jdk1.8.0_144
本文阅读最好先了解HashMap底层,可前往《Java集合中的HashMap类》。
LinkedHashMap由于它的插入有序特性,也是一种比较常用的Map集合。它继承了HashMap,很多方法都直接复用了父类HashMap的方法。本文将探讨LinkedHashMap的内部实现,以及它是如何保证插入元素是按插入顺序排序的。
在分析前可以先思考下,既然是按照插入顺序,并且以Linked-开头,就很有可能是链表实现。如果纯粹以链表实现,也不是不可以,LinkedHashMap内部维护一个链表,插入一个元素则把它封装成Entry节点,并把它插入到链表尾部。功能可以实现,但这带来的查找效率达到了O(n),显然远远大于HashMap在没有冲突的情况下O(1)的时间复杂度。这就丝毫不能体现出Map这种数据结构随机存取快的优点。
所以显然,LinkedHashMap不可能只有一个链表来维护Entry节点,它极有可能维护了两种数据结构:散列表+链表。
为便于理解,将不会分析每个方法,会从插入开始分析LinkedHashMap的数据结构及实现。
LinkedHashMap继承了HashMap类,并且没有重写put方法,而是直接沿用了HashMap#put方法。有关HashMap#put已经在《Java集合中的HashMap类》有了较为详细的介绍。从调用HashMap#put方法可知,它的插入过程和HashMap相同,也就是说它也一样有着和HashMap相同的散列表结构。不过要小心尽管调用的是HashMap#put方法,但在这个方法中有一个方法是构造一个新节点newNode,这里LinkedHashMap重写了,所以调用的是LinkedHashMap#newNode,也正是这个方法实现了对LinkedHashMap链表的维护。
忽略其余代码,关键代码在HashMap#putVal中tab[i] = newNode(hash, key, value, null),稍后再来查看LinkedHashMap#newNode方法。
其过程先用图例来说明。
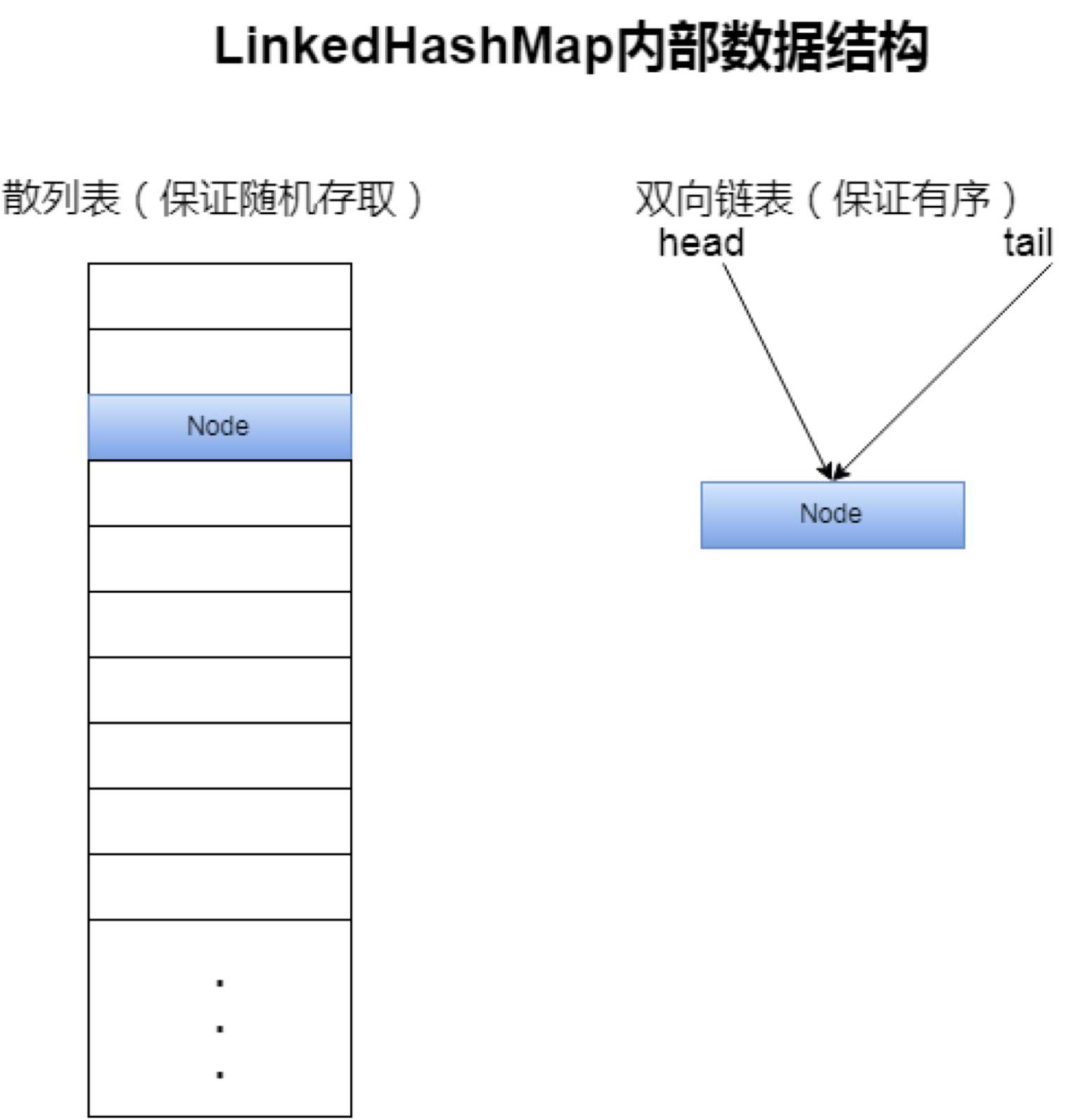
链表插入过程如下代码所示:
1 //LinkedHashMap#newNode,构造一个新的节点 2 Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { 3 LinkedHashMap.Entry<K,V> p = 4 new LinkedHashMap.Entry<K,V>(hash, key, value, e); 5 linkNodeLast(p); 6 return p; 7 }
1 //LinkedHashMap#linkNodeLast,插入到链表尾部 2 private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { 3 LinkedHashMap.Entry<K,V> last = tail; //LinkedHashMap定义了tail尾指针和head头指针,且链表为双向链表 4 tail = p; 5 if (last == null) 6 head = p; 7 else { 8 //双向链表的插入 9 p.before = last; 10 last.after = p; 11 } 12 }
对于LinkedHashMap插入,散列表部分和HashMap一致,而双向链表部分则是来一个就插到尾部,这样就保证了保持插入顺序。
通过插入基本了解了LinkedHashMap的内部实现,get方法很简单,同样是计算出key的hash和对应散列表的下标即可。
在LinkedHashMap还需要提到三个方法,这三个方法在HashMap中定义,但是并没有具体实现,具体实现放到了LinkedHashMap中。
void afterNodeAccess(Node<K,V> p)
此方法可以实现通过访问顺序排序,方法中如果定义accessOrder=true,则会将访问(get)过的元素放到链表尾部。accessOrder设置可以通过构造方法传递。
void afterNodeInsertion(boolean evict)
这个方法在LinkedHashMap并无意义,因为它调用的removeEldestEntry始终返回false,此时程序就会返回不会执行。但如果重写了removeEldestEntry方法,则可以实现LRU(最近最少使用)缓存。
void afterNodeRemoval(Node<K,V> p)
移除Map中的元素时调用,更新双向链表。
这是一个能给程序员加buff的公众号 