概述:Apache Beam WordCount编程实战及源代码解读,并通过intellij IDEA和terminal两种方式调试执行WordCount程序,Apache Beam对大数据的批处理和流处理,提供一套先进的统一的编程模型,并能够执行大数据处理引擎上。完整项目Github源代码

负责公司大数据处理相关架构,可是具有多样性,极大的添加了开发成本,急需统一编程处理,Apache Beam。一处编程,处处执行。故将折腾成果分享出来。
1.Apache Beam编程实战–前言,Apache Beam的特点与关键概念。
Apache Beam 于2017年1月10日成为Apache新的顶级项目。
1.1.Apache Beam 特点:
- 统一:对于批处理和流媒体用例使用单个编程模型。
- 方便:支持多个pipelines环境执行。包含:Apache Apex, Apache Flink, Apache Spark, 和 Google Cloud Dataflow。
- 可扩展:编写和分享新的SDKs,IO连接器和transformation库
部分翻译摘自官网:Apacher Beam 官网
1.2.Apache Beam关键概念:
1.2.1.Apache Beam SDKs
主要是开发API。为批处理和流处理提供统一的编程模型。眼下(2017)支持JAVA语言。而Python正在紧张开发中。
1.2.2. Apache Beam Pipeline Runners(Beam的执行器/执行者们)。支持Apache Apex,Apache Flink。Apache Spark。Google Cloud Dataflow多个大数据计算框架。可谓是一处Apache Beam编程,多计算框架执行。
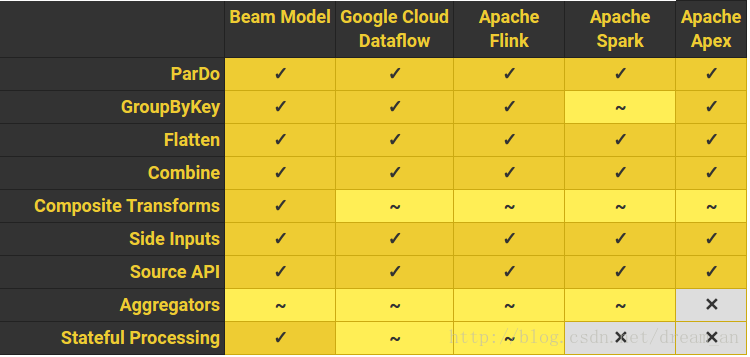
1.2.3. 他们的对例如以下的支持情况详见
2.Apache Beam编程实战–Apache Beam源代码解读
基于maven,intellij IDEA。pom.xm查看 完整项目Github源代码 。直接通过IDEA的项目导入功能就可以导入完整项目,等待MAVEN下载依赖包,然后依照例如以下解读步骤就可以顺利执行。
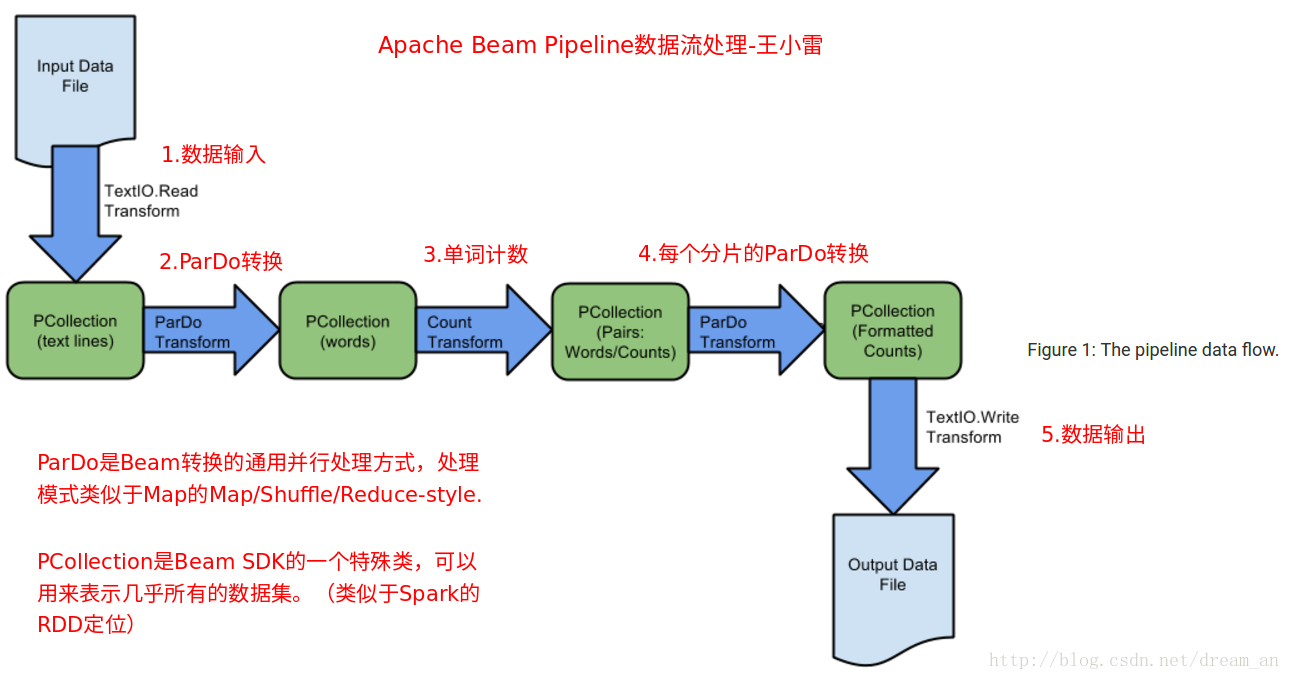
2.1.源代码解析-Apache Beam 数据流处理原理解析:
关键步骤:
- 创建Pipeline
- 将转换应用于Pipeline
- 读取输入文件
- 应用ParDo转换
- 应用SDK提供的转换(比如:Count)
- 写出输出
- 执行Pipeline
2.2.源代码解析。完整项目Github源代码,附WordCount,pom.xml等
/**
* MIT.
* Author: wangxiaolei(王小雷).
* Date:17-2-20.
* Project:ApacheBeamWordCount.
*/
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.Default;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.Validation.Required;
import org.apache.beam.sdk.transforms.Aggregator;
import org.apache.beam.sdk.transforms.Count;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.transforms.PTransform;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.SimpleFunction;
import org.apache.beam.sdk.transforms.Sum;
import org.apache.beam.sdk.values.KV;
import org.apache.beam.sdk.values.PCollection;
public class WordCount {
/**
*1.a.通过Dofn编程Pipeline使得代码非常简洁。b.对输入的文本做单词划分,输出。
*/
static class ExtractWordsFn extends DoFn<String, String> {
private final Aggregator<Long, Long> emptyLines =
createAggregator("emptyLines", Sum.ofLongs());
@ProcessElement
public void processElement(ProcessContext c) {
if (c.element().trim().isEmpty()) {
emptyLines.addValue(1L);
}
// 将文本行划分为单词
String[] words = c.element().split("[^a-zA-Z‘]+");
// 输出PCollection中的单词
for (String word : words) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}
/**
*2.格式化输入的文本数据,将转换单词为并计数的打印字符串。
*/
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}
/**
*3.单词计数,PTransform(PCollection Transform)将PCollection的文本行转换成格式化的可计数单词。
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> expand(PCollection<String> lines) {
// 将文本行转换成单个单词
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// 计算每一个单词次数
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}
/**
*4.能够自己定义一些选项(Options)。比方文件输入输出路径
*/
public interface WordCountOptions extends PipelineOptions {
/**
* 文件输入选项,能够通过命令行传入路径參数,路径默觉得gs://apache-beam-samples/shakespeare/kinglear.txt
*/
@Description("Path of the file to read from")
@Default.String("gs://apache-beam-samples/shakespeare/kinglear.txt")
String getInputFile();
void setInputFile(String value);
/**
* 设置结果文件输出路径,在intellij IDEA的执行设置选项中或者在命令行中指定输出文件路径,如./pom.xml
*/
@Description("Path of the file to write to")
@Required
String getOutput();
void setOutput(String value);
}
/**
* 5.执行程序
*/
public static void main(String[] args) {
WordCountOptions options = PipelineOptionsFactory.fromArgs(args).withValidation()
.as(WordCountOptions.class);
Pipeline p = Pipeline.create(options);
p.apply("ReadLines", TextIO.Read.from(options.getInputFile()))
.apply(new CountWords())
.apply(MapElements.via(new FormatAsTextFn()))
.apply("WriteCounts", TextIO.Write.to(options.getOutput()));
p.run().waitUntilFinish();
}
}3.支持Spark。Flink,Apex等大数据数据框架来执行该WordCount程序。完整项目Github源代码(推荐,注意pom.xml模块载入是否成功,在工具中开发大数据程序,利于调试,开发体验较好)
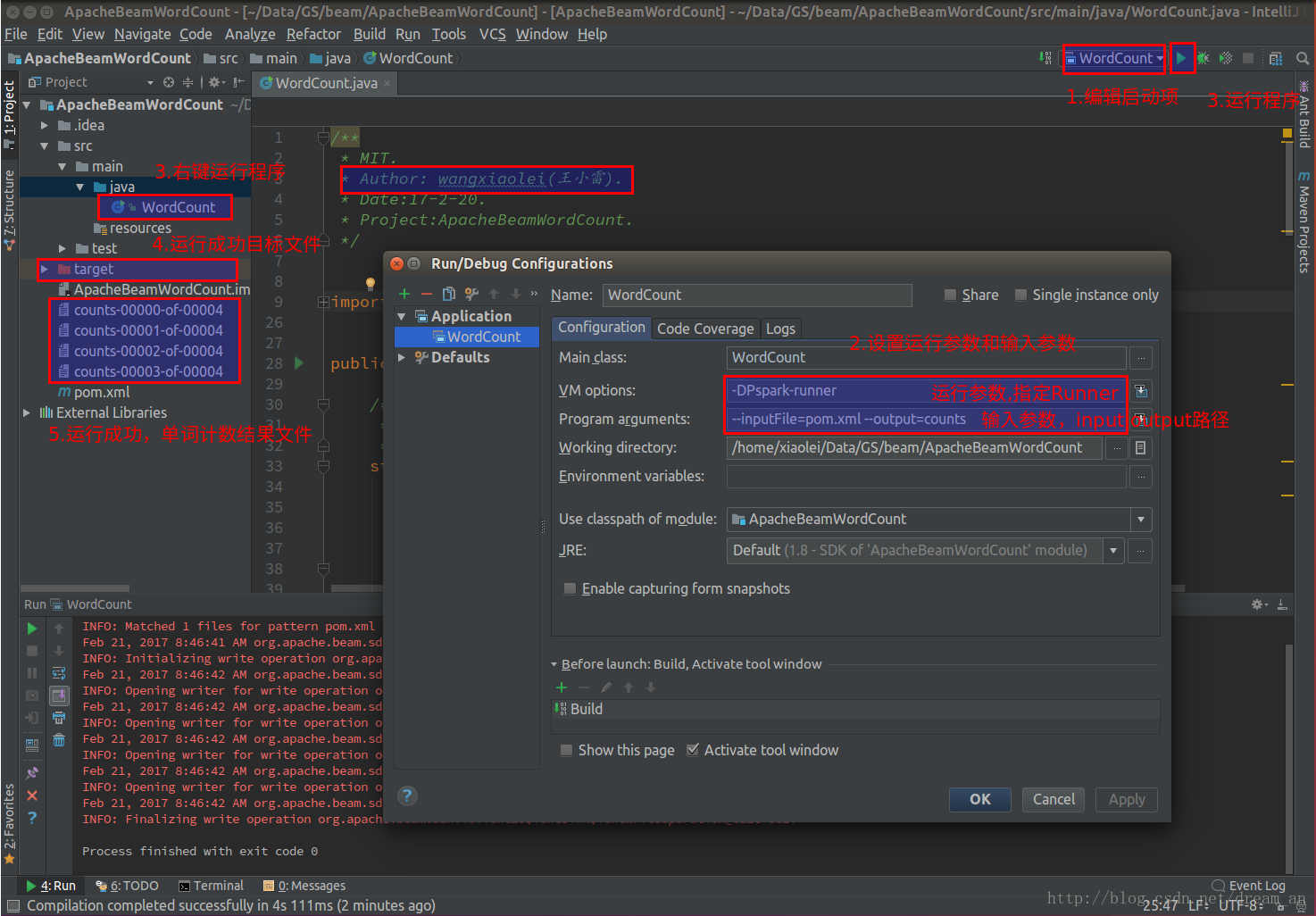
3.1.intellij IDEA(社区版)中Spark大数据框架执行Pipeline计算程序
Spark执行
设置VM options
-DPspark-runner设置Programe arguments
--inputFile=pom.xml --output=counts
3.2.intellij IDEA(社区版)中Apex。Flink等支持的大数据框架均可执行WordCount的Pipeline计算程序,完整项目Github源代码
Apex执行
设置VM options
-DPapex-runner设置Programe arguments
--inputFile=pom.xml --output=counts
Flink执行等等
设置VM options
-DPflink-runner设置Programe arguments
--inputFile=pom.xml --output=counts
4.终端执行(Terminal)(不推荐,第一次下载过程非常慢。开发体验较差)
4.1.下面命令是下载官方演示样例源代码。第一次执行下载较慢,假设失败了就多执行几次。(推荐下载,完整项目Github源代码)直接用上述解读在intellij IDEA中执行。
mvn archetype:generate -DarchetypeRepository=https://repository.apache.org/content/groups/snapshots -DarchetypeGroupId=org.apache.beam -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples -DarchetypeVersion=LATEST -DgroupId=org.example -DartifactId=word-count-beam -Dversion="0.1" -Dpackage=org.apache.beam.examples -DinteractiveMode=false

4.2.打包并执行
mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--runner=SparkRunner --inputFile=pom.xml --output=counts" -Pspark-runner