数据集下载地址:
视频地址:
一、项目概要
1、应用
模式识别、数据挖掘(核心)、统计学习、计算机视觉、语言识别、自然语言处理
2、模式、流程
训练样本 --> 特征提取 --> 学习函数 --> 预测
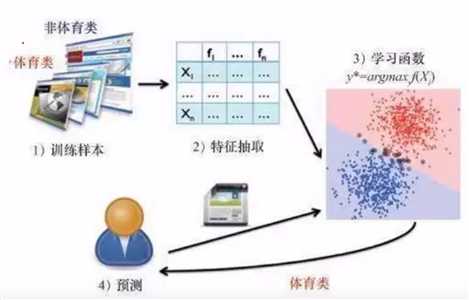
二、Python实践
1、应用的模块
Numpy:科学计算库
pandas:数据分析处理库
Matplotlib:数据可视化库
Scikit-learn:机器学习库
2、数据源处理
① 导入数据:
1 #coding: utf-8 2 import pandas 3 titanic = pandas.read_csv(‘train.csv‘)
② 对缺失数据的列进行填充:
1 #对于缺失的数据进行补充 median 填充中位数 2 titanic[‘Age‘] = titanic[‘Age‘].fillna(titanic[‘Age‘].median())
③ 属性转换,把某些列的字符串值转为数字项:
1 print titanic[‘Sex‘].unique() 2 titanic.loc[titanic[‘Sex‘] == ‘male‘,‘Sex‘] = 0 3 titanic.loc[titanic[‘Sex‘] == ‘female‘,‘Sex‘] = 1 4 5 print titanic[‘Embarked‘].unique() 6 titanic[‘Embarked‘] = titanic[‘Embarked‘].fillna(‘S‘) 7 titanic.loc[titanic[‘Embarked‘] == ‘S‘,‘Embarked‘] = 0 8 titanic.loc[titanic[‘Embarked‘] == ‘C‘,‘Embarked‘] = 1 9 titanic.loc[titanic[‘Embarked‘] == ‘Q‘,‘Embarked‘] = 2
3、建立模型
① 引入机器学习库,核心
1 from sklearn.linear_model import LinearRegression #分类算法 线性回归 2 from sklearn.cross_validation import KFold #交叉验证库,将测试集进行切分验证取平均值
② 实例化模型
1 predictors = [‘Pclass‘,‘Sex‘,‘Age‘,‘SibSp‘,‘Parch‘,‘Fare‘,‘Embarked‘] #用到的特征 2 alg = LinearRegression() #线性回归模型实例化对象 3 kf = KFold(titanic.shape[0],n_folds=3,random_state=1) #将m个平均分成3份进行交叉验证
③ 把数据传入模型 预测结果
1 predictions = [] 2 #for循环: 训练集、测试集、交叉验证 3 for train, test in kf: 4 #print train 5 #print test 6 train_predictors = (titanic[predictors].iloc[train,:]) #将predictors作为测试特征 7 #print train_predictors 8 train_target = titanic[‘Survived‘].iloc[train] 9 #print train_target 10 alg.fit(train_predictors,train_target) #构建线性模型 样本的x(训练数据) 样本的y(标签值) 11 test_prediction = alg.predict(titanic[predictors].iloc[test,:]) #预测结果值 12 predictions.append(test_prediction)
4、算法概率计算
1 import numpy as np 2 #使用线性回归得到的结果是在区间【0,1】上的某个值,需要将该值转换成0或1 3 predictions = np.concatenate(predictions, axis=0) 4 predictions[predictions >.5] = 1 5 predictions[predictions <=.5] = 0 6 accury = sum(predictions[predictions == titanic[‘Survived‘]]) / len(predictions) #测试准确率 进行模型评估 7 print accury #精度值
5、集成算法 构造多个分类树
① 构造多个分类器
1 from sklearn.linear_model import LogisticRegression #逻辑回归 2 from sklearn import cross_validation 3 alg = LogisticRegression(random_state=1) 4 scores = cross_validation.cross_val_score(alg, titanic[predictors],titanic[‘Survived‘],cv=3) 5 print scores.mean()
② 随机森林
1 from sklearn.ensemble import RandomForestClassifier 2 from sklearn import cross_validation 3 predictions = [‘Pclass‘,‘Sex‘,‘Age‘,‘SibSp‘,‘Parch‘,‘Fare‘,‘Embarked‘] 4 # Initialize our algorithm with the default paramters 5 # random_state = 1 表示此处代码多运行几次得到的随机值都是一样的,如果不设置,两次执行的随机值是不一样的 6 # n_estimators 指定有多少颗决策树,树的分裂的条件是: 7 # min_samples_split 代表样本不停的分裂,某一个节点上的样本如果只有2个了 ,就不再继续分裂了 8 # min_samples_leaf 是控制叶子节点的最小个数 9 alg = RandomForestClassifier(random_state=1,n_estimators=100,min_samples_split=4,min_samples_leaf=2) 10 #进行交叉验证 11 kf = cross_validation.KFold(titanic.shape[0],n_folds=3,random_state=1) 12 scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic[‘Survived‘],cv=kf) 13 print scores.mean()
6、特征提取
1 # ## 关于特征提取问题 (非常关键) 2 # - 尽可能多的提取特征 3 # - 看不同特征的效果 4 # - 特征提取是数据挖掘里很- 要的一部分 5 # - 以上使用的特征都是数据里已经有的了,在真实的数据挖掘里我们常常没有合适的特征,需要我们自己取提取 6 ① 把多个特征组合成一个特征 7 titanic[‘Familysize‘] = titanic[‘SibSp‘] + titanic[‘Parch‘] #家庭总共多少人 8 titanic[‘NameLength‘] = titanic[‘Name‘].apply(lambda x: len(x)) #名字的长度 9 import re 10 11 def get_title(name): 12 title_reserch = re.search(‘([A-Za-z]+)\.‘,name) 13 if title_reserch: 14 return title_reserch.group(1) 15 return "" 16 titles = titanic[‘Name‘].apply(get_title) 17 #print pandas.value_counts(titles) 18 19 #将称号转换成数值表示 20 title_mapping = {"Mr":1,"Miss":2,"Mrs":3,"Master":4,"Dr":5,"Rev":6,"Col":7,"Major":8,"Mlle":9,"Countess":10,"Ms":11,"Lady":12,"Jonkheer":13,"Don":14,"Mme":15,"Capt":16,"Sir":17} 21 for k,v in title_mapping.items(): 22 titles[titles==k] = v 23 #print (pandas.value_counts(titles)) 24 titanic["titles"] = titles #添加title特征
② 进行特征选择
1 # 进行特征选择 2 # 特征重要性分析 3 # 分析 不同特征对 最终结果的影响 4 # 例如 衡量age列的重要程度时,什么也不干,得到一个错误率error1, 5 # 加入一些噪音数据,替换原来的值(注意,此时其他列的数据不变),又得到一个一个错误率error2 6 # 两个错误率的差值 可以体现这一个特征的重要性 7 import numpy as np 8 from sklearn.feature_selection import SelectKBest,f_classif#引入feature_selection看每一个特征的重要程度 9 import matplotlib.pyplot as plt 10 11 predictors = [‘Pclass‘,‘Sex‘,‘Age‘,‘SibSp‘,‘Parch‘,‘Fare‘,‘Embarked‘,‘Familysize‘,‘NameLength‘,‘titles‘] 12 selector = SelectKBest(f_classif,k=5) 13 selector.fit(titanic[predictors],titanic[‘Survived‘]) 14 scores = -np.log10(selector.pvalues_)
③用视图的方式展示
1 plt.bar(range(len(predictors)),scores) 2 plt.xticks(range(len(predictors)),predictors,rotation=‘vertical‘) 3 plt.show()
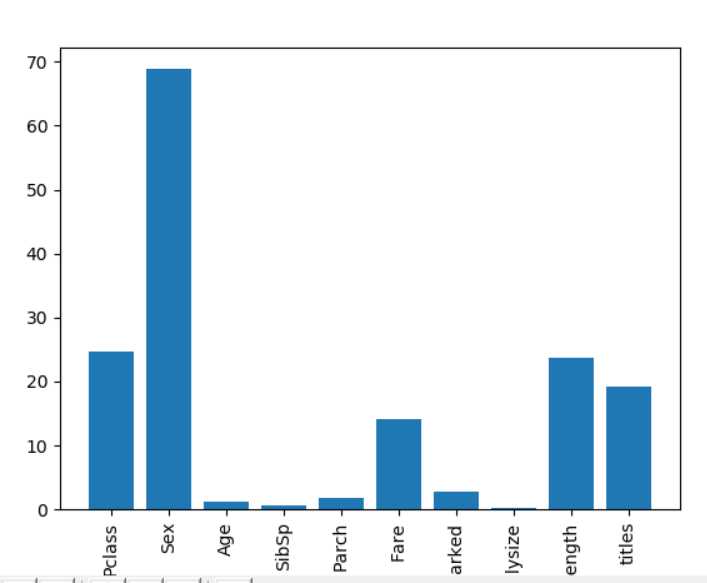
7、集成分类器
1 # 在竞赛中常用的耍赖的办法:集成多种算法,取最后每种算法的平均值,来减少过拟合 2 from sklearn.ensemble import GradientBoostingClassifier 3 import numpy as np 4 # GradientBoostingClassifier也是一种随机森林的算法,可以集成多个弱分类器,然后变成强分类器 5 algorithas = [ 6 [GradientBoostingClassifier(random_state=1,n_estimators=25,max_depth=3),[‘Pclass‘,‘Sex‘,‘Age‘,‘SibSp‘,‘Parch‘,‘Fare‘,‘Embarked‘,‘Familysize‘,‘NameLength‘,‘titles‘]], 7 [LogisticRegression(random_state=1),[‘Pclass‘,‘Sex‘,‘Age‘,‘SibSp‘,‘Parch‘,‘Fare‘,‘Embarked‘,‘Familysize‘,‘NameLength‘,‘titles‘]] 8 ] 9 kf = KFold(titanic.shape[0],n_folds=3,random_state=1) 10 predictions = [] 11 for train, test in kf: 12 train_target = titanic[‘Survived‘].iloc[train] 13 full_test_predictions = [] 14 for alg,predictors in algorithas: 15 alg.fit(titanic[predictors].iloc[train,:],train_target) 16 test_prediction = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1] 17 full_test_predictions.append(test_prediction) 18 test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2 19 test_predictions[test_predictions >.5] = 1 20 test_predictions[test_predictions <=.5] = 0 21 predictions.append(test_predictions) 22 predictions = np.concatenate(predictions,axis=0) 23 accury = sum(predictions[predictions == titanic[‘Survived‘]]) / len(predictions)#测试准确率 24 print accury