标签:MySQL SQL查询
MySQL数据库基础(五)——SQL查询在SELECT语句中使用星号“”通配符查询所有字段
在SELECT语句中指定所有字段
select from TStudent;
查询多个字段
select Sname,sex,email from TStudent;
在SELECT 语句中通过WHERE子句,对数据进行过滤,语法格式为:
SELECT 字段名1,字段名2,…,字段名n FROM 表名WHERE 查询条件
select Sname,sex,email,Class from TStudent where class=‘java‘;
查询满足指定范围内的条件的记录,使用IN操作符,将所有检索条件用括号括起来,检索条件用逗号分隔开,只要满足条件范围内的一个值即为匹配项。
查新姓 王 刘 石的学生
select * from TStudent where left(sname,1) in (‘王‘,‘刘‘,‘石‘);
查询某个范围内的值,该操作符需要两个参数,即范围的开始值和结束值,如果字段值满足指定的范围查询条件,则这些记录被返回。
以下查询条件,查询学号100到150的学生,包括100和150
select from TStudent where convert(studentid,signed) between 100 and 150
等价于
select from TStudent where convert(studentid,signed)>=100
and convert(studentid,signed)<=150
自动转换类型
select * from TStudent where studentid between 100 and 150
百分号通配符‘%’,匹配任意长度的字符,甚至包括零字符
下划线通配符‘_’,一次只能匹配任意一个字符
查找姓名中间字为“志”字的学生
select from TStudent where sname like ‘志‘ ;
查找姓名中有“志”字的学生
select from TStudent where sname like ‘%志%‘;
在SELECT语句中使用IS NULL子句,可以查询某字段内容为空记录。
查找邮箱是空值的记录
select * from s where email is null;
使用AND连接两个甚至多个查询条件,多个条件表达式之间用AND分开。select * from TStudent where sex=‘男‘ and Class=‘net‘ and studentid>20 and studentid<50;
OR操作符,表示只需要满足其中一个条件的记录即可返回。OR也可以连接两个甚至多个查询条件,多个条件表达式之间用AND分开。
select * from TStudent where sname like ‘%志%‘ or class=‘net‘;
在SELECT语句中可以使用DISTINCE关键字指示MySQL消除重复的记录值。
SELECT DISTINCT 字段名 FROM 表名;
查询一共有几个班
select distinct class from TStudent;
LIMIT关键字可以返回指定位置的记录。
LIMIT [位置偏移量,] 行数
返回前10个学生
select from TStudent limit 10;
返回第11-20个学生,偏移量是10,就意味着从第11个开始取10条记录。
select from TStudent limit 10,10;
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同。各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
要求第一个SQL语句返回的列和第二条返回的列数相同,
select studentid,sname from TStudent where studentid<=10
union
select studentid, sname from TStudent where sname like ‘王%‘;
为字段取别名
MySQL可以指定列别名,替换字段或表达式。
列名 [AS] 列别名
select studentid as 学号,sname as 姓名,sex as 性别 from TStudent
select studentid 学号,sname 姓名,sex 性别 from TStudent
为表取别名
为了方便操作或者需要多次使用相同的表时,可以为表指定别名,用别名替代表原来的名称。
表名 [AS] 表别名
select a.studentid 学号,a.sname 姓名,a.sex 性别 from TStudent as a;
select a.studentid 学号,a.sname 姓名,a.sex 性别 from TStudent a;
内连接(INNER JOIN)使用比较运算符根据每个表共有的列的值匹配两个表中的行,并列出表中与连接条件相匹配的数据行,组合成新的记录。在内连接查询中,只有满足条件的记录才能出现在结果关系中。
语句3:隐式的内连接,没有INNER JOIN,形成的中间表为两个表的笛卡尔积。
select a.StudentID, a.Sname, b.mark from TStudent a, TScore b where a.StudentID=b.StudentID;
语句4:显示的内连接,一般称为内连接,有INNER JOIN,形成的中间表为两个表经过ON条件过滤后的笛卡尔积。
select a.StudentID, a.Sname, b.mark from TStudent a inner joinTScore b on a.StudentID=b.StudentID;
select a.StudentID,a.Sname,c.subJectName,b.mark from TStudent a join TScore b on a.StudentID=b.StudentID join TSubject c on b.subJectID=c.subJectID;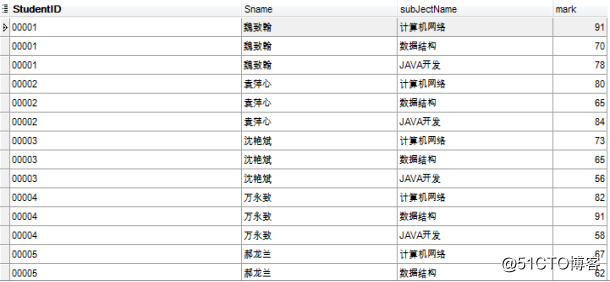
如果某列只在一张表中,就可以不用指明是哪个表中的列。
select a.StudentID,a.Sname,subJectName,mark from TStudent a join TScore b on a.StudentID=b.StudentID join TSubject c on b.subJectID=c.subJectID;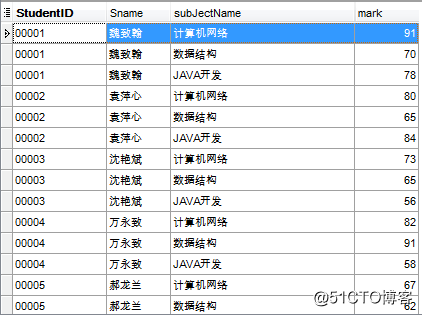
外连接分为左连接、右连接、全连接。
外连接返回到查询结果集合中的不仅包含符合连接条件的行,而且还包括左表(左外连接或左连接)、右表(右外连接或右连接)或两个边接表(全外连接)中的所有数据行。
外连不但返回符合连接和查询条件的数据行,还返回不符合条件的一些行。外连接分三类:左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)和全外连接(FULL OUTER JOIN)。
三者的共同点是都返回符合连接条件和查询条件(即:内连接)的数据行。不同点如下:
左外连接还返回左表中不符合连接条件单符合查询条件的数据行。
右外连接还返回右表中不符合连接条件单符合查询条件的数据行。
全外连接还返回左表中不符合连接条件单符合查询条件的数据行,并且还返回右表中不符合连接条件单符合查询条件的数据行。全外连接实际是上左外连接和右外连接的数学合集(去掉重复),即“全外=左外 UNION 右外”。
左连接
包含左边表的全部行(不管右边的表中是否存在与它们匹配的行),以及右边表中全部匹配的行。
左连接的结果集包括?LEFT OUTER子句中指定的左表的所有行,而不仅仅是连接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。?
select a.StudentID, a.Sname, b.mark from TStudent a left join TScore b on a.StudentID=b.StudentID;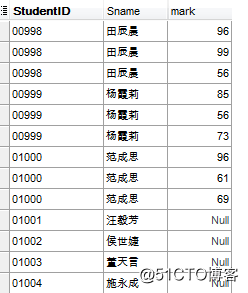
右连接:
右连接包含右边表的全部行(不管左边的表中是否存在与它们匹配的行),以及左边表中全部匹配的行。
右连接是左连接的反向连接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。????
select a.StudentID, a.Sname, b.mark from TScore b right join TStudent a on a.StudentID=b.StudentID;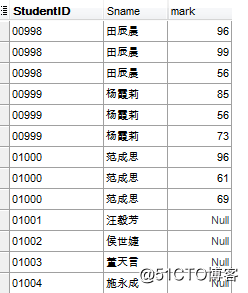
全连接:
全连接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。MySQL不支持全外连接。可以通过左外和右外求合集来获取全外连接的查询结果。
select a.StudentID, a.Sname, b.mark from TStudent a left join
TScore b on a.StudentID=b.StudentID
union
select b.StudentID, c.subJectName, b.mark from TScore b right join
TSubject c on b.subJectID=c.subJectID;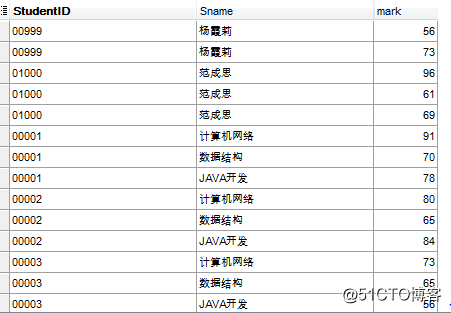
交叉连接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉连接有显式的和隐式的,不带ON子句,返回的是两表的乘积,也叫笛卡尔积。
FROM子句中的表或视图可通过内连接或全连接按任意顺序指定;但是,用左或右向外连接指定表或视图时,表或视图的顺序很重要。
隐式交叉连接,没有cross join
select a.StudentID, a.Sname, b.mark from TStudent a,TScore b where a.StudentID < 4;
显示交叉连接,有cross join
select a.StudentID, a.Sname, b.mark from TStudent a cross join TScore b where a.StudentID < 4;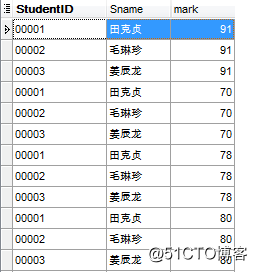
第一、单表查询:根据WHERE条件过滤表中的记录,形成中间表;然后根据SELECT的选择列选择相应的列进行返回最终结果。
第二、两表连接查询:对两表求积(笛卡尔积)并用ON条件和连接连接类型进行过滤形成中间表;然后根据WHERE条件过滤中间表的记录,并根据SELECT指定的列返回查询结果。实例如下:
select a.StudentID, a.Sname, b.mark from TStudent a left join TScore b on a.StudentID=b.StudentID where a.StudentID < 10;
第三、多表连接查询:先对第一个和第二个表按照两表连接做查询,然后用查询结果和第三个表做连接查询,以此类推,直到所有的表都连接上为止,最终形成一个中间的结果表,然后根据WHERE条件过滤中间表的记录,并根据SELECT指定的列返回查询结果。
ON条件:过滤两个连接表笛卡尔积形成中间表的约束条件。
WHERE条件:在有ON条件的SELECT语句中是过滤中间表的约束条件。在没有ON的单表查询中,是限制物理表或者中间查询结果返回记录的约束。在两表或多表连接中是限制连接形成最终中间表的返回结果的约束。
将WHERE条件移入ON后面是不恰当的。推荐的做法是ON只进行连接操作,WHERE只过滤中间表的记录。
连接查询是SQL查询的核心,连接查询的连接类型选择依据实际需求。如果选择不当,非但不能提高查询效率,反而会带来一些逻辑错误或者性能低下。两表连接查询选择方式的依据:
A、查两表关联列相等的数据用内连接。
B、Col_L是Col_R的子集时用右连接。
C、Col_R是Col_L的子集时用左连接。
E、 Col_R和Col_L彼此有交集但彼此互不为子集时候用全连接。
F、求差操作的时候用联合查询。
MySQL中可以通过在SELECT使用ORDER BY子句对查询的结果进行排序。
ASC代表结果会以由小往大的顺序列出,而?DESC?代表结果会以由大往小的顺序列出。默认升序ASC排序。
select from TStudent order by birthday asc;
select from TStudent order by birthday desc;
可以分别指定排序方向。
select a.StudentID,a.Sname,subJectName,mark from TStudent a join TScore b on a.StudentID=b.StudentID join TSubject c on b.subJectID=c.subJectID where c.subJectID=‘0001‘ order by mark desc,a.studentID desc;
分组查询是对数据按照某个或多个字段进行分组。
// 分组查询格式
SELECT column
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition] // 过滤条件为聚合函数,使用having
[ORDER BY column];
聚合函数只能出现在SELECT列表、HAVING子句和ORDER BY子句中,不能出现在WHERE子句中。如果要限制分组结果,只能使用HAVING子句。
使用group by关键字时,在select列表中可以指定的项目是有限制的,select语句中仅允许是被分组的列,或是为每个分组返回一个值的表达式,例如用一个列名作为参数的聚合函数。
Where子句:从数据源去掉不符合搜索条件的数据;
GROUP BY子句:分组,使用统计函数(聚合函数)为每组计算统计值;
HAVING子句:在分好的组中去掉每组中不符合条件的数据行。
COUNT()函数
select class,COUNT(*) from TStudent group by class;
SUM()函数
查询每个学生总分
select concat(a.StudentID,‘ ‘,a.sname) ss,SUM(b.mark) from TStudent a join TScore b on a.StudentID=b.StudentID group by ss;
AVG()函数
统计每个班平均分
Select class,AVG(mark) from TStudent a join TScore b on a.StudentID=b.StudentID group by class;
统计每班每科平均分,需要按两列分组class和subJectName
select class,subJectName,AVG(mark) from TStudent a join TScore b on a.StudentID=b.StudentID join TSubject c on b.subJectID=c.subJectID group by class,subJectName;
查询平局分大于80的学生
select concat(a.StudentID,‘ ‘,a.sname) ss,avg(b.mark) m from TStudent a join TScore b on a.StudentID=b.StudentID group by ss having m>80;
查找平均分大于80分,按平均分排序。
select concat(a.StudentID,‘ ‘,a.sname) ss,avg(b.mark) m from TStudent a join TScore b on a.StudentID=b.StudentID group by ss having m>80 order by m;
使用GROUP BY的WITH ROLLUP子句可以检索出更多的分组聚合信息,不仅仅可以检索出各组的聚合信息,还能检索出本组类的整体聚合信息。
select class,subJectName,AVG(mark) from TStudent a join TScore b on a.StudentID=b.StudentID join TSubject c on b.subJectID=c.subJectID group by class,subJectName with rollup;
能够统计每班每科的平均成绩,每班的平均成绩也能统计,全部班级的全部课程平均成绩也能统计。
IN关键字进行子查询时,内层查询语句仅仅返回一个数据列,数据列里的值将提供给外层查询语句进行比较操作。
select * from TStudent where studentid in (select distinct studentid from TScore where mark>98);
EXISTS关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断子查询是否返回行,如果至少返回一行,那么EXISTS的结果为true,此时外层查询语句将进行查询;如果子查询没有返回任何行,那么EXISTS返回的结果是false,此时外层语句将不进行查询。
select from TStudent where studentid=‘01001‘ and exists (select from TScore where studentid=‘01001‘);
ANY和SOME关键字是同义词,表示满足其中任一条件,允许创建一个表达式对子查询的返回值列表进行比较,只要满足内层子查询中的任何一个比较条件,就返回一个结果作为外层查询的条件。
select from TStudent where studentid=any (select distinct studentid from TScore where mark>98)
等价于
select from TStudent where studentid=some (select distinct studentid from TScore where mark>98);
等价于
select from TStudent where studentid in (select distinct studentid from TScore where mark>98);
子查询时还可以使用其他的比较运算符,如<、<=、=、>=和!=等。
以下SQL语句子查询查出考试成绩大于98的学生的studentid,比如查出的结果有三个‘00010’,‘00021’,‘00061’,外查询将会查询比00010学号大的学生。
select from TStudent where studentid>some (select distinct studentid from TScore where mark>98)
以下SQL语句子查询查出考试成绩大于98的学生的studentid,比如查出的结果有三个‘00010’,‘00021’,‘00061’,外查询将会查询比00061学号小的学生。select * from TStudent where studentid<some (select distinct studentid from TScore where mark>98);
ALL关键字与ANY和SOME不同,使用ALL时需要同时满足所有内层查询的条件。
以下SQL语句子查询查出考试成绩大于98的学生的studentid,比如查出的结果有三个‘00010’,‘00021’,‘00061’,外查询将会查询比00010学号小的学生。select * from TStudent where studentid<all (select distinct studentid from TScore where mark>98)
以下SQL语句子查询查出考试成绩大于98的学生的studentid,比如查出的结果有三个‘00010’,‘00021’,‘00061’,外查询将会查询比00061学号大的学生。
select * from TStudent where studentid>all (select distinct studentid from TScore where mark>98);
正则表达式作用是匹配文本,将一个模式(正则表达式)与一个文本串进行比较。MySQL用WHERE子句对正则表达式提供了初步的支持,允许指定用正则表达式过滤SELECT检索出的数据。
在SQL查询语句中,查询条件REGEXP后所跟的东西作为正则表达式处理。
字符‘^’匹配以特定字符或者字符串开头的文本。
select * from TStudent where sname regexp ‘^刘平‘;
字符‘$’匹配以特定字符或者字符串结尾的文本。
select * from TStudent where cardid regexp ‘36$‘;
字符‘.’匹配任意一个字符。
select * from TStudent where sname regexp ‘.康.‘;
星号‘’匹配前面的字符任意多次,包括0次。
加号‘+’匹配前面的字符至少一次。
找出×××以19开始,以6结束的学生
select from TStudent where cardid regexp ‘^19.6$‘
找出×××号中有123的学生
select from TStudent where cardid regexp ‘.123+.‘;
正则表达式可以匹配指定字符串,只要匹配字符串在查询文本中即可,如要匹配多个字符串,多个字符串之间使用分隔符‘|’隔开。
select * from TStudent where sname regexp ‘武|尹|罗‘;
方括号“[]”指定一个字符集合,只匹配其中任何一个字符,即为所查找的文本。不支持汉字。
select from TStudent where email regexp ‘[w-z]‘;
select from TStudent where cardid regexp ‘^[1-3,7]‘;
“[^字符集合]”匹配不在指定集合中的任何字符。
select * from TStudent where cardid regexp ‘^[^1-7]‘;
“字符串{n,}”表示至少匹配n次前面的字符。“字符串{n,m}”表示匹配前面的字符串不少于n次,不多于m次。
查找×××中出现138并且后面有8位0-9的数字的学生。
select * from TStudent where cardid regexp ‘138[0-9]{15}‘;
标签:MySQL SQL查询
原文地址:http://blog.51cto.com/9291927/2092195