Github 源码: https://github.com/SinaHonari/RCN
convnet 存在的问题:
- max-pooling: for tasks requiring precise localization, such as pixel level prediction and segmentation,max-pooling destroys exactly the information required to perform well.
解决方案:summation and concatenation / Recombinator Networks(coarse features inform finer features) - 除去Max-pool,conv也有一定的问题,conv是很好的边缘检测器,所以在检测被遮挡的关键点的时候,会选择离它较近的边。同时,conv不能很好地学习到相对位置关系。所以一般会在conv后接一个结构化的输出。而本问提出了denoising keypoint model 解决这个问题。
解决方案:Denoising keypoint model
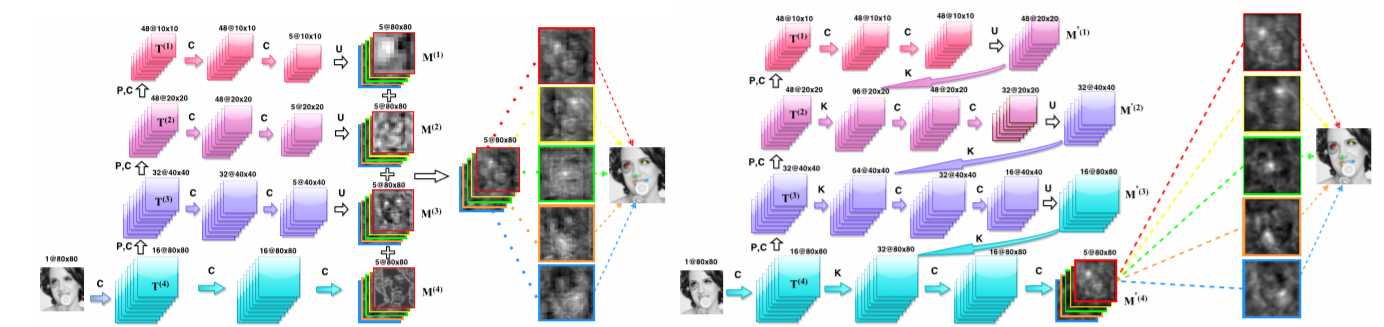
图中,左图是 SumNet,右图是 Recombinator Networks
SumNet:主干是一个卷积加pooling的过程,图像尺度不断减半, 通道数不断增加。然后每一层会有分支,进行卷积操作,最后每一层通过上采样会得到一个5通道的同样大小的feature map,对这些feature map 求一个加权和。
PS:这样加权求和实际上和 concatenation 后加权是一样的。这样就理解了为什么会有 feature map 相加这种操作。
loss function: 交叉熵,L(W)=\frac{1}{N}\sum_{n=1}^N\sum_{k=1}^K -\log P(Y_k=y_k^{(n)}|X=x^{(n)})+\lambda||W||^2
N是训练样本数量,K是关节点个数
SumNet的缺点:SumNet的本意是希望高层的网络能够指导底层的网络提取信息,但是网络只有在最后才融合,信息交流的很晚,所以本文提出了RCN。
The Recombinator Networks: 和SumNet不一样的是,只有在最后一层的时候才进行融合,在之前保留信息的独立性,从而保证信息得到更有效地利用。所以就不停地 concat+upsample
Denoising keypoint model: 专门用一个卷积神经网咯去训练学习关键点之间的相对分布,随机选择一些节点去遮挡,移动,让网络预测所有节点的位置。用这个网络接在RCN后面,将二者求和作为最后的输出。
实验细节:
- 数据增广
- local contrast normalization
- 选择代表性的图像可视化