[TOC]
一、简介
MongoDB目前3大核心优势:『灵活模式』+ 『高可用性』 + 『可扩展性』,通过json文档来实现灵活模式,通过复制集来保证高可用,通过Sharded cluster来保证可扩展性。
MongoDB 分片集群Sharded Cluster通过将数据分散存储到多个分片(Shard)上来实现高可扩展性。
当MongoDB复制集遇到下面的业务场景时,你就需要考虑使用Sharded cluster
- 存储容量需求超出单机磁盘容量
- 活跃的数据集超出单机内存容量,导致很多请求都要从磁盘读取数据,影响性能
- 写IOPS超出单个MongoDB节点的写服务能力
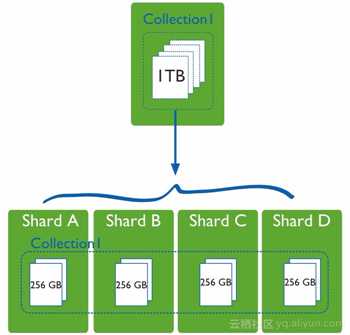
如上图所示,Sharding Cluster使得集合的数据可以分散到多个Shard(复制集或者单个Mongod节点)存储,使得MongoDB具备了横向扩展(Scale out)的能力,丰富了MongoDB的应用场景。
二、分片集群
实现分片集群时,MongoDB 引入 Config Server 来存储集群的元数据,引入 mongos 作为应用访问的入口,mongos 从 Config Server 读取路由信息,并将请求路由到后端对应的 Shard 上。
Diagram of a sample sharded cluster for production purposes. Contains exactly 3 config servers, 2 or more mongos query routers, and at least 2 shards. The shards are replica sets.
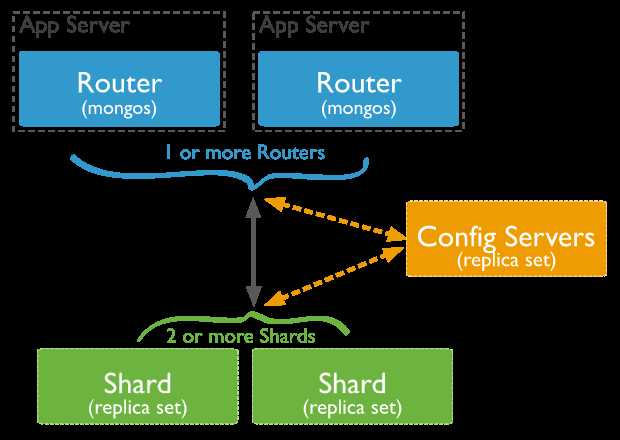
角色说明
A.数据分片(Shards)
用来保存数据,保证数据的高可用性和一致性。可以是一个单独的mongod实例,也可以是一个副本集。
在生产环境下Shard一般是一个Replica Set,以防止该数据片的单点故障。所有Shard中有一个PrimaryShard,里面包含未进行划分的数据集合:
B.配置服务器(Config servers)
保存集群的元数据(metadata),包含各个Shard的路由规则。
C.查询路由(Query Routers)
Mongos是Sharded cluster的访问入口,其本身并不持久化数据(Sharded cluster所有的元数据都会存储到Config Server,而用户的数据则会分散存储到各个shard)
Mongos启动后,会从config server加载元数据,开始提供服务,将用户的请求正确路由到对应的Shard
Sharding集群可以有一个mongos,也可以有多mongos以减轻客户端请求的压力。
三、数据分布策略
Sharded cluster支持将单个集合的数据分散存储在多个shard上,用户可以指定根据集合内文档的某个字段即shard key来分布数据,
目前主要支持2种数据分布的策略,范围分片(Range based sharding)或hash分片(Hash based sharding)。
范围分片
Diagram of the shard key value space segmented into smaller ranges or chunks.
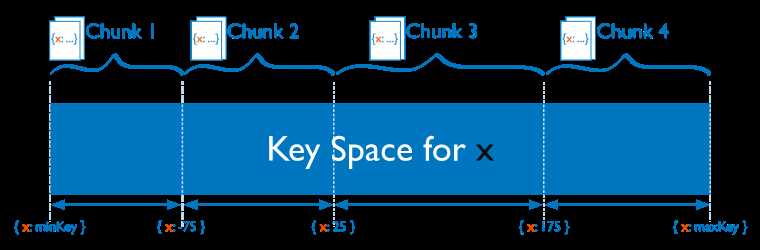
如上图所示,集合根据x字段来分片,x的取值范围为[minKey, maxKey](x为整型,这里的minKey、maxKey为整型的最小值和最大值),将整个取值范围划分为多个chunk,每个chunk(通常配置为64MB)包含其中一小段的数据。
Chunk1包含x的取值在[minKey, -75)的所有文档,而Chunk2包含x取值在[-75, 25)之间的所有文档... 每个chunk的数据都存储在同一个Shard上,每个Shard可以存储很多个chunk,chunk存储在哪个shard的信息会存储在Config server种,mongos也会根据各个shard上的chunk的数量来自动做负载均衡。
范围分片能很好的满足『范围查询』的需求,比如想查询x的值在[-30, 10]之间的所有文档,这时mongos直接能将请求路由到Chunk2,就能查询出所有符合条件的文档。
范围分片的缺点在于,如果shardkey有明显递增(或者递减)趋势,则新插入的文档多会分布到同一个chunk,无法扩展写的能力,比如使用_id作为shard key,而MongoDB自动生成的id高位是时间戳,是持续递增的。
HASH分片
Hash分片是根据用户的shard key计算hash值(64bit整型),根据hash值按照『范围分片』的策略将文档分布到不同的chunk。
Diagram of the hashed based segmentation.
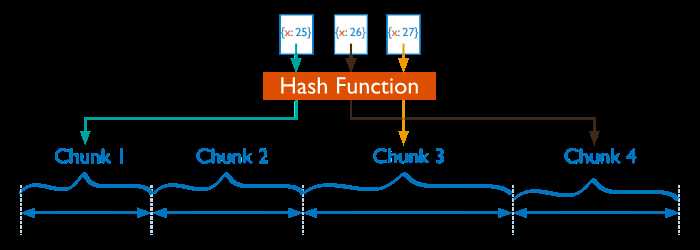
Hash分片与范围分片互补,能将文档随机的分散到各个chunk,充分的扩展写能力,弥补了范围分片的不足,但不能高效的服务范围查询,所有的范围查询要分发到后端所有的Shard才能找出满足条件的文档。
合理的选择shard key
选择shard key时,要根据业务的需求及『范围分片』和『Hash分片』2种方式的优缺点合理选择,同时还要注意shard key的取值一定要足够多,否则会出现单个jumbo chunk,即单个chunk非常大并且无法分裂(split);比如某集合存储用户的信息,按照age字段分片,而age的取值非常有限,必定会导致单个chunk非常大。
四、Mongos访问模式
所有的请求都由mongos来路由、分发、合并,这些动作对客户端driver透明,用户连接mongos就像连接mongod一样使用。
Mongos会根据请求类型及shard key将请求路由到对应的Shard,因此不同的操作请求存在不同限制。
查询请求
查询请求不包含shard key,则必须将查询分发到所有的shard,然后合并查询结果返回给客户端
查询请求包含shard key,则直接根据shard key计算出需要查询的chunk,向对应的shard发送查询请求插入请求
写操作必须包含shard key,mongos根据shard key算出文档应该存储到哪个chunk,然后将写请求发送到chunk所在的shard。更新/删除请求
更新、删除请求的查询条件必须包含shard key或者_id,如果是包含shard key,则直接路由到指定的chunk,如果只包含_id,则需将请求发送至所有的shard。其他命令请求
除增删改查外的其他命令请求处理方式都不尽相同,有各自的处理逻辑,比如listDatabases命令,会向每个Shard及Config Server转发listDatabases请求,然后将结果进行合并。
如何连接
一个典型的ConnectURI 结构如下:
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
//说明
- mongodb:// 前缀,代表这是一个Connection String;
- username:password@ 如果启用了鉴权,需要指定用户密码;
- hostX:portX多个 mongos 的地址列表;
- /database鉴权时,用户帐号所属的数据库;
- ?options 指定额外的连接选项,比如指定readPreference=secondaryPreferred实现读写分离分片集群可以提供多个 mongos 实现现负载均衡;而当某个 mongos 故障时,客户端也能自动进行 failover,将请求都分散到状态正常的 mongos 上。
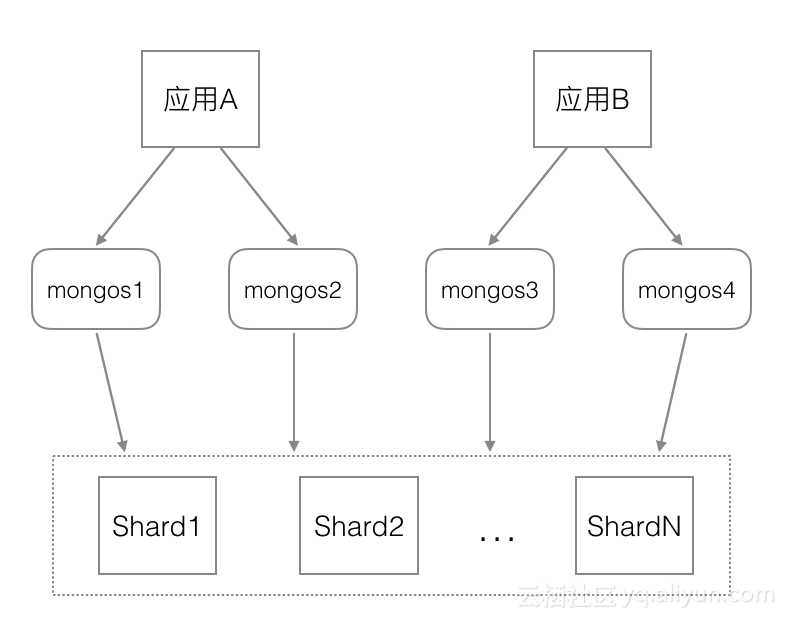
当 mongos 数量很多时,还可以按应用来将 mongos 进行分组,比如有2个应用 A、B、有4个 mongos,可以让应用 A 访问 mongos 1-2(URI 里只指定 mongos 1-2 的地址),
应用 B 来访问 mongos 3-4(URI 里只指定 mongos 3-4 的地址),根据这种方法来实现应用间的访问隔离(应用访问的 mongos 彼此隔离,但后端 Shard 仍然是共享的),如下图
五、Config元数据
Config server存储Sharded cluster的所有元数据,所有的元数据都存储在config数据库,
3.2版本后,Config Server可部署为一个独立的复制集,极大的方便了Sharded cluster的运维管理。
config数据集合如下表所示:
| 集合名称 | 说明 |
|---|---|
| config.shards | 存储各个Shard的信息,可通过addShard、removeShard命令来动态的从Sharded cluster里增加或移除shard |
| config.databases | 存储所有数据库的信息,包括DB是否开启分片,primary shard信息,对于数据库内没有开启分片的集合,所有的数据都会存储在数据库的primary shard上 |
| config.colletions | 数据分片是针对集合维度的,某个数据库开启分片功能后,如果需要让其中的集合分片存储,则需调用shardCollection命令来针对集合开启分片。 |
| config.chunks | 集合分片开启后,默认会创建一个新的chunk,shard key取值[minKey, maxKey]内的文档(即所有的文档)都会存储到这个chunk。当使用Hash分片策略时,可以预先创建多个chunk,以减少chunk的迁移 |
| config.settings | 存储sharded cluster的配置信息,比如chunk size,是否开启balancer等 |
| config.tags | 主要存储sharding cluster标签(tag)相关的你洗,以实现根据tag来分布chunk的功能 |
| config.changelog | 主要存储sharding cluster里的所有变更操作,比如balancer迁移chunk的动作就会记录到changelog里。 |
| config.mongos | 存储当前集群所有mongos的信息 |
| config.locks | 存储锁相关的信息,对某个集合进行操作时,比如moveChunk,需要先获取锁,避免多个mongos同时迁移同一个集合的chunk。 |
六、分片均衡
Mongodb 实现了自动分片均衡,均衡器是一个在后台对分片chunk进行监控的进程,当某个shard的chunks差异数量到达阈值时,将自动开始在shard中间迁移chunk数据库以达到均衡目的。整个迁移过程对应用层是透明的,从3.4版本开始,均衡器不再由Mongos执行,而是由Config副本集的主节点来处理。
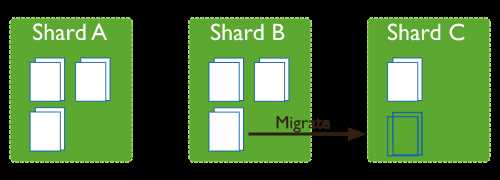
迁移过程中对集群性能存在一定影响,因此一般可以通过设置均衡窗口对齐到业务闲时段。
阈值参考表
|Number of Chunks| Migration Threshold|
|-|-|
|Fewer than 20| 2||
|20-79| 4|
|80 and greater| 8|
迁移过程
- 均衡器向源shard发送moveChunk命令;
- 源shard执行内部的moveChunk流程,过程中数据操作仍然指向当前shard
- 目标shard构建缺失的索引;
- 目标shard请求并接收chunk副本数据;
- 在chunk接收到后,目标shard向源shard确认是否存在增量更新数据,若存在则继续同步;
- 完全同步后,源shard通知config副本集更新元数据库,将chunk的位置更新为目标shard
- 在更新完元数据库后并确保没有关联cursor的情况下,源shard删除被迁移的chunk副本。
参考文档
mongodb shard cluster原理
http://www.mongoing.com/archives/2782
mongo中文社区-高可用mongodb集群
https://yq.aliyun.com/articles/61516
官网-mongodb分片集群
https://docs.mongodb.com/manual/core/sharding-balancer-administration/