标签:des blog http io os 使用 java ar strong
为什么使用多线程?
为了更高效的完成任务和利用CPU资源,现在的操作系统设计为多任务操作系统,而多进程和多线程是实现多任务的方式。
什么是进程和线程?
进程是指一个内存中运行的应用程序,每个进程都有自己独立的一块内存空间,一个进程中可以启动多个线程。进程是OS分配资源的最小单位。 线程是指进程中的一个执行流程,一个进程中可以运行多个线程。线程总是属于某个进程,进程中的多个线程共享进程的内存。进程是OS调度的最小单位。
工作原理?
线程的状态转换是线程控制的基础。线程状态总的可分为五大状态:分别是新建、就绪、运行、等待/阻塞、死亡。用一个图来描述如下:
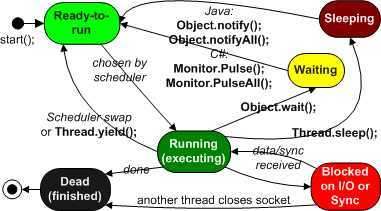
1、新建状态:线程对象已经创建,还没有在其上调用start()方法。2、就绪状态:当线程有资格运行,但调度程序还没有把它选定为运行线程时线程所处的状态。当start()方法调用时,线程首先进入可运行状态。在线程运行之后或者从阻塞、等待或睡眠状态回来后,也返回到就绪状态。3、运行状态:线程调度程序从就绪线程池中选择一个线程作为当前线程时线程所处的状态。这也是线程进入运行状态的唯一一种方式。4、等待/阻塞/睡眠状态:线程不会被分配 CPU 时间,无法执行;可能阻塞于I/O,或者阻塞于同步锁。实际上这个三状态组合为一种,其共同点是:线程仍旧是活的,但是当前没有条件运行。换句话说,它是可运行的,但是如果某件事件出现,他可能返回到可运行状态。5、死亡态:当线程的run()方法完成时就认为它死去,调用 stop()或 destroy() 亦有同样效果,但是不被推荐,前者会产生异常,后者是强制终止,不会释放锁。这个线程对象也许是活的,但是,它已经不是一个单独执行的线程。线程一旦死亡,就不能复生。 如果在一个死去的线程上调用start()方法,会抛出java.lang.IllegalThreadStateException异常。
线程锁机制的本质是解决线程通信中的互斥问题。 由于我们可以通过 private 关键字来保证数据对象只能被方法访问,所以我们只需针对方法提出一套机制,这套机制就是 synchronized 关键字,它包括两种用法:synchronized 方法和 synchronized 块。注意:每个类实例对应一把锁,同步和互斥等都是相对多线程而言的。
通过在方法声明中加入 synchronized关键字来声明 synchronized 方法,语法如下:
public synchronized void procData();
synchronized 方法原理:多个线程访问同一个 synchronized 方法时,必须获得调用该方法的类实例的锁才能执行,否则所属线程阻塞,方法一旦执行,就独占该锁,直到从该方法返回时才将锁释放,此后被阻塞的线程方能获得该锁,重新进入可执行状态。这种机制确保了同一时刻对于每一个类实例,其所有声明为 synchronized 的成员函数中至多只有一个处于可执行状态(因为至多只有一个能够获得该类实例对应的锁),从而有效避免了类成员变量的访问冲突(只要所有可能访问类成员变量的方法均被声明为 synchronized)。
在 Java 中,不光是类实例,每一个类也对应一把锁,这样我们也可将类的静态成员函数声明为 synchronized ,以控制其对类的静态成员变量的访问。
synchronized 方法的缺陷:若将一个大的方法声明为synchronized 将会大大影响效率,典型地,若将线程类的方法 run() 声明为 synchronized ,由于在线程的整个生命期内它一直在运行,因此将导致它对本类任何 synchronized 方法的调用都永远不会成功。当然我们可以通过将访问类成员变量的代码放到专门的方法中,将其声明为 synchronized ,并在主方法中调用来解决这一问题,但是 Java 为我们提供了更好的解决办法,那就是 synchronized 块。
通过 synchronized关键字来声明synchronized 块,语法如下:
synchronized(syncObject) {
//允许访问控制的代码
}
synchronized 块是这样一个代码块,其中的代码必须获得对象 syncObject (如前所述,可以是类实例或类)的锁方能执行,具体机制同前所述。由于可以针对任意代码块,且可任意指定上锁的对象,故灵活性较高。
阻塞机制的本质是为了解决线程通信的同步问题。锁和阻塞机制解决线程通信中的互斥和同步问题。
为了解决对共享存储区的访问冲突,引入了锁机制,考察多个线程对共享资源的访问,显然锁机制已经不够了,因为在任意时刻所要求的资源不一定已经准备好了被访问,反过来,同一时刻准备好了的资源也可能不止一个。为了解决这种情况下的访问控制问题,引入了对阻塞机制的支持。
阻塞指的是暂停一个线程的执行以等待某个条件发生(如某资源就绪)。Java 提供了大量方法来支持阻塞,下面让我们逐一分析。
wait() 和 notify() 方法的上述特性决定了它们经常和synchronized 方法或块一起使用,将它们和操作系统的进程间通信机制作一个比较就会发现它们的相似性:synchronized方法或块提供了类似于操作系统原语的功能,它们的结合用于解决各种复杂的线程间通信问题。
谈到阻塞,就不能不谈一谈死锁,略一分析就能发现,suspend() 方法和不指定超时期限的 wait() 方法的调用都可能产生死锁。遗憾的是,Java 并不在语言级别上支持死锁的避免,我们在编程中必须小心地避免死锁。
以上我们对 Java 中实现线程阻塞的各种方法作了一番分析,我们重点分析了 wait() 和 notify() 方法,因为它们的功能最强大,使用也最灵活,但是这也导致了它们的效率较低,较容易出错。实际使用中我们应该灵活使用各种方法,以便更好地达到我们的目的。
join()方法可用于让当前线程阻塞,以等待特定线程(调用join的线程)的消亡。不允许线程对象在自己的可执行体中调用自己线程的join。
线程的优先级代表该线程的重要程度,当有多个线程同时处于可执行状态并等待获得 CPU 时间时,线程调度系统根据各个线程的优先级来决定给谁分配 CPU 时间,优先级高的线程有更大的机会获得 CPU 时间,优先级低的线程也不是没有机会,只是机会要小一些罢了。
你可以调用 Thread 类的方法 getPriority() 和 setPriority()来存取线程的优先级,线程的优先级界于1(MIN_PRIORITY)和10(MAX_PRIORITY)之间,缺省是5(NORM_PRIORITY)。
线程可以分为用户线程(User)和守护线程(Daemon): 守护线程是一类特殊的线程,它和普通线程的区别在于它并不是应用程序的核心部分,当一个应用程序的所有非守护线程终止运行时,即使仍然有守护线程在运行,应用程序也将终止,反之,只要有一个非守护线程在运行,应用程序就不会终止。守护线程一般被用于在后台为其它线程提供服务。 可以通过调用方法 isDaemon() 来判断一个线程是否是守护线程,也可以调用方法 setDaemon() 来将一个线程设为守护线程。
个人对Daemon线程更直观的理解是:无论User还是Daemon线程,都具有可执行序列,拥有自己的工作栈,区别在于:Daemon线程会随着其父线程结束而结束,它不属于程序本体。另一层意思,父线程的结束取决于其所有子User线程,而与daemon线程无关。它们之间的不同决定了它们用于不同的场景,守护线程一般为其他线程提供服务,如垃圾回收器。
需要注意的是setDaemon()方法必须在线程对象没有调用start()方法之前调用,否则没效果。
java.lang.ThreadLocal是local variable(线程局部变量)。它为每一个使用该变量的线程都提供一个变量值的副本,使每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。从线程的角度看,就好像每一个线程都完全拥有该变量。ThreadLocal本质是一个线程安全的hashMap,key为threadName,Value为线程内的变量。
参考资料: http://programming.iteye.com/blog/158568 http://lavasoft.blog.51cto.com/62575/51926
标签:des blog http io os 使用 java ar strong
原文地址:http://www.cnblogs.com/SanDiegoXu/p/3987223.html