本文主要参考《Hadoop应用开发技术详解(作者:刘刚)》
一、工作环境
Windows7: Eclipse + JDK1.8.0
Ubuntu14.04:Hadoop2.9.0
二、准备工作——导入JAR包
1. 建一个Hadoop专用的工作空间
2. 在工作空间的目录下建一个专门用来存放开发MapReduce程序所需的Hadoop依赖的JAR包的文件夹
所需的JAR包在Ubuntu中$HADOOP_HOME/share/hadoop下,将JAR包复制到刚刚建好的文件夹中

需要的JAR包如下,可能有部分重复:
$HADOOP_HOME/share/hadoop/common

$HADOOP_HOME/share/hadoop/hdfs

$HADOOP_HOME/share/hadoop/mapreduce

$HADOOP_HOME/share/hadoop/tools/lib
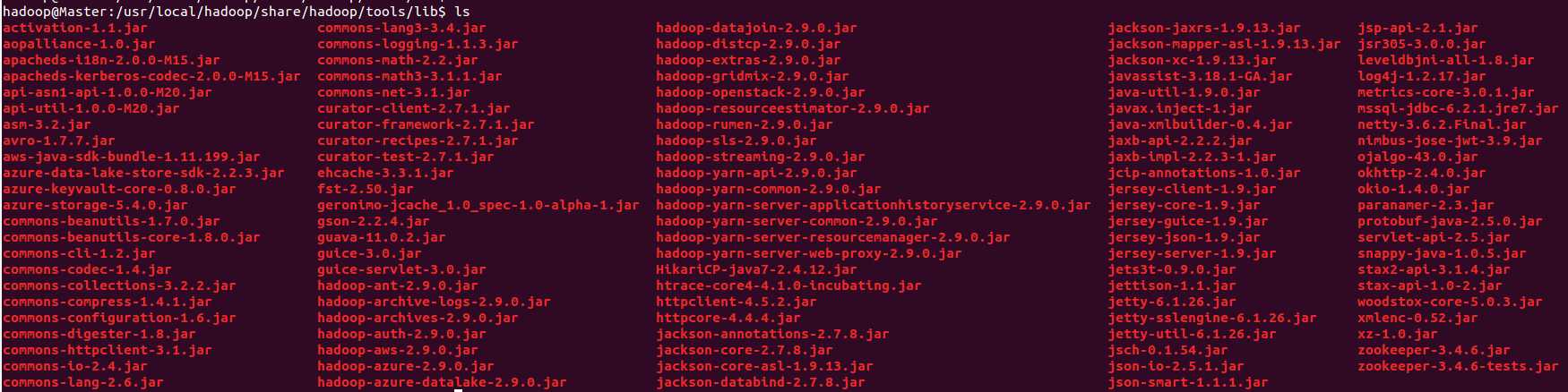
$HADOOP_HOME/share/hadoop/yarn

3. 新建用户库
Windows → Preference → Java → Build Path → User Libraries → New...
看到如下界面:
点击OK后看到如下界面:
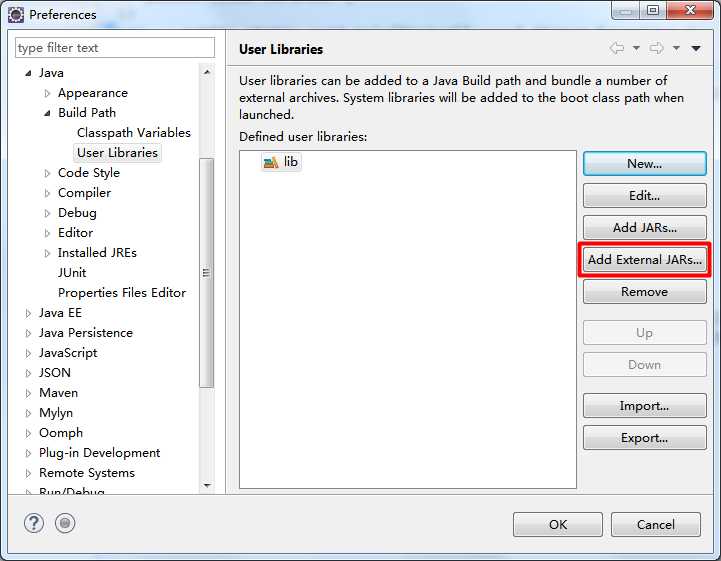
点击Add External JARs... → 在刚刚建好的文件夹中选中所有JAR包 → 打开 → OK
用户库创建成功!
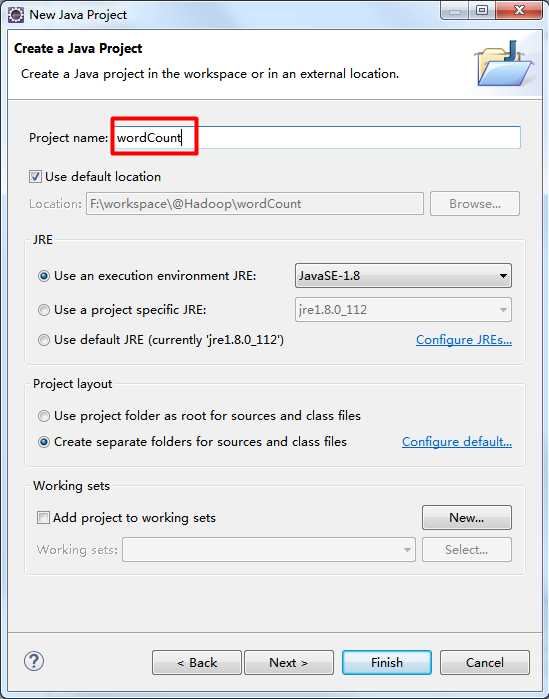
三、创建一个Java工程
File → New → Java Project
除了红框的内容,其他选项默认
右击项目名 → Build Path → Add Libraries... → User Library → 选中建好的用户库
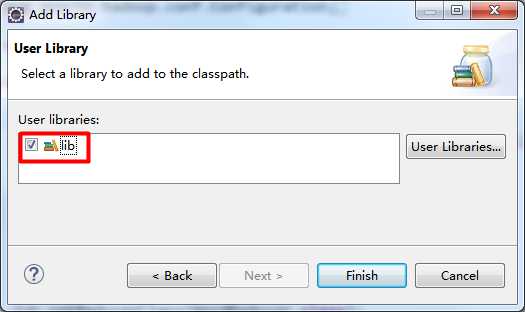
四、MapReduce代码的实现
1. WordMapper类
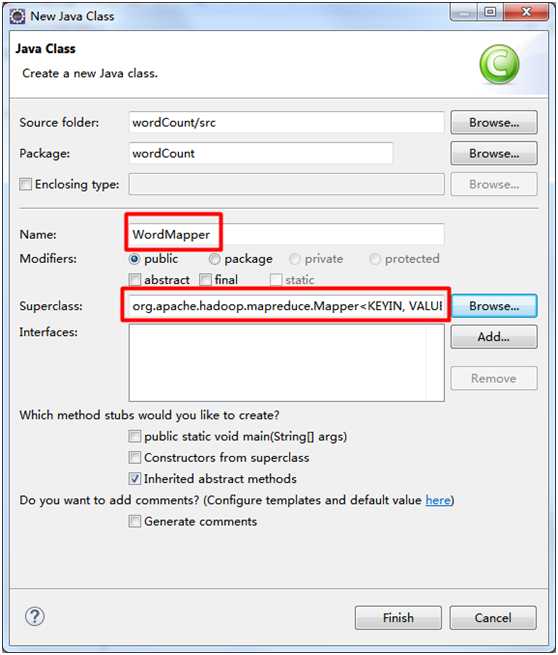
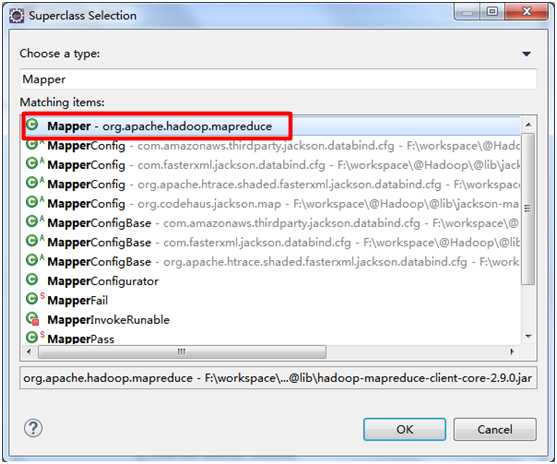
package wordCount; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
2. WordReducer类
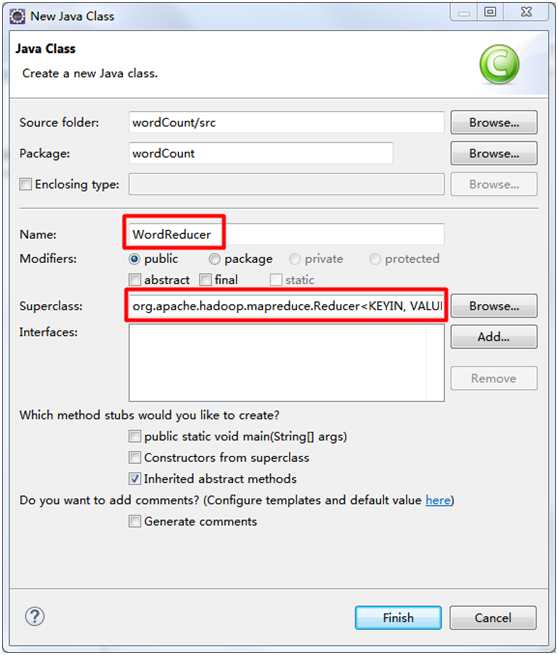
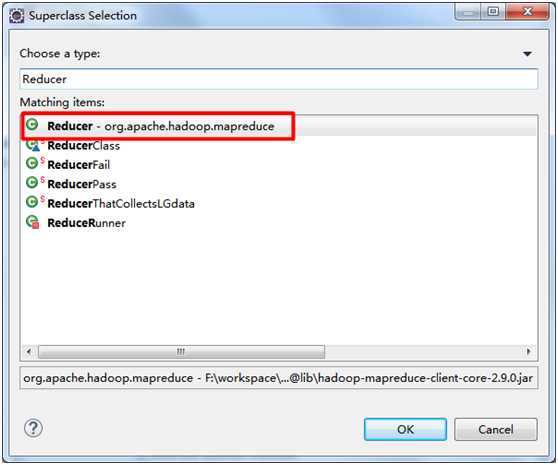
package wordCount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
3. WordMain驱动类
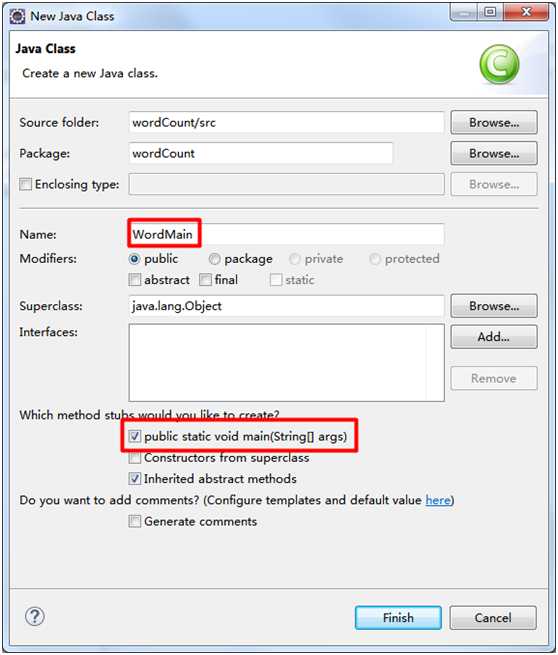
package wordCount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordMain { public static void main(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordCount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordMain.class); job.setMapperClass(WordMapper.class); job.setCombinerClass(WordReducer.class); job.setReducerClass(WordReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
五、打包成JAR文件
右击项目名 → Export → Java → JAR file
看到如下界面:
除了红框的内容,其他选项默认
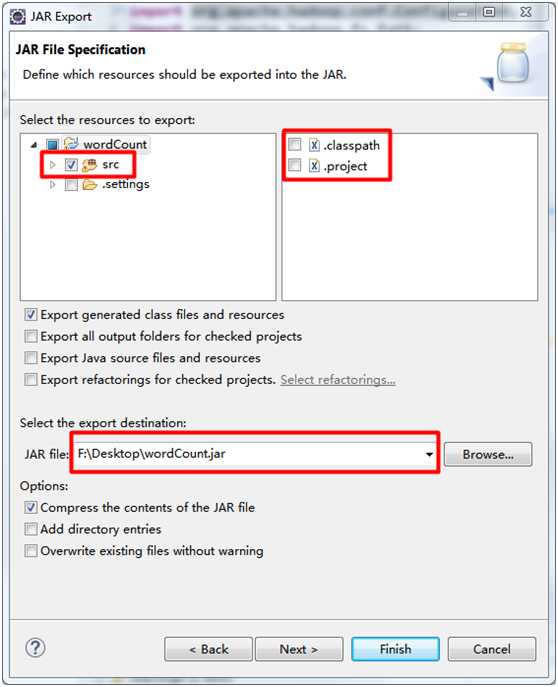
点击Finish
JAR文件生成成功!
六、部署和运行
1. 把刚刚生成的JAR文件发送到Hadoop集群的Master节点的$HADOOP_HOME下面
2. 在Master节点的$HADOOP_HOME下面创建两个待统计词频的文件,file1.txt和file2.txt
file1.txt
Hello, I love coding Are you OK? Hello, I love hadoop Are you OK?
file2.txt
Hello I love coding Are you OK ? Hello I love hadoop Are you OK ?
3. 上传文件到HDFS系统中
$ hdfs dfs -put ./file* input
查看是否上传成功
$ hdfs dfs -ls input
4. 运行程序
$ hdfs dfs -rm -r output #如果HDFS系统中存在output目录 $ hadoop jar wordCount.jar wordCount.WordMain input/file* output
5. 查看运行结果
$ hdfs dfs -cat output/*

以上