本文所使用的查询表来源于oracle数据中scott用户中的emp员工表和dept部门表。
一、基本语法
SQL语句的编写顺序:
select 输出的列 from 表名 where 条件 group by 分组 having 分组之后的条件过滤 order by 排序;
1、伪表(dual):Oracle 对语法要求比较严格,而伪表/虚表主要用于补齐语法结构,如
select 5+5 from dual;
2、别名查询:as关键字,但可省略,如:
select ename as 姓名,job 工作 from emp;
3、去除重复数据:distinct
注意:若是多列去重,必须是每一列都相同才算重复的。
select distinct job,mgr from emp;
4、空值问题
注意:null 值不能参加与SQL四则运算
null值代表不确定的内容,未知的内容,所有值跟null进行比较,结果都为null。
-- 函数: nvl 若参数1为 null ,则返回参数2, 否则返回参数1
select nvl(null,6) from dual; -- 6
select nvl(5,6) from dual; -- 5
5、字符串拼接:
通用 concat(str1,str2) 、Oracle 特有的连接符 ||
select concat(‘abc‘,‘def‘) from dual;
select ‘abc‘||‘def‘||‘xxx‘ from dual;
6、where条件查询
-
- 关系运算符: > >= = < <= != <>
- 逻辑运算符: and or not
- 其它运算符:
- between..and.. 在区间内
- in(集合) 在集合内
- is null
- is not null
- like
- >any(集合) 任意
- >all(集合) 所有
- exists(查询语句)
-- 查询名字在 ‘ALLEN‘,‘BLAKE‘,‘SCOTT‘ 集合内的员工信息
select * from emp where ename in(‘ALLEN‘,‘BLAKE‘,‘SCOTT‘);
7、模糊查询:like
-
- % : 匹配任意个数字符
- _ : 匹配单个字符
- escape 相当于是指定用哪个字符,作为转义字符
-- ‘\‘ 不可作为转义符
select * from emp where ename like ‘%$%%‘ escape ‘$‘;
8、排序:order by
-
- asc : ascend升序 默认
- desc: descend 降序
- nulls first | last
select * from emp order by comm asc nulls first;
二、单行函数
单行函数: 只对一个值进行处理,如字符串函数、数值函数、日期函数等;
1 -- 数值函数: ceil()向上取整, floor()向下取整, mod()取模, abs()取绝对值, round()四舍五入, trunc()截断 2 -- 向上取整 3 select ceil(-11.9) from dual; -- -11-- round 四舍五入 4 select round(45.926,2) from dual; -- 45.93 5 select round(45.926,0) from dual; -- 46 6 select round(45.926,-1) from dual; -- 50 7 -- trunc 截断 8 select trunc(45.926,2) from dual; -- 45.92 9 select trunc(55.926,-2) from dual; -- 0 10 11 -- 字符串函数 12 -- 输出每一个员工 : 姓名:ename 13 select concat(‘姓名:‘,ename) from emp; 14 -- 长度: length 15 select length(‘hello‘) from dual; 16 17 -- 截取字符串 : 注意: 无论是从0还是1开始,都是从第1个字符开始截取 18 select substr(‘abcdefg‘,0,3) from dual; -- abc 19 20 -- 去除空格 21 select trim(‘ abc ‘) from dual; 22 -- 去除字符串两端指定的字符 结果: gao qian jing 23 select trim(‘X‘ from ‘XXXgao qian jingXXXX‘) from dual; 24 -- 替换 25 select replace(‘hello‘,‘l‘,‘x‘) from dual; 26 27 -- 日期函数: 查询当前日期 28 select sysdate from dual; -- 2018/1/31 18:00:03 29 select sysdate+1 from dual; 30 31 -- 查询员工的入职周数 32 select emp.*,(sysdate - hiredate)/7 from emp; 33 -- 查询员工的入职月数 34 select emp.*,months_between(sysdate,hiredate) from emp; 35 -- 查询员工的入职年数 36 select emp.*,months_between(sysdate,hiredate)/12 from emp; 37 -- 三个月的优酷会员 , 计算几个月之后的日期 38 select add_months(sysdate,3) from dual; 39 40 -- 字符串转数值: to_number 鸡肋 41 select ‘10‘ + 24 from dual; -- 34 42 select to_number(‘10‘) + 24 from dual; --34 43 44 -- 数值转字符串: 123 对数值进行格式化处理 45 select concat(123,‘hello‘) from dual; 46 -- yyyy-mm-dd 47 select emp.*,to_char(sal,‘$9999.9‘) from emp; 48 select to_char(1234567,‘$9,999,999.99‘) from dual; 49 50 -- 日期转字符串 51 select to_char(sysdate,‘yyyy-mm-dd hh24:mi:ss‘) from dual; 52 -- 查询年份 53 select to_char(sysdate,‘yyyy‘) from dual; 54 -- 查询月份 55 select to_char(sysdate,‘mm‘) from dual; 56 -- 查询日数 57 select to_char(sysdate,‘dd‘) from dual; 58 select to_char(sysdate,‘d‘) from dual; -- 一个星期的第4天 59 select to_char(sysdate,‘ddd‘) from dual; -- 一年过了几天 60 select to_char(sysdate,‘day‘) from dual; -- wednesday 61 select to_char(sysdate,‘dy‘) from dual; -- wed 62 63 -- 字符转日期 64 select to_date(‘1980-01-31‘,‘yyyy-mm-dd‘) from dual; 65 66 -- nvl(p1,p2) 判断p1是否为null , 若为null, 则返回p2, 否则返回p1 67 -- nvl2(p1,p2,p3) 类似三元运算符 68 select nvl2(null,5,6) from dual; --6 69 select nvl2(1,5,6) from dual; --5
条件表达式:
通用写法:
case 列
when 值1 then 输出
when 值2 then 输出
when 值3 then 输出
else
end;
Oracle特有的写法:
decode(列名,if1,then1,if2,then2,default)
条件表达式使用示例:
1 -- 给员工表所有的员工取一个中文名称 2 select ename,case ename 3 when ‘SMI%TH‘ then ‘曹贼‘ 4 when ‘ALLEN‘ then ‘刘备小儿‘ 5 when ‘MARTIN‘ then ‘诸葛村夫‘ 6 else 7 ‘路人甲‘ 8 end 9 from emp; 10 ------------------------------ 11 select ename, 12 decode(ename,‘SMI%TH‘,‘曹贼‘,‘ALLEN‘,‘刘备小儿‘,‘路人乙‘) 13 from emp; 14 ------------------------------- 15 select emp.*,case 16 when sal<1500 then ‘贫农‘ 17 when sal>=1500 and sal<=3000 then ‘中农‘ 18 else 19 ‘地主‘ 20 end 阶级 21 from emp;
三、多行函数
1、多行/聚合函数: count,max ,min ,avg ,sum
注意: 聚合函数在执行运算的过程中会忽略空值
1 -- 查询所有员工人数 2 select count(*) from emp; 3 4 -- 查询奖金总金额 2200 5 select sum(comm) from emp; 6 7 -- 查询全公司平均奖金 550 8 select avg(comm) from emp; 9 select sum(comm)/count(*) from emp;
2、分组查询
select 分组的条件,分组之后的操作 from 表名 group by 分组条件 having 分组之后的条件过滤
本质: 先对表中数据按照分组的条件进行排序,然后再执行分组之后的运算
注意: 分组查询时: select后面只能输出分组的条件和分组之后的操作
1 -- 查询每个部门的平均工资 2 select deptno,avg(sal) from emp group by deptno; 3 4 -- 查询每个部门的平均工资,并且平均高于2000 5 select deptno,avg(sal) from emp group by deptno having avg(sal)>2000;
3、where 和 having区别
- where 是在分组之前执行的条件过滤, 不能接聚合函数, 可以接单行函数
- having 是分组之后的条件过略,可以接聚合函数
四、多表查询
1、内连接查询
1 -- 同时查询两张表,多表查询, 2 -- 查询出的结果为笛卡尔积:表示的是两张表的乘积,结果没有实际意义 3 select * from emp,dept; 4 5 -- 在笛卡尔积的基础上筛选出有意义的数据 6 -- 隐式内连接 7 select * from emp e,dept d where e.deptno = d.deptno; 8 9 -- 显式内连接: inner join..on.. 10 select * from emp e inner join dept d on e.deptno = d.deptno; 11 12 -- 隐式内连接查询示例 13 -- 查询员工编号,员工姓名,员工的部门名称,工资等级, 经理编号,经理姓名,经理的部门名称,经理的工资等级 14 select e.empno, e.ename,d1.dname, 15 case s1.grade 16 when 1 then ‘一级‘ 17 when 2 then ‘二级‘ 18 when 3 then ‘三级‘ 19 when 4 then ‘四级‘ 20 when 5 then ‘五级‘ 21 end 工资等级, 22 e.mgr, m.ename,d2.dname, 23 case s2.grade 24 when 1 then ‘一级‘ 25 when 2 then ‘二级‘ 26 when 3 then ‘三级‘ 27 when 4 then ‘四级‘ 28 when 5 then ‘五级‘ 29 end 工资等级 30 from emp e, emp m,dept d1,dept d2,salgrade s1,salgrade s2 31 where e.mgr = m.empno 32 and e.deptno = d1.deptno 33 and m.deptno = d2.deptno 34 and e.sal between s1.losal and s1.hisal 35 and m.sal between s2.losal and s2.hisal;
2、外连接查询
标准/通用的写法:
左外连接: 以左表为基础,查询左表中所有的记录以及左表和右表对应的记录,若右表没有对应的记录,则显示null
left outer join..on..
右外连接:以右表为基础,查询右表中所有的记录以及左表和右表对应的记录,若左表没有对应的记录,则显示null
right outer join..on..
Oracle外连接特有的写法:
(+) : 若没有对应的记录,则添加null显示
1 -- 左外连接 2 select * from emp e left outer join dept d on e.deptno = d.deptno; 3 -- 使用Oracle特有写法,查询左外连接的结果 4 select * from emp e,dept d where e.deptno = d.deptno(+); 5 6 -- 右外连接 7 select * from emp e right outer join dept d on e.deptno = d.deptno; 8 -- 使用Oracle特有写法,查询右外连接的结果 9 select * from emp e,dept d where e.deptno(+) = d.deptno; 10 11 -- 扩展: 全外连接 full outer join 12 select * from emp e full outer join dept d on e.deptno=d.deptno;
五、子查询
子查询: 一个查询语句中嵌套另一个查询内容
作用: 解决复杂的查询需求
1、单行子查询:子查询出来的结果只有单个值
操作符: > >= = < <= != <>
1 -- 查询最高工资的员工信息 2 select * from emp where sal = (select max(sal) from emp); 3 -- 查询出比 雇员7654的工资 高,同时 和7788从事相同工作 的员工信息 4 select * from emp where sal > (select sal from emp where empno=7654) and job = (select job from emp where empno=7788);
2、多行子查询:子查询出来的结果有多行
操作符: in any all exists
1 -- 查询所有是领导的员工信息 2 select * from emp where empno =any(select distinct mgr from emp) 3 -- 查询所有不是领导的员工信息 4 -- 注意:子查询中的空值问题 5 select * from emp where empno not in(select distinct mgr from emp where mgr is not null); 6 select * from emp where empno != all(select distinct mgr from emp where mgr is not null);
exists(查询语句):存在的意思
-
- 若查询语句存在结果,则返回true
- 若查询语句不存在结果,则返回false
1 -- 当条件满足时相当于 1=1,不满足时相当于1=2 2 select * from emp where exists(select * from dept where deptno=10); 3 select * from emp where 1=1; 4 5 select * from emp where exists(select * from dept where deptno=100); 6 select * from emp where 1=2;
六、SQL编写顺序与执行顺序
- SQL编写顺序
select..from..where..group by..having..order by..
- SQL执行顺序:
from..where..group by..having..select..order by..
先从表中获取数据,判断是否符合条件,对符合条件的数据就进行分组,分组完后,在组内进行判断是否符合指定条件,筛选出符合条件的数据,根据选择要求进一步筛选出需要的字段,并将所有数据根据规则进行排序。
- 关联子查询与非关联子查询执行顺序
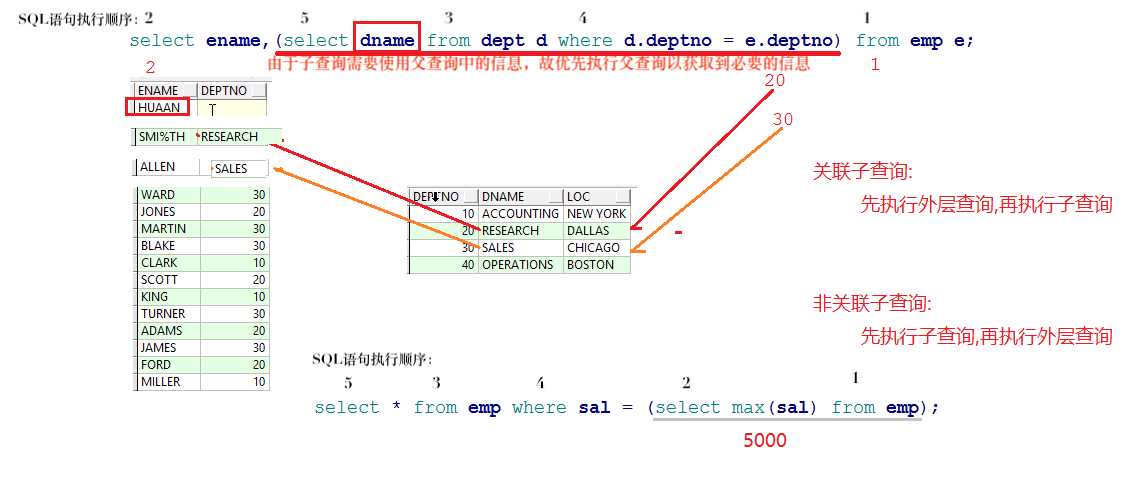
七、伪列(oracle特有)
1、rownum : 伪列/虚列, 表示的行号,主要运用在Oralce分页查询中,借助子查询
每查询出一条满足条件的记录,数据库中默认已经存在rownum,起始值是从1开始的,每输出一条记录,rownum++;
1 -- 查询rownum >5 的所有记录,由于没有输出任何记录,所以rownum并不会自动增长,条件永远不符合,查询出的结果为null 2 select rownum,emp.* from emp where rownum > 5; 3 -- 查询rownum <5 的所有记录,此语句正常输出 4 select rownum,emp.* from emp where rownum < 5; 5 6 -- 查询员工表中工资最高的前三名的员工信息 7 select rownum, empno, ename, sal 8 from (select emp.* from emp order by sal desc) t 9 where rownum <= 3; 10 -- 查询员工表中第5-10的记录 11 -- 先查询前10条记录,查询line >=5 的所有记录 12 select * 13 from (select rownum line, emp.* from emp where rownum <= 10) t 14 where line >= 5;
2、rowid : 伪列, 表示的每行记录在磁盘中存放的物理地址, 主要是运用在索引查询中。
select rowid,emp.* from emp where deptno=20;

当要删除表中重复记录时,可根据指定字段进行分组,查询所有最小rowid,只保留rowid最小的记录,删除掉其他记录即可。
八、集合运算
并集运算: union
应用场景:
数据统计的时候
1997年,公司开发项目记录员工信息
员工编号, 员工姓名, 年龄, 工资, 大哥大
2007年,系统升级,QQ,手机
新的员工表:
员工编号, 员工姓名, 昵称 年龄, 工资,QQ,手机
SQL语句示例:
1 -- 查询工资大于1500, 或者是20号部门下的员工 2 select * from emp where sal > 1500 or deptno = 20; 3 4 -- 并集运算: 去除重复记录 5 select * from emp where sal > 1500 6 union 7 select * from emp where deptno=20; 8 9 -- 并集运算:不去重 10 select * from emp where sal > 1500 11 union all 12 select * from emp where deptno=20; 13 14 -- 交集运算 15 select * from emp where sal > 1500 16 intersect 17 select * from emp where deptno=20; 18 19 -- 差集运算 20 select * from emp where sal > 1500 21 minus 22 select * from emp where deptno=20;
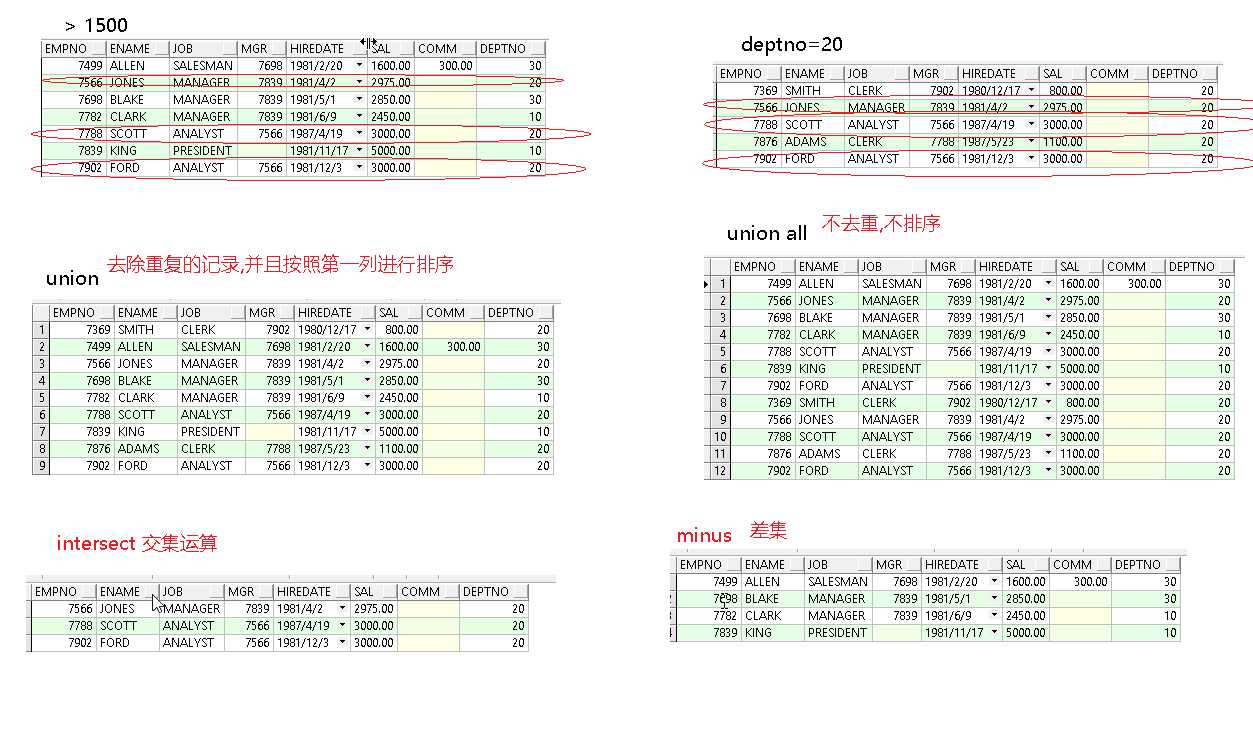
集合运算中的注意事项:
1. 结果集列的数量必须保持一致, 可以使用相同类型或者null补齐
2. 列的类型要保持一致
3. 集合运算的时, 列的含义要相同或者接近
1 select ename,sal from emp where sal > 1500 2 union 3 select ename,sal from emp where deptno=20; 4 5 select ename,sal from emp where sal > 1500 6 union 7 select ename,0 from emp where deptno=20; 8 9 select ename,sal from emp where sal > 1500 10 union 11 select ename,null from emp where deptno=20; 12 13 -- 错误的演示 14 select ename,sal from emp where sal > 1500 15 union 16 select ename,‘没有‘ from emp where deptno=20; 17 18 select ename,sal from emp where sal > 1500 19 union