2018.3.7
一、列表作用
1、去重
去除列表中重复的元素并且变成一个集合list = set(list)
2、关系测试
取list1和list2列表的交集 list1.intersection=(list2)
取list1和list2列表的并集 list1.union=(list2)
取list1和list2列表的差集 list1.difference=(list2)
(取出list1里面有,list2里面没有的)
取list1和list2列表的对称差集
list1.symmetric_difference(list2)
判断list1是否是list2的子集list1.issubset(list2)
判断list1是否是list2的父集list1.issuperset(list2)
判断list1和list2列表是否没有交集list1.isdisjoint(list2)
用运算符表达
交集 list1 & list2 并集 sslist1 | list2
差集 list1 - list2 对称差集list1 ^ list2
集合增删改查
list1.add(999) 集合没有插入,只有增加,并且是无序的
list1.update([888,7,5]) 添加多项
list1.remove(1)删除
判断key是否在字典里 key in list1
判断key是否不是在字典里 key not in list1
二、文件操作
f = open(“yesterday”, ‘a’,encoding = “utf-8”)
文件句柄
a (append)添加
w (write)写,如果文件不存在,创建新文件写入
r+ (读写模式)以读和追加(追加在文件尾)的模式打开
w+ 先创建一个文件,再写,最后再读
rb 二进制读文件
rb应用地方
1、python3.0中网络传输只能用二进制
2、一行一行的读文件,在第二行加入分割线
(f.readlines只适合读小文件)
循环文件读出来,
for index, line in enumerate(f.readlines()):
if index == 2:
print("-----分割线-----")
continue
print(line.strip())
处理大文件,一行一行的读,读完一行就删除
#高级写法
count = 0
for line in f:
if count == 1:
print("-----分割线-----")
count += 1
continue
print(line.strip())
count += 1
f.seek(0)文件光标回到最开始
文件的一些操作
f.name() 文件名字
f.flush() 实时刷新
f.truncate(10) 从第10个字符开始截断,后面的清空
**类似于进度条创建**
import sys,time
sys.stdout.write(‘*’)
sys.stdout.flush()
time.sleep(0.1)
文件修改
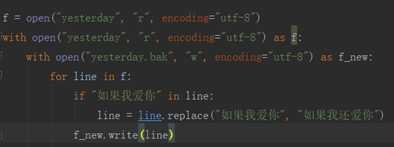
创建一个新文件,再逐行写入,遇到需要修改的地方进行修改再写入,达到修改文件的目的
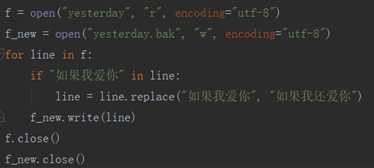
with 语句 (with代码块执行完毕时,内部会自动关闭并释放文件资源)
with open(‘log, r) as f:
三、字符编码与转码
转码先要decode转换成unicode码再encode转换成目标编码形式
例:gbk转utf8
decode(“本身的编码格式”)
encode(“目标编码格式”)
gbk_to_utf8 = s_gbk.decode(“gbk”)
gbk_to_utf8 = gbk_to_gbk.encode(“utf8”)
五、函数与函数式编程
1.面向对象:类(class)
2.面向过程:过程(def)
3.函数式编程:函数(def)
函数是逻辑结构化和过程化的一种编程方法
使用函数的三大特点
1.代码重用 2.保持一致性 3.可扩展
函数返回值:
返回值数=0;返回none
返回值数=1;返回object
返回值数>1;返回tuple
返回值是返回函数执行完毕的结果,用于后面程序执行方式判断
参数:
1.形参和实参
2.位置参数和关键字参数(标准调用:实参位置与形参位置一一对应,关键字调用:位置无固定,关键字必须在位置参数后面)
3.默认参数
4.参数组:*数组名(把N个未知参数转成元组的方式)
**字典名(把N个关键字参数转成字典的方式)
函数内局部变量只能在函数内生效
不应该在函数内部更改全局变量,非要改,用“global 全局变量”
除了字符串和整数不能再函数内改全局变量,列表、字典等都可以更改
*递归*
如果一个函数在内部调用自己,叫递归函数
特性:
1.必须有个明确的结束条件
2.每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3.递归效率不高,递归层次过多会导致栈溢出
*函数式编程*
输入是确定的,输出就是确定的
*高阶函数*
变量可以指向函数,函数的参数能接受变量,那么一个函数可以接收另一个函数作为参数,这种函数就称之为高阶函数
作业:实现删除,创建,查询功能