,明明记得昨晚存了草稿箱,一觉醒来没了,那就简写点(其实是具体怎么解释我也不太懂/xk,纯属个人理解,有错误还望指正)
环境:
版本:python3
IDE:pycharm2017.3.3
浏览器:火狐(浏览器建议火狐,Chrome)
爬取网站:堆糖
选堆糖是因为比较好爬取(除了img文件就是xhr文件),别网站的反爬取对我这个水平来说都太心机了
安装配置什么的之前都写过,这里就不提了,直接开始
1.先来浏览一下这个网站,打开堆糖官网,搜索校花,他就会给我们推荐一些图片,当我们滚动到页面底部时,他又会加载新的一些图片,再滚到底,再加载,这样加载了五次,才把第一页的所有图片加载出来(这里体现了这个网站的防爬,不过也好破)
我们的目标就是把这19页,每页的图片都爬下来
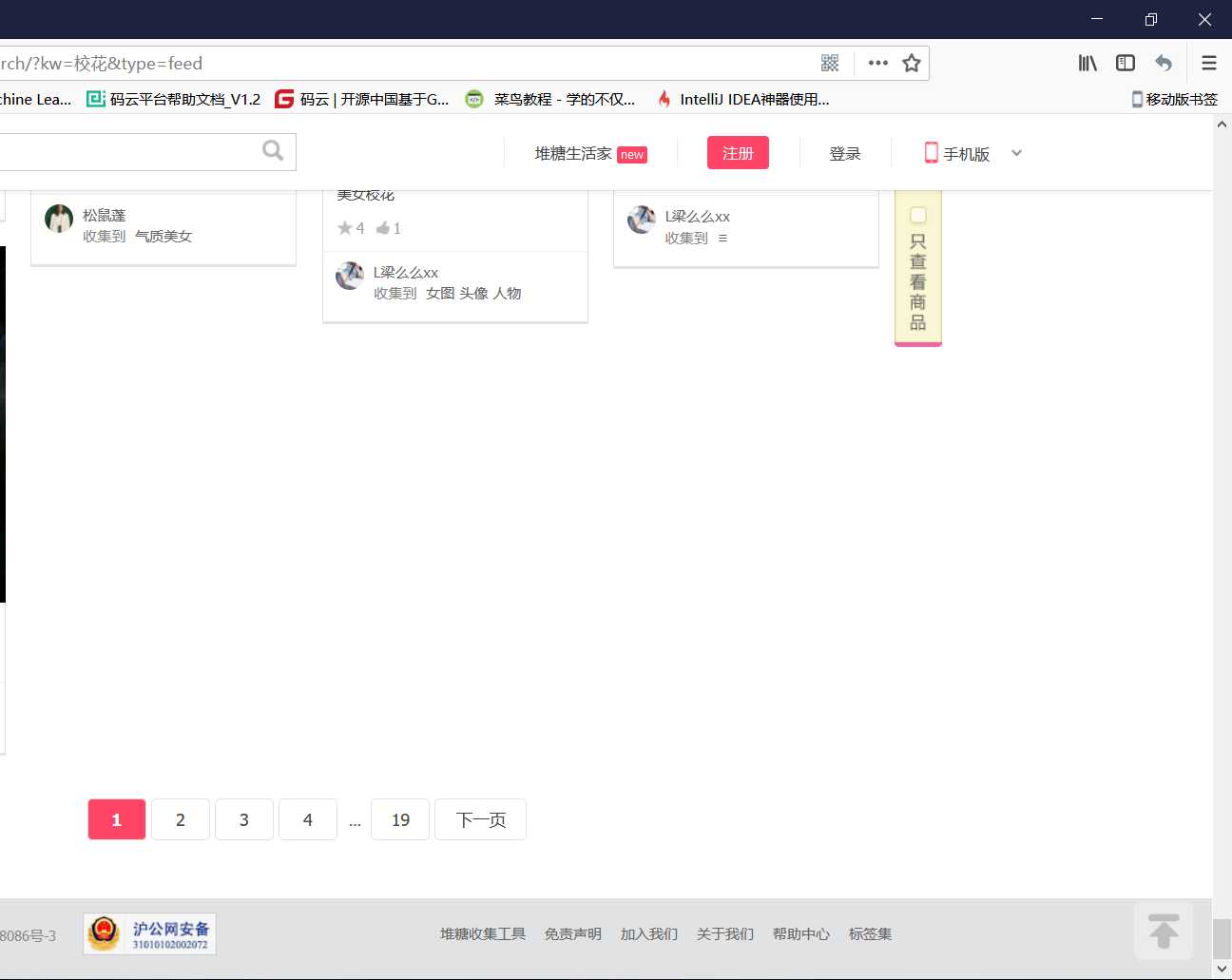
2.重新搜索一下关键字,我们先不往下滚动,右键查看元素,选择网络,可以看到目前这一页中加载的图片,
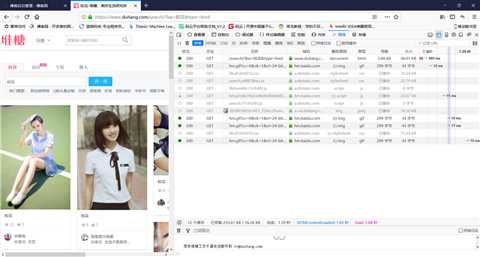
3.然后我们把页面往下滚动,让他继续加载,同时我们观察者网络这个窗口,所有请求的图片也都显示在这里,这时发现xhr类型的文件,这样的文件一共有五个,也就是同一页面中每次滚动到页面底部,新加载图片时就会出现这样的文件
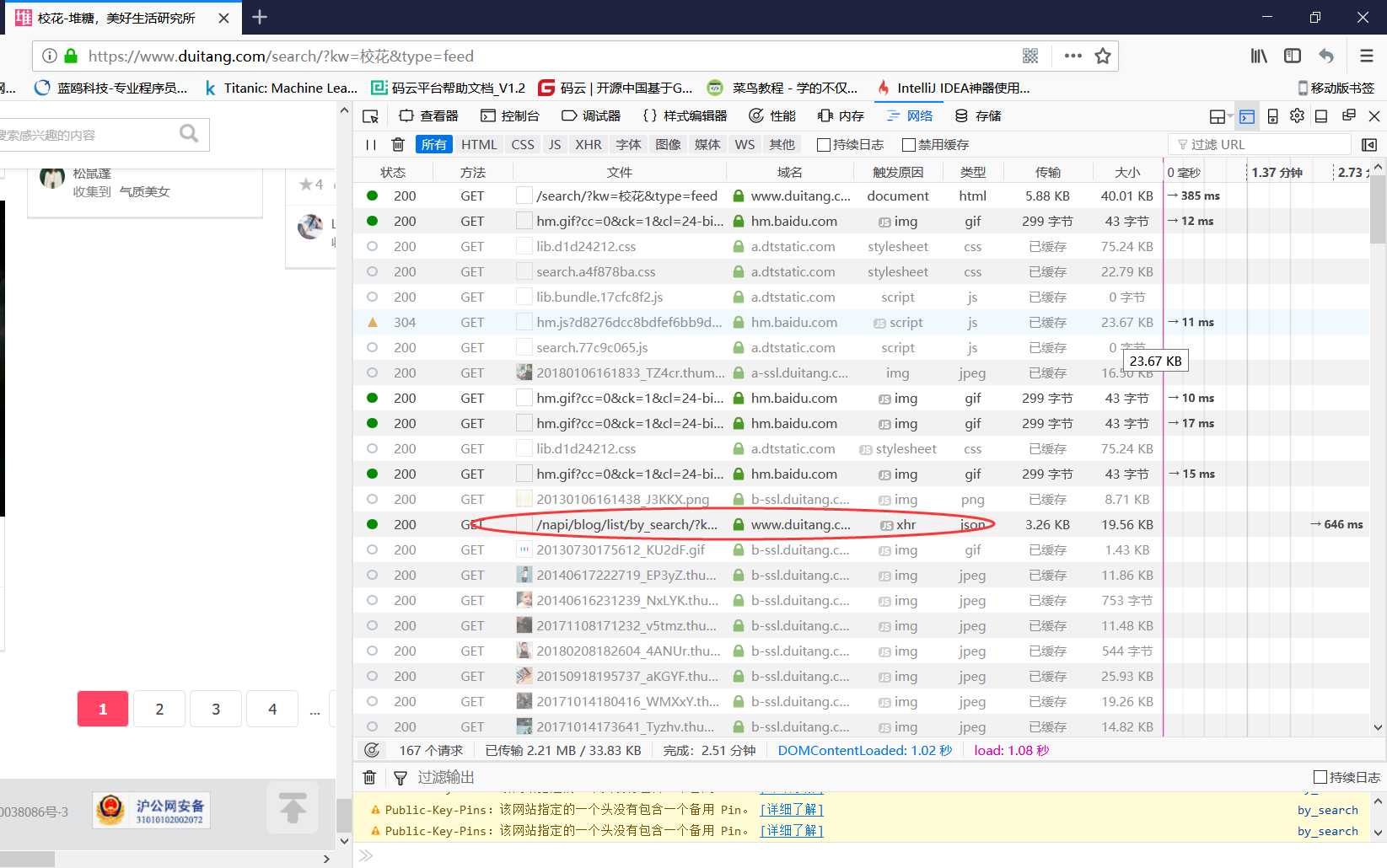
4.主要关注一下这个文件,把窗口切换到xhr类型下,双击打开其中的一个
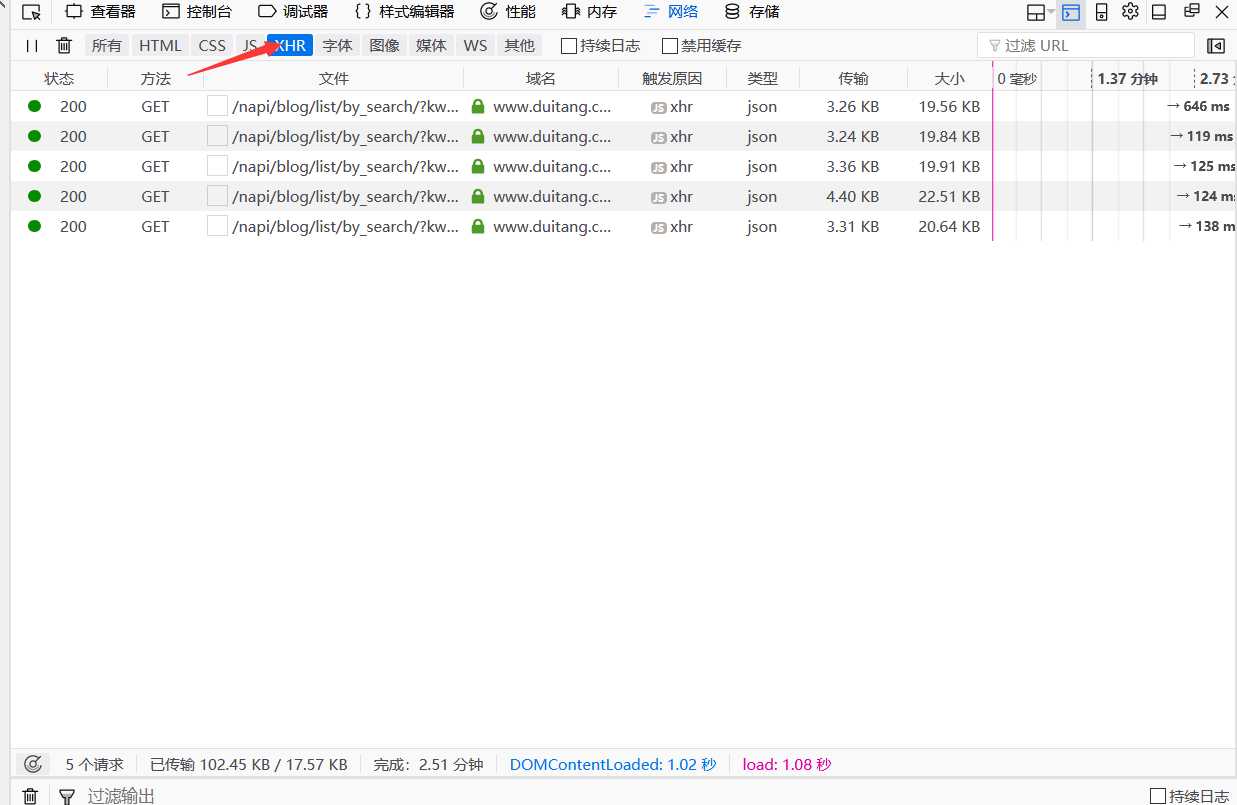
5.这个请求网址使我们需要的,复制到地址栏中
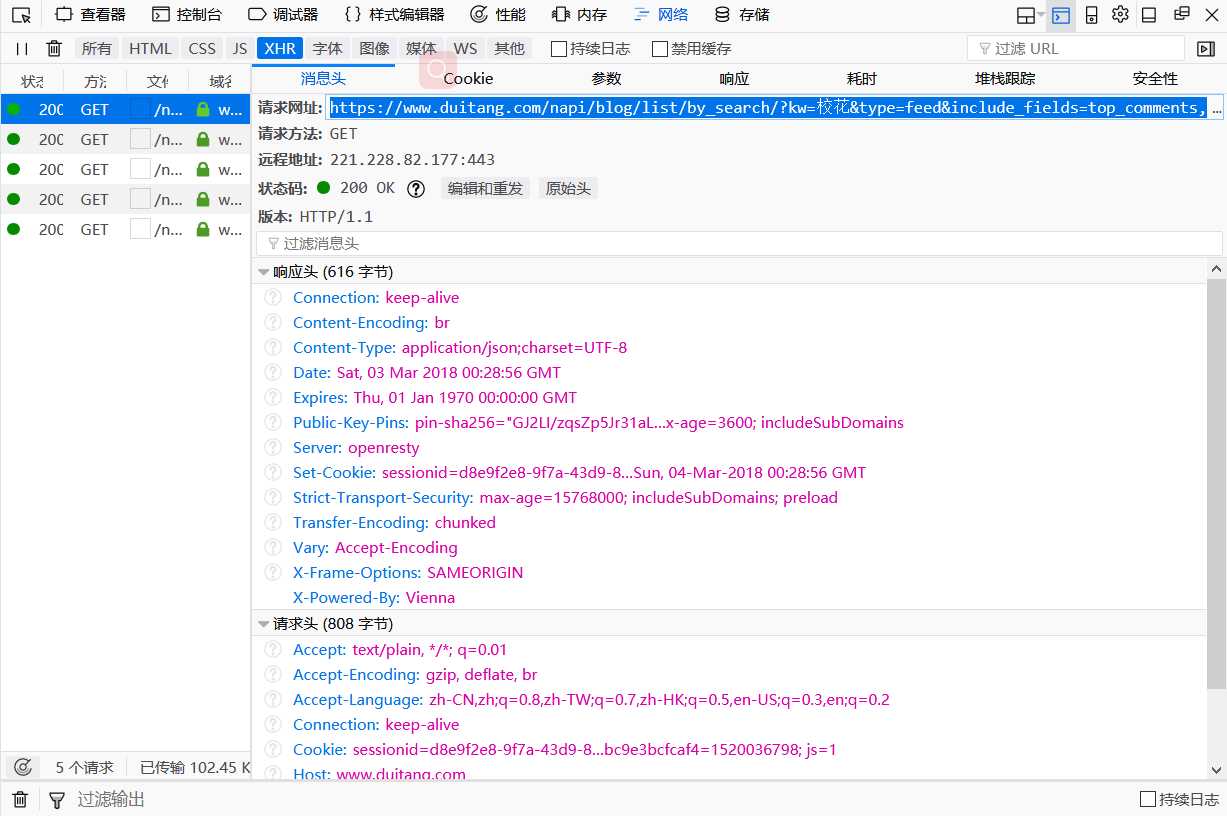
6.这里打开如果是所有代码堆在一起的那样,就需要在线解析一下,解析工具 将地址复制进去进行校验
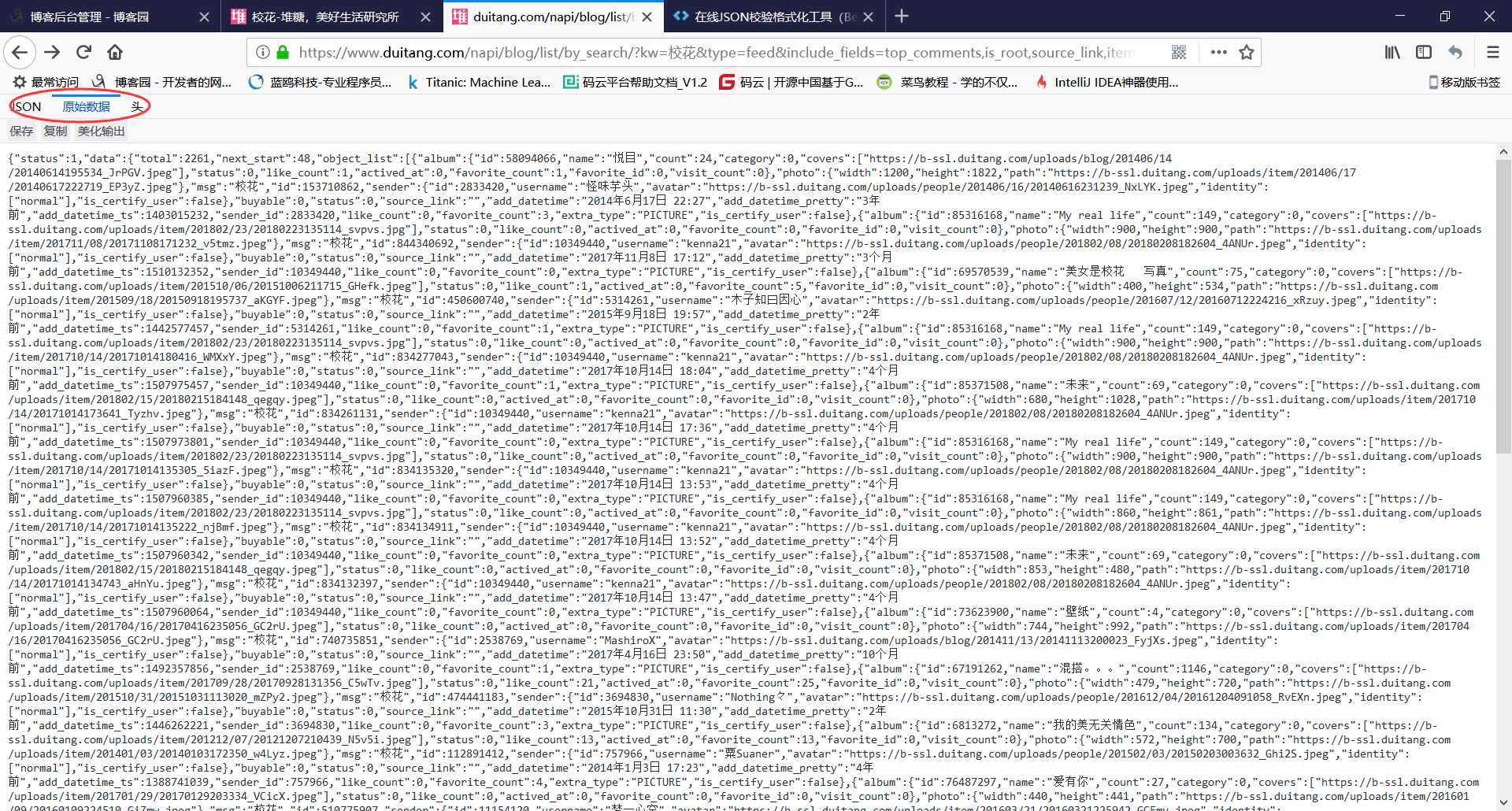
而我这里的火狐浏览器打开直接就是转换好的
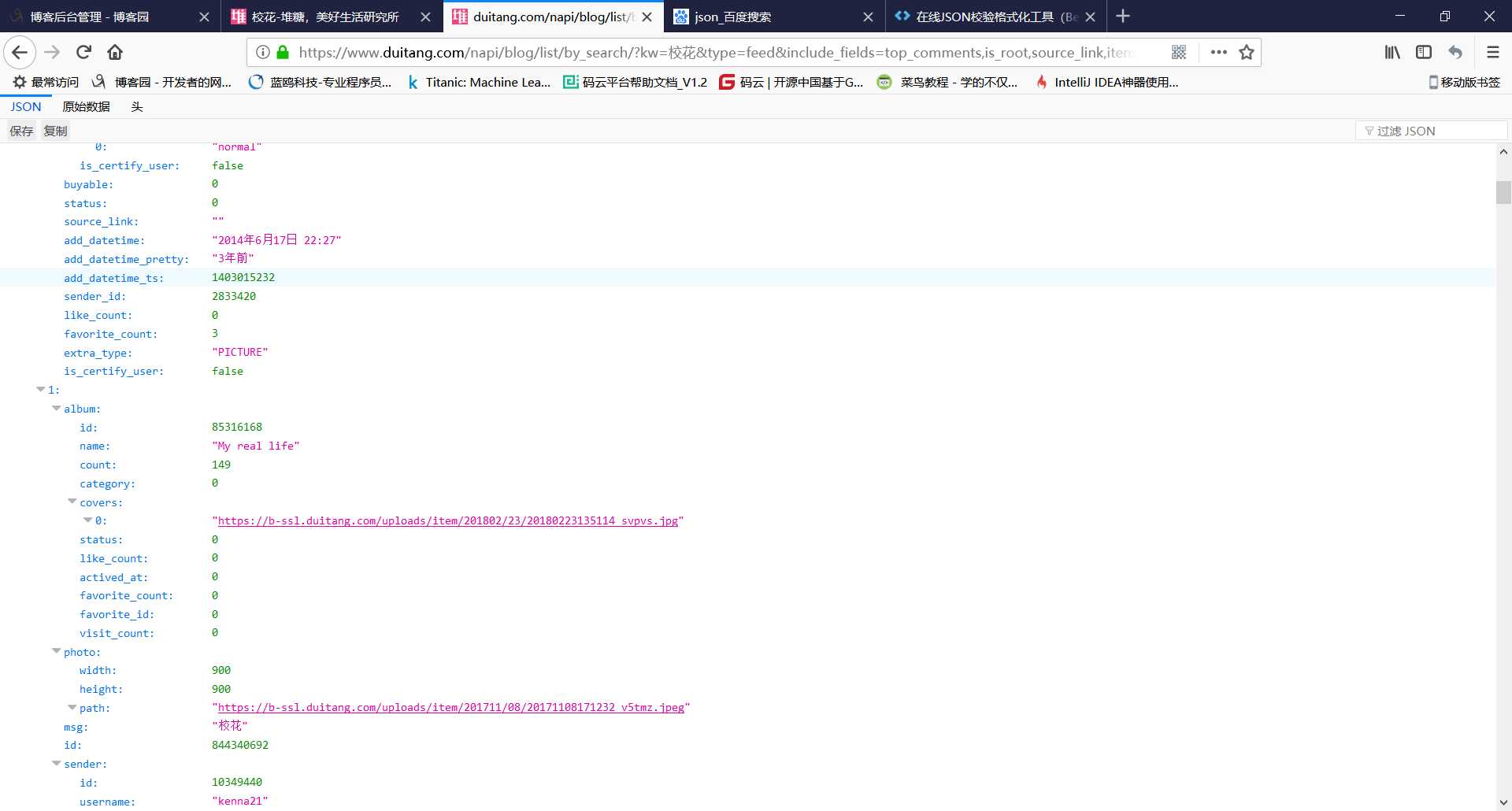
其中的path就是我们需要的
![]()
而这个limit就是限制我们爬取数量的参数,后面需要修改这个参数来爬取全部图片
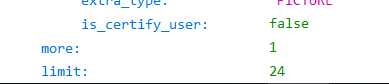
7.对请求地址进行分析
https://www.duitang.com/napi/blog/list/by_search/?kw=校花&type=feed&include_fields=top_comments,is_root,source_link,item,buyable,root_id,status,like_count,sender,album&_type=&start=24&_=1520036797589
将没用的删掉
https://www.duitang.com/napi/blog/list/by_search/?kw=校花&start=24
修改参数start(从0开始爬取),添加参数limit(上限),格式都是&开头
https://www.duitang.com/napi/blog/list/by_search/?kw=校花&start=0&limit=1000
以上就是爬取的分析过程,代码如下
1 import requests 2 import urllib.parse 3 import threading 4 #设置最大线程value 5 thread_lock = threading.BoundedSemaphore(value=10) 6 7 8 #通过url获取数据 9 def get_page(url): 10 page = requests.get(url) 11 page = page.content 12 #将bytes转成字符串 13 page = page.decode(‘utf-8‘) 14 return page 15 #label为关键字 16 def pages_from_duitang(label): 17 pages = [] 18 url = ‘https://www.duitang.com/napi/blog/list/by_search/?kw={}&start=0&limit=1000‘ 19 #将中文转成url编码 20 label = urllib.parse.quote(label) 21 for index in range(0, 3600, 100): 22 u = url.format(label, index) 23 print(u) 24 page = get_page(u) 25 pages.append(page) 26 return pages 27 28 29 #通过切片提取路径 30 def findall_in_page(page, startpart, endpart): 31 all_strings = [] 32 end = 0 33 while page.find(startpart, end) != -1: 34 start = page.find(startpart, end) + len(startpart) 35 end = page.find(endpart, start) 36 string = page[start:end] 37 all_strings.append(string) 38 return all_strings 39 #返回所有图片的链接 40 def pic_urls_from_pages(pages): 41 pic_urls = [] 42 for page in pages: 43 urls = findall_in_page(page, ‘path":"‘, ‘"‘) 44 pic_urls.extend(urls) 45 return pic_urls 46 #下载图片 47 def download_pics(url, n): 48 r = requests.get(url) 49 path = ‘../pics/‘ + str(n) + ‘.jpg‘ 50 with open(path, ‘wb‘) as f: 51 f.write(r.content) 52 #解锁 53 thread_lock.release() 54 55 def main(label): 56 pages = pages_from_duitang(label) 57 pic_urls = pic_urls_from_pages(pages) 58 n = 0 59 for url in pic_urls: 60 n += 1 61 print("正在下载第{}张图片".format(n)) 62 #上锁 63 thread_lock.acquire() 64 t = threading.Thread(target=download_pics, args=(url, n)) 65 t.start() 66 67 68 main(‘校花‘)
pics是我们需要新建的文件夹
目录结构如下,d2018.3.2_urlopen.py是代码,pics是用来存图片的文件夹
运行结果
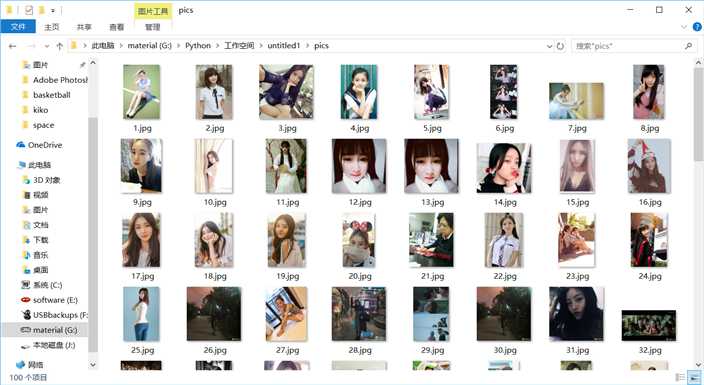
校花们就都存入囊中了,但是数量有点少,只有100个,好像是只爬取了一页的图片,代码应该还有点小问题
不同的网站防爬不一样,但思路应该都差不多