1.概述
Apache Ignite和Apache Arrow很类似,属于大数据范畴中的内存分布式管理系统。在《Apache Arrow 内存数据》中介绍了Arrow的相关内容,它统一了大数据领域各个生态系统的数据格式,避免了序列化和反序列化所带来的资源开销(能够节省80%左右的CPU资源)。今天来给大家剖析下Apache Ignite的相关内容。
2.内容
Apache Ignite是一个以内存为中心的数据平台,具有强一致性、高可用、强大的SQL、K/V以及其所对应的应用接口(API)。结构分布图如下所示:
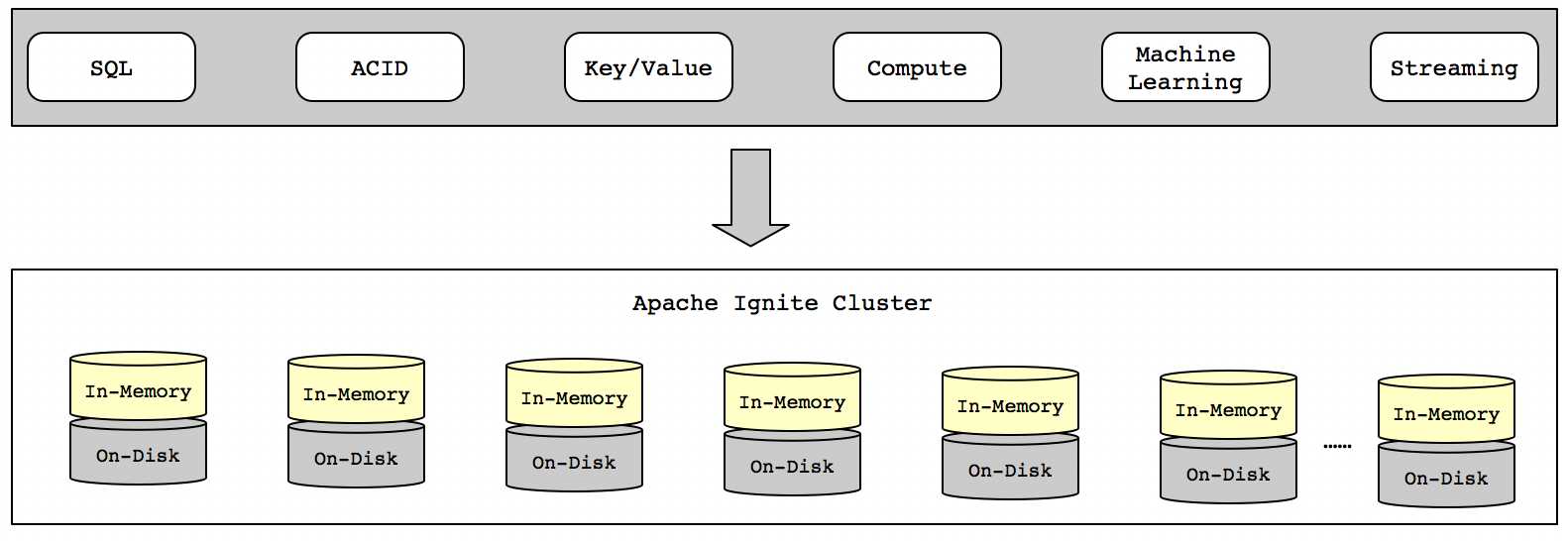
在整个Ignite集群中的多个节点中,Ignite内存中的数据模式有三种,分别是LOCAL、REPLICATED和PARTITIONED。这样增加了Ignite的扩展性,Ignite可以自动化的控制数据如何分区,使用者也可以插入自定义的方法,或是为了提供效率将部分数据并存在一起。
Ignite和其他关系型数据库具有相似的行为,但是在处理约束和索引方面略有不同。Ignite支持一级和二级索引,但是只有一级索引支持唯一性。在持久化方面,Ignite固化内存在内存和磁盘中都能良好的工作,但是持久化到磁盘是可以禁用的,一般将Ignite作为一个内存数据库来使用。
由于Ignite是一个全功能的数据网格,它既可以用于纯内存模式,也可以带有Ignite的原生持久化。同时,它还可以与任何第三方的数据库集成,包含RDBMS和NoSQL。比如,在和Hadoop的HDFS、Kafka等,开发基于大数据平台下的SQL引擎,来操作HDFS、Kafka这类的大数据存储介质。
2.1 内存和磁盘
Apache Ignite是基于固化内存架构的,当Ignite持久化存储特性开启时,它可以在内存和磁盘中存储和处理数据和索引。在固化内存和Ignite持久化存储同时开启时,具有以下优势:
2.1.1 内存优势
- 对外内存
- 避免显著的GC暂停现象
- 自动化碎片清理
- 可预估的内存消耗
- 高SQL性能
2.1.2 磁盘优势
- 可选的持久化
- 支持SSD介质
- 分布式存储
- 支持事物
- 集群瞬时启动
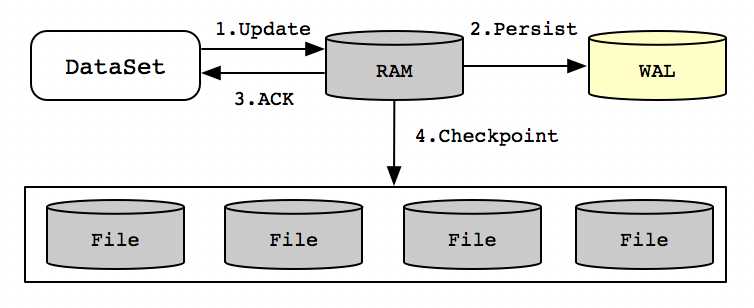
2.2 持久化过程
Ignite的持久化存储时一个分布式的、支持ACID、兼容SQL的磁盘存储。它作为一个可选的磁盘层,可以将数据和索引存储到SSD这类磁盘介质,并且可以透明的与Ignite固化内存进行集成。Ignite的持久化存储具有以下优势:
- 可以在数据中执行SQL操作,不管数据在内存还是在磁盘中,这意味着Ignite可以作为一个经过内存优化的分布式SQL数据库
- 可以不用讲所有的数据和索引保持在内存中,持久化存储可以在磁盘上存储数据的大数据集合,然后只在内存中保持访问频繁的数据子集
- 集群是瞬时启动,如果整个集群宕机,不需要通过预加载数据来对内存进行数据“预热”,只需要将所有集群的节点都连接到一起,整个集群即可正常工作
- 数据和索引在内存和磁盘中以相似的格式进行存储,避免复杂的格式转化,数据集只是在内存和磁盘之间进行移动
持久化流程如下图所示:
2.3 分布式SQL内存数据库
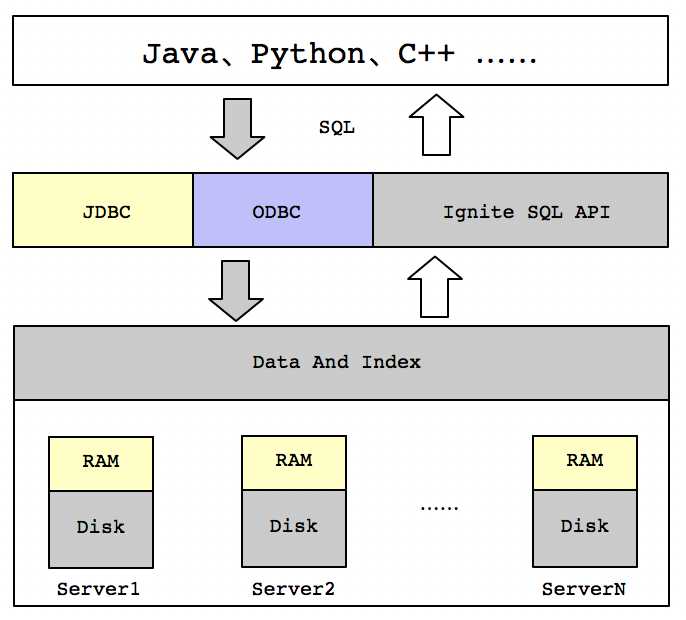
在Apache Ignite中提供了分布式SQL数据库功能,这个内存数据库可以水平扩展、容错且兼容标准的SQL语法,它支持所有的SQL及DML命令,包含SELECT、INSERT、DELETE等SQL命令。依赖于固化内存架构,数据集和索引可以同时在内存和磁盘中进行存储,这样可以跨越不同的存储层执行分布式SQL操作,来获得可以固化到磁盘的内存级性能。可以使用Java、Python、C++等原生的API来操作SQL与Ignite进行数据交互,也可以使用Ignite的JDBC或者ODBC驱动,这样就具有了真正意义上的跨平台连接性。具体架构体系,如下图所示:
3.代码实践
了解Apache的作用后,下面我们可以通过模拟编写一个大数据SQL引擎,来实现对Kafka的Topic的查询。首先需要实现一个KafkaSqlFactory的类,具体实现代码如下所示:
/**
* TODO
*
* @author smartloli.
*
* Created by Mar 9, 2018
*/
public class KafkaSqlFactory {
private static final Logger LOG = LoggerFactory.getLogger(KafkaSqlFactory.class);
private static Ignite ignite = null;
private static void getInstance() {
if (ignite == null) {
ignite = Ignition.start();
}
}
private static IgniteCache<Long, TopicX> processor(List<TopicX> collectors) {
getInstance();
CacheConfiguration<Long, TopicX> topicDataCacheCfg = new CacheConfiguration<Long, TopicX>();
topicDataCacheCfg.setName(TopicCache.NAME);
topicDataCacheCfg.setCacheMode(CacheMode.PARTITIONED);
topicDataCacheCfg.setIndexedTypes(Long.class, TopicX.class);
IgniteCache<Long, TopicX> topicDataCache = ignite.getOrCreateCache(topicDataCacheCfg);
for (TopicX topic : collectors) {
topicDataCache.put(topic.getOffsets(), topic);
}
return topicDataCache;
}
public static String sql(String sql, List<TopicX> collectors) {
try {
IgniteCache<Long, TopicX> topicDataCache = processor(collectors);
SqlFieldsQuery qry = new SqlFieldsQuery(sql);
QueryCursor<List<?>> cursor = topicDataCache.query(qry);
for (List<?> row : cursor) {
System.out.println(row.toString());
}
} catch (Exception ex) {
LOG.error("Query kafka topic has error, msg is " + ex.getMessage());
} finally {
close();
}
return "";
}
private static void close() {
try {
if (ignite != null) {
ignite.close();
}
} catch (Exception ex) {
LOG.error("Close Ignite has error, msg is " + ex.getMessage());
} finally {
if (ignite != null) {
ignite.close();
}
}
}
}
然后,模拟编写一个生产者来生产数据,并查询数据集,实现代码如下所示:
public static void ignite(){
List<TopicX> collectors = new ArrayList<>();
int count = 0;
for (int i = 0; i < 10; i++) {
TopicX td = new TopicX();
if (count > 3) {
count = 0;
}
td.setPartitionId(count);
td.setOffsets(i);
td.setMessage("hello_" + i);
td.setTopicName("test");
collectors.add(td);
count++;
}
String sql = "select offsets,message from TopicX where offsets>6 and partitionId in (0,1) limit 1";
long stime = System.currentTimeMillis();
KafkaSqlFactory.sql(sql, collectors);
System.out.println("Cost time [" + (System.currentTimeMillis() - stime) / 1000.0 + "]ms");
}
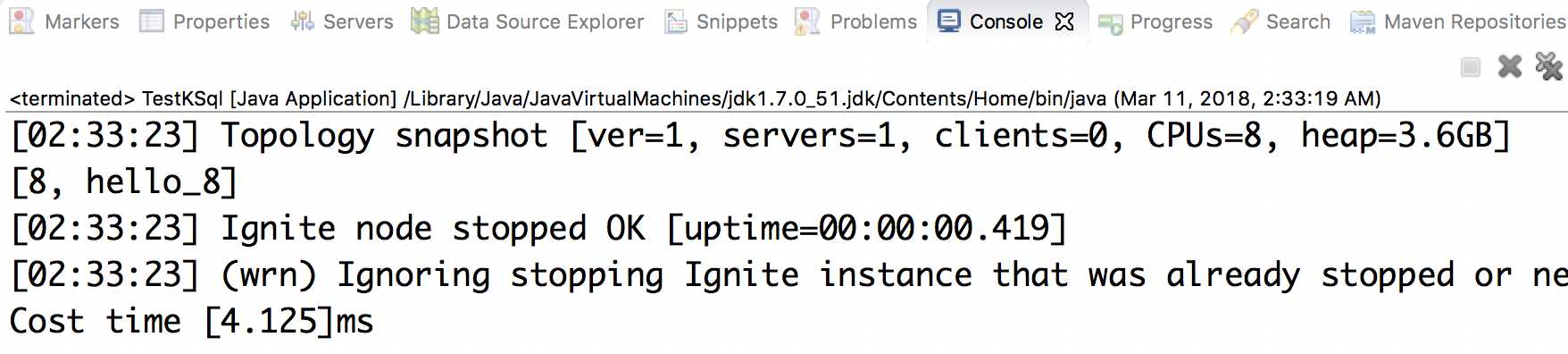
执行结果如下所示:
4.总结
Apache Ignite整体来说,它基本把现在分布式的一些概念都集成了,包含分布式存储、分布式计算、分布式服务、流式计算等等。而且,它对Java语言的支持,与JDK能够很好的整合,能够很友好的兼容JDK的现有API,当你开启一个线程池,你不需要关系是本地线程池还是分布式线程池,只管提交任务就行。Apache Ignite在与RDBMS、Hadoop、Spark、Kafka等传统关系型数据库和主流大数据套件的集成,提供了非常灵活好用的组件API。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!