一:深浅拷贝
1 :浅拷贝
st = [[1,2],‘duke‘,‘haha‘] st1=st.copy() print(st) print(st1) print(id(st1[0])) print(id(st[0])) print(id(st[0][1])) print(id(st1[0][1])) print(id(st[0][0])) print(id(st1[0][0])) st1[0][1]=3 print(st) print(st1) print(id(st1[0])) print(id(st[0])) print(id(st[0][1])) print(id(st1[0][1])) print(id(st[0][0])) print(id(st1[0][0]))
执行结果为:
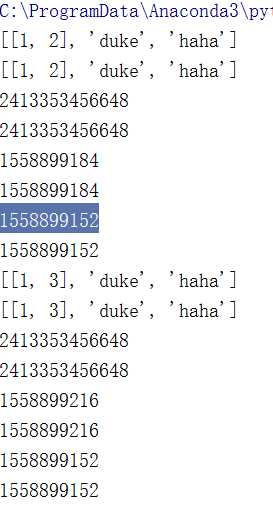 、
、 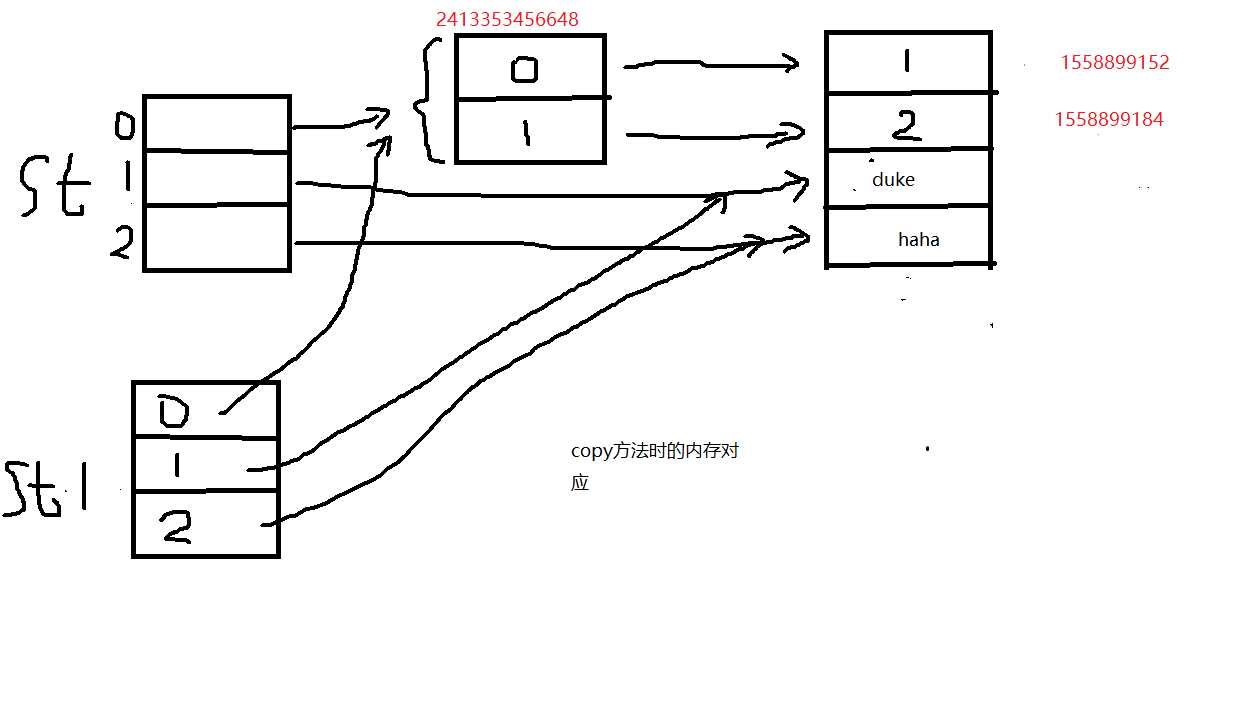
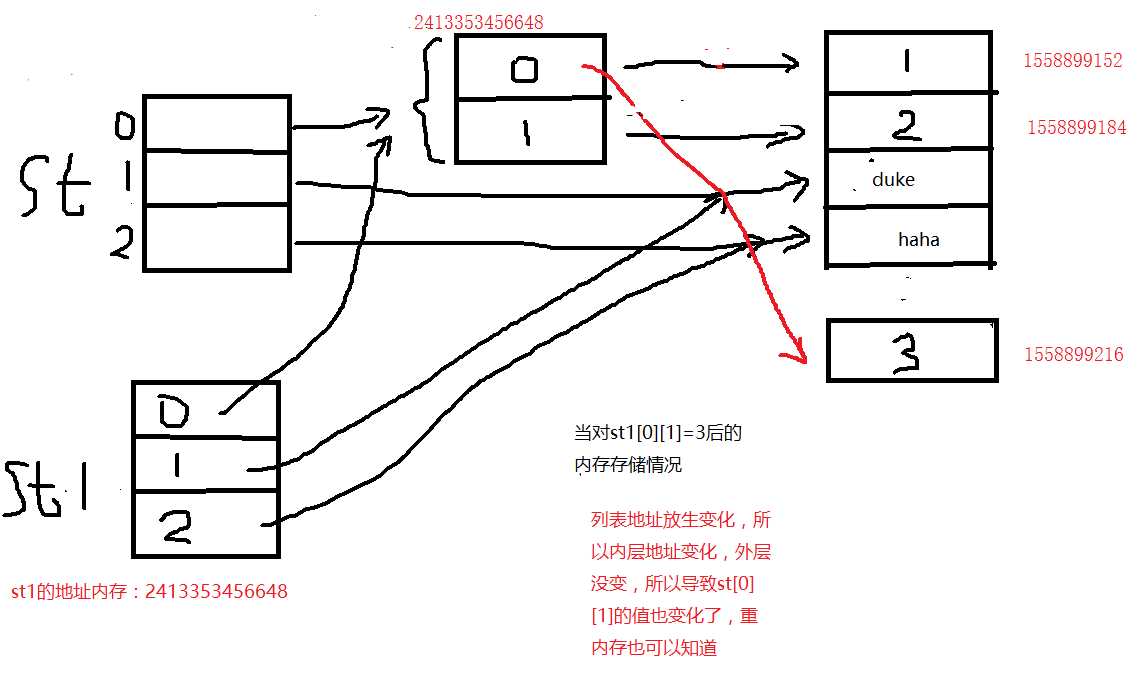
2:深拷贝
import copy duke = ["duke",111,[88888,277272]] wife = duke.copy() #浅拷贝 wife[0] = "xiaomi" wife[1] = 234 xaiohua = copy.deepcopy(duke) #深拷贝 xaiohua[0] = "qinqin" xaiohua[1] = 567 wife[2][1] -= 555 xaiohua[2][1] -= 666 print(duke) print(wife) print(xaiohua)
二:集合
#codeing:UTF-8 #__author__:Duke #date:2018/3/6/006 #set 集合 :将不同的元素组合在一起 #创建 通过关键字 s = set(‘hjsdjhjdsh‘) #注意 集合的元素必须是可以哈希的数据类型 s = list([‘dukehah‘,‘hudshcsuh‘,‘duke‘,‘duke‘]) s = set(s) #会自动去除重复元素 print(s) print(type(s)) #无索引 所以需要迭代器来访问 for i in s: print(i) # 增加元素 s.add(‘w‘) print(s) s.update(‘d‘) print(s) #删除元素的方法 s.pop() s.remove(‘d‘) s.clear() #del s #操作符 #等价 print(set(‘111‘)==set(‘111‘)) #TRUE print(set(‘111‘)==set(‘11‘)) #False #子集 print(set(‘111‘)<set(‘111w‘))#TRUE print(set(‘111U‘)<set(‘111w‘)) #False
a = set([1,2,3,4,5])
b = set([4,5,6,7])
#交集
print(a.intersection(b))
#并集
print(a.union(b))
print(a | b)
#差集
print(a.difference(b)) #in a but not in b
print(a - b )
print(b.difference(a)) #in b but not in a
print( b-a)
#反向交集
print(a.symmetric_difference(b)) #对称差集
print(a ^ b )