前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索。
友情提示:本代码用到的网址仅供交流学习使用,如有不妥,请联系删除。
背景:自己有台电脑要给老爸用,老爷子喜欢看一些大片,但是家里网络环境不好,就想批量下载一些存到电脑里。但是目前大部分的网站都是这样的,
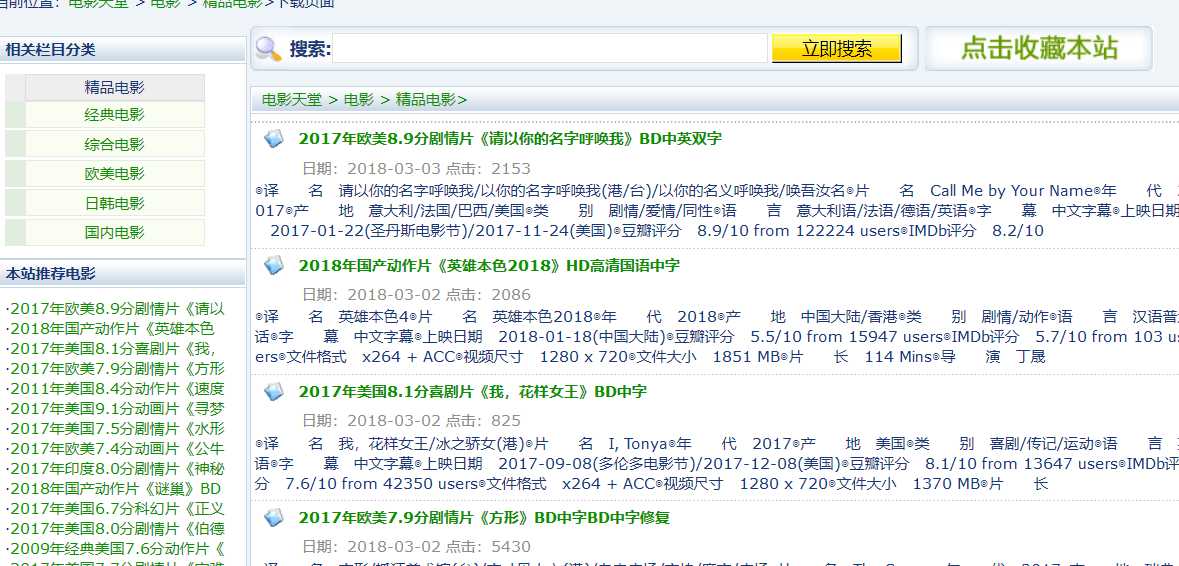
需要一个个地点进去,才能看到下载地址

如果我要下载100部电影,那肯定手都要点断了,于是便想把这些地址给爬取出来,迅雷批量下载。
工具:python(版本3.x)
爬虫原理:网页源代码中含有下载地址,把这些零散的地址批量保存到文件中,方便使用。
干货:首先上代码,迫不及待的你可以先运行一下,再看详细介绍。
import requests import re #changepage用来产生不同页数的链接 def changepage(url,total_page): page_group = [‘https://www.dygod.net/html/gndy/jddy/index.html‘] for i in range(2,total_page+1): link = re.sub(‘jddy/index‘,‘jddy/index_‘+str(i),url,re.S) page_group.append(link) return page_group #pagelink用来产生页面内的视频链接页面 def pagelink(url): base_url = ‘https://www.dygod.net/html/gndy/jddy/‘ headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36‘} req = requests.get(url , headers = headers) req.encoding = ‘gbk‘#指定编码,否则会乱码 pat = re.compile(‘<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>‘,re.S)#获取电影列表网址 reslist = re.findall(pat, req.text) finalurl = [] for i in range(1,25): xurl = reslist[i][0] finalurl.append(base_url + xurl) return finalurl #返回该页面内所有的视频网页地址 #getdownurl获取页面的视频地址 def getdownurl(url): headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36‘} req = requests.get(url , headers = headers) req.encoding = ‘gbk‘#指定编码,否则会乱码 pat = re.compile(‘<a href="ftp(.*?)">ftp‘,re.S)#获取下载地址 reslist = re.findall(pat, req.text) furl = ‘ftp‘+reslist[0] return furl if __name__ == "__main__" : html = "https://www.dygod.net/html/gndy/jddy/index.html" print(‘你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html‘) pages = input(‘请输入需要爬取的页数:‘) p1 = changepage(html,int(pages)) with open (‘电影天堂下载地址.lst‘,‘w‘) as f : j = 0 for p1i in p1 : j = j + 1 print(‘正在爬取第%d页,网址是 %s ...‘%(j,p1i)) p2 = pagelink(p1i) for p2i in p2 : p3 = getdownurl(p2i) if len(p3) == 0 : pass else : finalurl = p3 f.write(finalurl + ‘\n‘) print(‘所有页面地址爬取完毕!‘)
核心模块getdownurl函数:通过requests来获取页面信息,可以认为这个信息的text就是页面源代码(几乎任何一款浏览器右键都有查看网页源代码的选项),再通过re.compile正则表达式匹配的方式来匹配到网页源代码中的网址部分,可以看下图
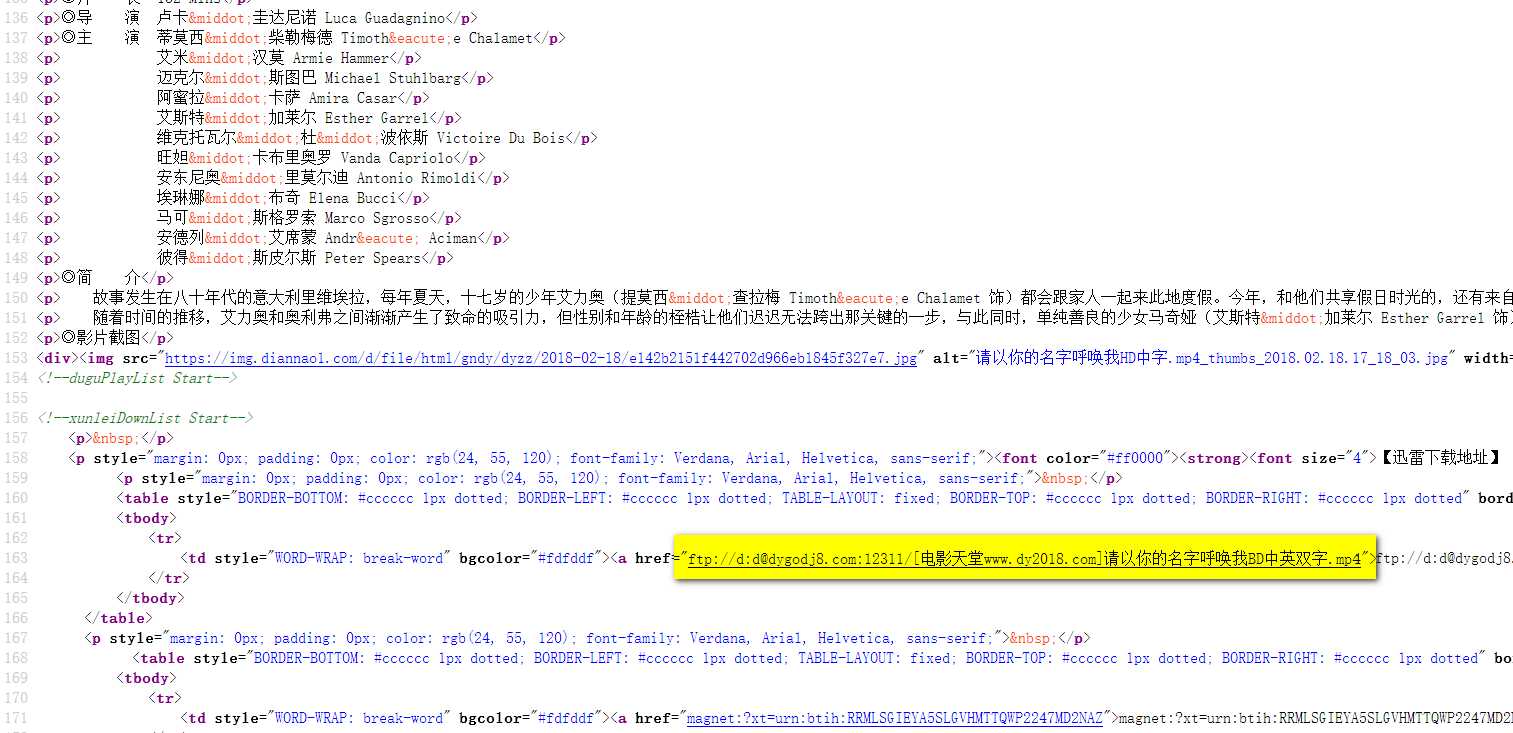
这部分怎么提取呢?通过正则表达式匹配。怎么写这个正则表达式呢?这里用到一个简单粗暴的方法:
<a href="ftp(.*?)">ftp
爬虫中经常用到.*?来做非贪婪匹配(专业名词请百度),你可以简单认为这个(.*?)就代表你想要爬取出来的东西,这样的东西在每个网页源码中都是夹在<a href="ftp和">ftp之间的。有人可能会问,那这个匹配出来的不是网址啊,比如上图中出来的就是://d:d@dygodj8.com:12311/[电影天堂www.dy2018.com]请以你的名字呼唤我BD中英双字.mp4,前面少了个ftp啊?
是的,不过这是故意为之,如果正则表达式写成<a href="(.*?)">ftp,可能夹在<a href="和">ftp之间的东西就太多了,二次处理的成本还不如先用你觉得最快最直接的方式抽取有用信息,然后再进行拼接来得快。
代码详解:
一、getdownurl
#getdownurl获取页面的视频地址 def getdownurl(url): headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36‘} req = requests.get(url , headers = headers) req.encoding = ‘gbk‘#指定编码,否则会乱码 pat = re.compile(‘<a href="ftp(.*?)">ftp‘,re.S)#获取下载地址 reslist = re.findall(pat, req.text) furl = ‘ftp‘+reslist[0] return furl
其中headers是用来将你的脚本访问网址伪装成浏览器访问,以防有些网站进行了反爬虫的措施。这个headers在很多浏览器中也可以很容易得到,以Firefox为例,直接F12或查看元素,在网络标签,右侧的消息头中右下角即可看到。
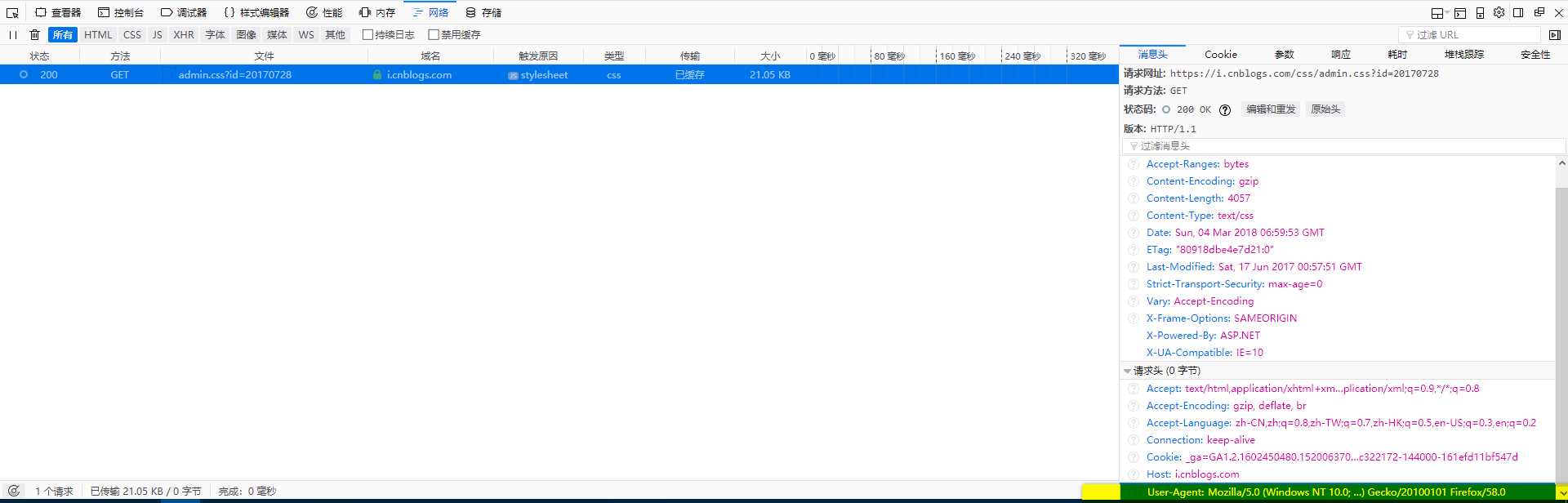
requests模块:requests.get(url , headers = headers)是用伪装成firefox的形式获取该网页的信息。
re模块:可以参考python正则表达式的一些东西,这里用re.complile来写出匹配的模式,re.findall根据模式在网页源代码中找到相应的东西。
二、pagelink
#pagelink用来产生页面内的视频链接页面 def pagelink(url): base_url = ‘https://www.dygod.net/html/gndy/jddy/‘ headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36‘} req = requests.get(url , headers = headers) req.encoding = ‘gbk‘#指定编码,否则会乱码 pat = re.compile(‘<a href="/html/gndy/jddy/(.*?)" class="ulink" title=(.*?)/a>‘,re.S)#获取电影列表网址 reslist = re.findall(pat, req.text) finalurl = [] for i in range(1,25): xurl = reslist[i][0] finalurl.append(base_url + xurl) return finalurl #返回该页面内所有的视频网页地址
第一步getdownurl是用于爬取一个网页的网址,这一步用于获取同一页面内所有网页的网址,像下面的网页包含很多电影链接
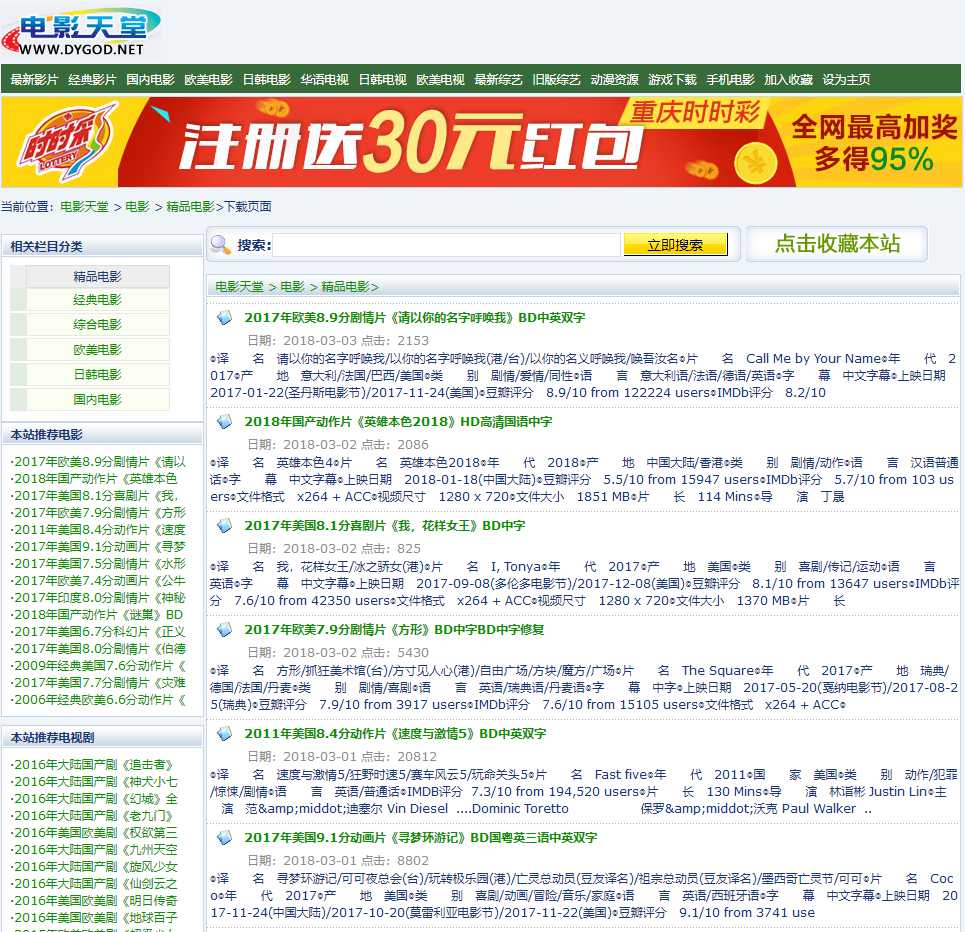
源码是这样的:
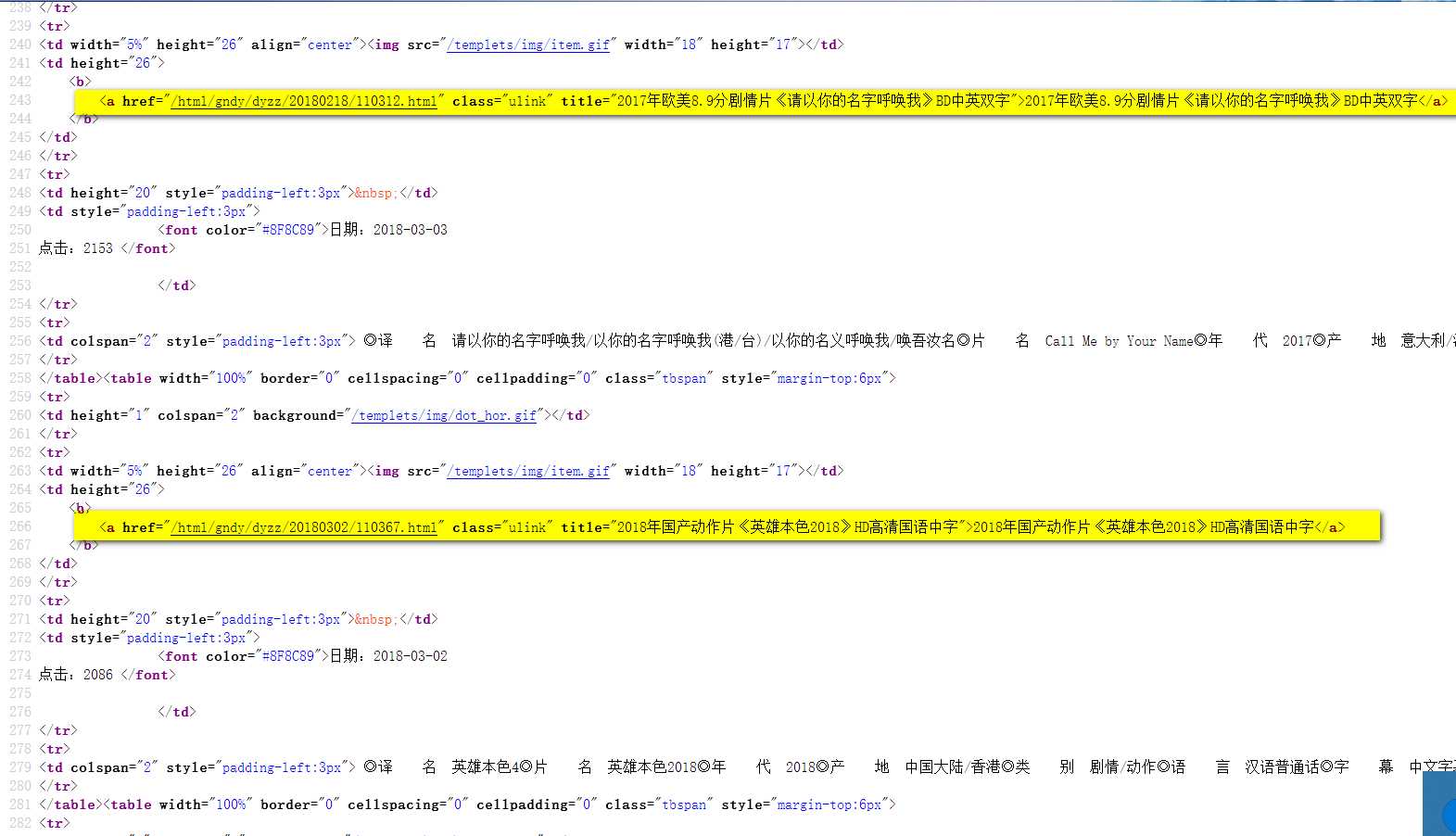
聪明的你一看就知道需要哪些信息,这个页面正文有25个电影链接,我这里用到一个list来存放这些网址,其实range(1,25)不包含25,也就是说我只存放了24个网址,原因是我的正则表达式写的不好,爬出来的第一个网址有问题,如果有兴趣可以研究下怎么完善。
需要一提的是这个正则表达式用到了两处.*?,所以匹配到的reslist是二维的。
三、changepage
#changepage用来产生不同页数的链接 def changepage(url,total_page): page_group = [‘https://www.dygod.net/html/gndy/jddy/index.html‘] for i in range(2,total_page+1): link = re.sub(‘jddy/index‘,‘jddy/index_‘+str(i),url,re.S) page_group.append(link) return page_group
这里也比较简单,点击下一页,抬头看看网址栏的网址是什么,这里是index/index_2/index_3...很容易拼接

四、main
if __name__ == "__main__" : html = "https://www.dygod.net/html/gndy/jddy/index.html" print(‘你即将爬取的网站是:https://www.dygod.net/html/gndy/jddy/index.html‘) pages = input(‘请输入需要爬取的页数:‘) p1 = changepage(html,int(pages)) with open (‘电影天堂下载地址.lst‘,‘w‘) as f : j = 0 for p1i in p1 : j = j + 1 print(‘正在爬取第%d页,网址是 %s ...‘%(j,p1i)) p2 = pagelink(p1i) for p2i in p2 : p3 = getdownurl(p2i) if len(p3) == 0 : pass else : finalurl = p3 f.write(finalurl + ‘\n‘) print(‘所有页面地址爬取完毕!‘)
main里面几乎没什么好说的,反正就是循环读取,再往文件里写进行了。
五、运行及结果
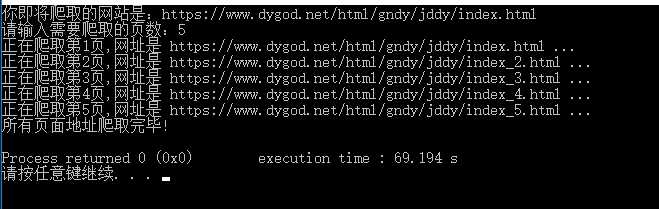
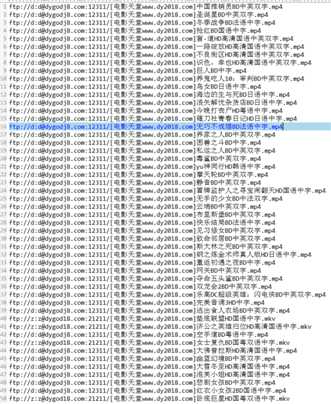
然后迅雷就可以直接导入了。(后缀为downlist或lst迅雷可以直接导入)
后记:有些可能会觉得这样一股脑的把电影都下载下来,可能有些电影太烂,下载下来就是浪费时间和资源,而手工筛选又太费事,后续会通过数据库的方式来存储影片的信息,从而筛选出需要的地址。