当一些网站使用了动态加载我们该如何搞定呢?
有两种方法:其一,直接在JavaScript里面采集内容,但是操作起来十分麻烦;其二,使用python的第三方库来运行JavaScript,直接采集你在浏览器里面看到的内容。
这时候就用到了python的一个自动化测试工具Selenium,它可以根据我们的指令,让浏览器自动加载页面,获取所需要的数据。我们直接用命令行就可以安装selenium了:pip install selenium 。但是有一个问题,selenium自己本身是不具备浏览器功能的,需要配合第三方浏览器使用,如PhantomJS。但是,selenium开始渐渐不支持这个内置的无界面浏览器了,我们可以使用chrome来替代,但是需要安装Chromedriver,并添加环境变量。
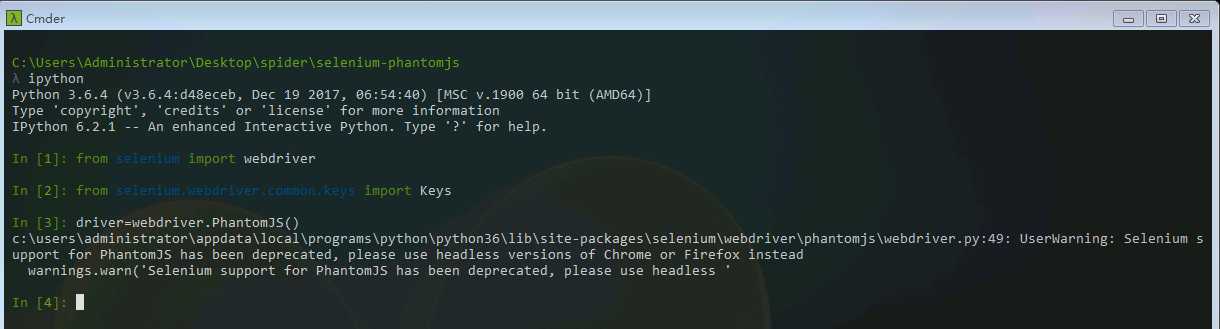
因为我安装的Chromedriver版本太低,所以会出现报错。但是可以看到,成功的打开了谷歌浏览器,并且显示Chrome正在受到自动测试软件的控制。
模拟一个动态网页的加载。
1 #这里是导入python的测试模块 2 import unittest 3 from selenium import webdriver 4 from bs4 import BeautifulSoup 5 6 7 #定义一个类,并且继承测试模块 8 class douyuSelenium(unittest.TestCase): 9 def setUp(self): 10 self.driver=webdriver.PhantomJS() 11 12 #self.driver=webdriver.Chrome() 13 #具体的测试方法,要以test开头 14 def testDouyu(self): 15 self.driver.get("https://www.douyu.com/directory/all") 16 while True: 17 soup=BeautifulSoup(self.driver.page_source,"lxml") 18 titles=soup.find_all(‘h3‘,{‘class‘:‘ellipsis‘}) 19 nums=soup.find_all(‘span‘,{‘class‘:‘dy-num fr‘}) 20 21 for title,num in zip(titles,nums): 22 print(u‘观众人数‘ + num.get_text().strip(),u‘\t房间标题:‘ + title.get_text().strip()) 23 #判断是否到了最后一页 24 if self.driver.page_source.find(‘shark-pager-disable-next‘) !=-1: 25 break 26 #模拟点击 27 self.driver.find_element_by_class_name(‘shark-pager-next‘).click() 28 29 def tearTest(self): 30 print(u‘加载完成。。。‘) 31 self.driver.quit() 32 33 34 if __name__=="__main__": 35 unittest.main()
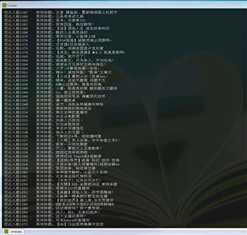
可以看到爬取了房间人数以及标题。