决策树算法在机器学习中算是很经典的一个算法系列了。它既可以作为分类算法,也可以作为回归算法,同时也特别适合集成学习比如随机森林。本文就对决策树算法原理做一个总结,上篇对ID3, C4.5的算法思想做了总结,下篇重点对CART算法做一个详细的介绍。选择CART做重点介绍的原因是scikit-learn使用了优化版的CART算法作为其决策树算法的实现。
1. 决策树ID3算法的信息论基础
机器学习算法其实很古老,作为一个码农经常会不停的敲if, else if, else,其实就已经在用到决策树的思想了。只是你有没有想过,有这么多条件,用哪个条件特征先做if,哪个条件特征后做if比较优呢?怎么准确的定量选择这个标准就是决策树机器学习算法的关键了。1970年代,一个叫昆兰的大牛找到了用信息论中的熵来度量决策树的决策选择过程,方法一出,它的简洁和高效就引起了轰动,昆兰把这个算法叫做ID3。下面我们就看看ID3算法是怎么选择特征的。
首先,我们需要熟悉信息论中熵的概念。熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:
其中n代表X的n种不同的离散取值。而pipi代表了X取值为i的概率,log为以2或者e为底的对数。举个例子,比如X有2个可能的取值,而这两个取值各为1/2时X的熵最大,此时X具有最大的不确定性。值为H(X)=?(12log12+12log12)=log2H(X)=?(12log12+12log12)=log2。如果一个值概率大于1/2,另一个值概率小于1/2,则不确定性减少,对应的熵也会减少。比如一个概率1/3,一个概率2/3,则对应熵为H(X)=?(13log13+23log23)=log3?23log2<log2)H(X)=?(13log13+23log23)=log3?23log2<log2).
熟悉了一个变量X的熵,很容易推广到多个个变量的联合熵,这里给出两个变量X和Y的联合熵表达式:
有了联合熵,又可以得到条件熵的表达式H(X|Y),条件熵类似于条件概率,它度量了我们的X在知道Y以后剩下的不确定性。表达式如下:
好吧,绕了一大圈,终于可以重新回到ID3算法了。我们刚才提到H(X)度量了X的不确定性,条件熵H(X|Y)度量了我们在知道Y以后X剩下的不确定性,那么H(X)-H(X|Y)呢?从上面的描述大家可以看出,它度量了X在知道Y以后不确定性减少程度,这个度量我们在信息论中称为互信息,,记为I(X,Y)。在决策树ID3算法中叫做信息增益。ID3算法就是用信息增益来判断当前节点应该用什么特征来构建决策树。信息增益大,则越适合用来分类。
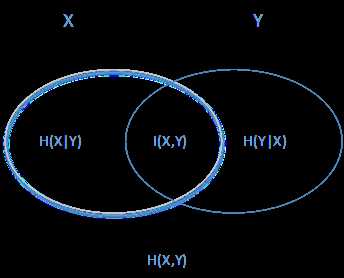
上面一堆概念,大家估计比较晕,用下面这个图很容易明白他们的关系。左边的椭圆代表H(X),右边的椭圆代表H(Y),中间重合的部分就是我们的互信息或者信息增益I(X,Y), 左边的椭圆去掉重合部分就是H(X|Y),右边的椭圆去掉重合部分就是H(Y|X)。两个椭圆的并就是H(X,Y)。
2. 决策树ID3算法的思路
上面提到ID3算法就是用信息增益大小来判断当前节点应该用什么特征来构建决策树,用计算出的信息增益最大的特征来建立决策树的当前节点。这里我们举一个信息增益计算的具体的例子。比如我们有15个样本D,输出为0或者1。其中有9个输出为1, 6个输出为0。 样本中有个特征A,取值为A1,A2和A3。在取值为A1的样本的输出中,有3个输出为1, 2个输出为0,取值为A2的样本输出中,2个输出为1,3个输出为0, 在取值为A3的样本中,4个输出为1,1个输出为0.
样本D的熵为: H(D)=?(915log2915+615log2615)=0.971H(D)=?(915log2915+615log2615)=0.971
样本D在特征下的条件熵为: H(D|A)=515H(D1)+515H(D2)+515H(D3)H(D|A)=515H(D1)+515H(D2)+515H(D3)
=?515(35log235+25log225)?515(25log225+35log235)?515(45log245+15log215)=0.888=?515(35log235+25log225)?515(25log225+35log235)?515(45log245+15log215)=0.888
对应的信息增益为 I(D,A)=H(D)?H(D|A)=0.083I(D,A)=H(D)?H(D|A)=0.083
下面我们看看具体算法过程大概是怎么样的。
输入的是m个样本,样本输出集合为D,每个样本有n个离散特征,特征集合即为A,输出为决策树T。
算法的过程为:
1)初始化信息增益的阈值??
2)判断样本是否为同一类输出DiDi,如果是则返回单节点树T。标记类别为DiDi
3) 判断特征是否为空,如果是则返回单节点树T,标记类别为样本中输出类别D实例数最多的类别。
4)计算A中的各个特征(一共n个)对输出D的信息增益,选择信息增益最大的特征AgAg
5) 如果AgAg的信息增益小于阈值??,则返回单节点树T,标记类别为样本中输出类别D实例数最多的类别。
6)否则,按特征AgAg的不同取值AgiAgi将对应的样本输出D分成不同的类别DiDi。每个类别产生一个子节点。对应特征值为AgiAgi。返回增加了节点的数T。
7)对于所有的子节点,令D=Di,A=A?{Ag}D=Di,A=A?{Ag}递归调用2-6步,得到子树TiTi并返回。
3. 决策树ID3算法的不足
ID3算法虽然提出了新思路,但是还是有很多值得改进的地方。
a)ID3没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。这大大限制了ID3的用途。
b)ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大。如果校正这个问题呢?
c) ID3算法对于缺失值的情况没有做考虑
d) 没有考虑过拟合的问题
ID3 算法的作者昆兰基于上述不足,对ID3算法做了改进,这就是C4.5算法,也许你会问,为什么不叫ID4,ID5之类的名字呢?那是因为决策树太火爆,他的ID3一出来,别人二次创新,很快 就占了ID4, ID5,所以他另辟蹊径,取名C4.0算法,后来的进化版为C4.5算法。下面我们就来聊下C4.5算法
4. 决策树C4.5算法的改进
上一节我们讲到ID3算法有四个主要的不足,一是不能处理连续特征,第二个就是用信息增益作为标准容易偏向于取值较多的特征,最后两个是缺失值处理的问和过拟合问题。昆兰在C4.5算法中改进了上述4个问题。
对于第一个问题,不能处理连续特征, C4.5的思路是将连续的特征离散化。比如m个样本的连续特征A有m个,从小到大排列为a1,a2,...,ama1,a2,...,am,则C4.5取相邻两样本值的平均数,一共取得m-1个划分点,其中第i个划分点Ti表示Ti表示为:Ti=ai+ai+12Ti=ai+ai+12。对于这m-1个点,分别计算以该点作为二元分类点时的信息增益。选择信息增益最大的点作为该连续特征的二元离散分类点。比如取到的增益最大的点为atat,则小于atat的值为类别1,大于atat的值为类别2,这样我们就做到了连续特征的离散化。要注意的是,与离散属性不同的是,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程。
对于第二个问题,信息增益作为标准容易偏向于取值较多的特征的问题。我们引入一个信息增益比的变量IR(X,Y)IR(X,Y),它是信息增益和特征熵的比值。表达式如下:
其中D为样本特征输出的集合,A为样本特征,对于特征熵HA(D)HA(D), 表达式如下:
其中n为特征A的类别数, DiDi为特征A的第i个取值对应的样本个数。D为样本个数。
特征数越多的特征对应的特征熵越大,它作为分母,可以校正信息增益容易偏向于取值较多的特征的问题。
对于第三个缺失值处理的问题,主要需要解决的是两个问题,一是在样本某些特征缺失的情况下选择划分的属性,二是选定了划分属性,对于在该属性上缺失特征的样本的处理。
对于第一个子问题,对于某一个有缺失特征值的特征A。C4.5的思路是将数据分成两部分,对每个样本设置一个权重(初始可以都为1),然后划分数据,一部分是有特征值A的数据D1,另一部分是没有特征A的数据D2. 然后对于没有缺失特征A的数据集D1来和对应的A特征的各个特征值一起计算加权重后的信息增益比,最后乘上一个系数,这个系数是无特征A缺失的样本加权后所占加权总样本的比例。
对于第二个子问题,可以将缺失特征的样本同时划分入所有的子节点,不过将该样本的权重按各个子节点样本的数量比例来分配。比如缺失特征A的样本a之前权重为1,特征A有3个特征值A1,A2,A3。 3个特征值对应的无缺失A特征的样本个数为2,3,4.则a同时划分入A1,A2,A3。对应权重调节为2/9,3/9, 4/9。
对于第4个问题,C4.5引入了正则化系数进行初步的剪枝。具体方法这里不讨论。下篇讲CART的时候会详细讨论剪枝的思路。
除了上面的4点,C4.5和ID的思路区别不大。
5. 决策树C4.5算法的不足与思考
C4.5虽然改进或者改善了ID3算法的几个主要的问题,仍然有优化的空间。
1)由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,C4.5的剪枝方法有优化的空间。思路主要是两种,一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。后面在下篇讲CART树的时候我们会专门讲决策树的减枝思路,主要采用的是后剪枝加上交叉验证选择最合适的决策树。
2)C4.5生成的是多叉树,即一个父节点可以有多个节点。很多时候,在计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率。
3)C4.5只能用于分类,如果能将决策树用于回归的话可以扩大它的使用范围。
4)C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。如果能够加以模型简化可以减少运算强度但又不牺牲太多准确性的话,那就更好了。
这4个问题在CART树里面部分加以了改进。所以目前如果不考虑集成学习话,在普通的决策树算法里,CART算法算是比较优的算法了。scikit-learn的决策树使用的也是CART算法。在下篇里我们会重点聊下CART算法的主要改进思路,上篇就到这里。下篇请看决策树算法原理(下)。