在获取网站真是图片的时候,经常遇到图片链接残缺问题。
例如下图所示的情况:
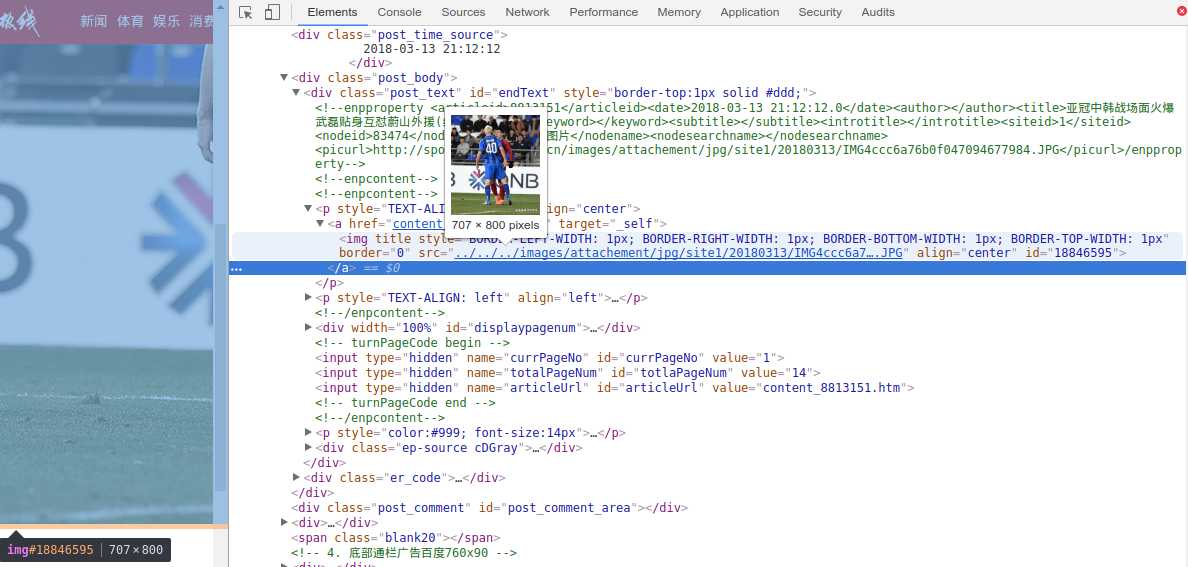
img标签中的图片链接是残缺的,如果这个网站域名又是多种情况的话,比如
http://sports.online.sh.cn/content/2018-03/13/content_8813151.htm
http://sports.online.sh.cn/images/attachement/jpg/site1/20180313/IMG4ccc6a76b0f047094677984.JPG
http://shenhua.online.sh.cn/content/2018-03/13/content_8813187.htm
http://shenhua.online.sh.cn/images/attachement/jpg/site1/20180313/IMGd43d7e5f35354709509383.JPG
这两条新闻是同一个网站的,但是不同的新闻页面,图片的链接又是残缺的,如何获取真正的图片链接呢?
首先,我们需要判断当前页的域名。将鼠标移至图片残缺url上面就会看到完整的url链接。一般残缺图片链接的缺失部分,正是网址栏中的域名部分。
之后,我们就可以在代码中进行判断,如:
def parse_item(self, response, spider):
self.item = self.load_item(response)
if ‘sports‘ in response.url:
self.item[‘content‘] = self.item[‘content‘].replace(‘../../../images‘, ‘http://sports.online.sh.cn/images‘)
elif ‘shenhua‘ in response.url:
self.item[‘content‘] = self.item[‘content‘].replace(‘../../../images‘, ‘http://shenhua.online.sh.cn/images‘)
yield self.item
~上面使用成员操作符 in来查找相应的域名,是较为实用简单的判断方法,相同的做用判断还可以用以下几种方法来实现:
~使用string模块的index()/rindex()方法
index()/rindex()方法跟find()/rfind()方法一样,只不过找不到子字符串的时候会报一个ValueError异常。
import string
def find_string(s,t):
try:
string.index(s,t)
return True
except(ValueError):
return False
s=‘nihao,shijie‘
t=‘nihao‘
result = find_string(s,t)
print result #True
~使用字符串对象的find()/rfind()、index()/rindex()和count()方法
>>> s=‘nihao,shijie‘
>>> t=‘nihao‘
>>> result = s.find(t)>=0
>>> print result
True
>>> result=s.count(t)>0
>>> print result
True
>>> result=s.index(t)>=0
>>> print result
True