Set(HashSet、TreeSet)
一、Set简单介绍
首先,我们来看看Set的API:

之前我们看到Collection的体系结构时,可以看出Set是无序的,并且存储的是不重复的。通过API我们也可以看出,Set最多保安一个null元素。
二、HashSet
1.API介绍

简单点就是,HashSet用哈希算法实现,无序,不重复,可以使用null。
2.案例
- 存储字符串并遍历
 View Code
View Code1 public class Test_Set { 2 public static void main(String[] args){ 3 //存储字符串并遍历 4 HashSet<String> hashSet = new HashSet<>(); 5 boolean flag = hashSet.add("唐豆豆"); 6 boolean flag2 = hashSet.add("唐豆豆"); 7 System.out.println(flag); 8 System.out.println(flag2); 9 //增强for循环遍历 10 for (String s : hashSet){ 11 System.out.println(s); 12 } 13 } 14 }
结果:
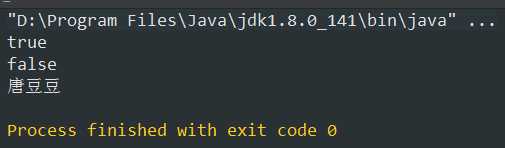
第一个输出结果为:true,证明已经存放到HashSet当中,第二个为false,证明没有存放到集合当中,输出结果也是只有一个。所以,HashSet存放的是不重复的。那么存储对象又是什么样的呢? -
存储自定义对象保证元素唯一性
View Code1 public class Test_Set { 2 public static void main(String[] args){ 3 // addStringByHashSet(); 4 HashSet<Person> hashSet = new HashSet<>(); 5 hashSet.add(new Person("张三",23)); 6 hashSet.add(new Person("张三",23)); 7 hashSet.add(new Person("张三",23)); 8 9 System.out.println(hashSet.size()); 10 } 11 } 12 13 14 class Person { 15 private String name; 16 private Integer age; 17 18 public Person() { 19 } 20 21 public Person(String name, Integer age) { 22 this.name = name; 23 this.age = age; 24 } 25 26 public String getName() { 27 return name; 28 } 29 30 public void setName(String name) { 31 this.name = name; 32 } 33 34 public Integer getAge() { 35 return age; 36 } 37 38 public void setAge(Integer age) { 39 this.age = age; 40 } 41 42 @Override 43 public String toString() { 44 return "Person{" + 45 "name=‘" + name + ‘\‘‘ + 46 ", age=" + age + 47 ‘}‘; 48 } 49 //重写equals方法 50 @Override 51 public boolean equals(Object o) { 52 if (this == o) return true; 53 if (o == null || getClass() != o.getClass()) return false; 54 55 Person person = (Person) o; 56 57 if (name != null ? !name.equals(person.name) : person.name != null) return false; 58 return age != null ? age.equals(person.age) : person.age == null; 59 } 60 //重写HashCode方法 61 @Override 62 public int hashCode() { 63 int result = name != null ? name.hashCode() : 0; 64 result = 31 * result + (age != null ? age.hashCode() : 0); 65 return result; 66 } 67 68 }
结果:


保证了元素的唯一性。
既然是HashSet,那么如果不重写hashCode方法,那么会怎么样呢?大家可以注释掉hashCode方法执行一下看看结果。
答案是:
1 Console.info(3)//答案是3
没有重写hashCode方法,也就没有执行equals方法。
首先,我们来看看他没有重写HashCode方法时,是怎么存储的。
1 HashSet<Person> hashSet = new HashSet<>(); 2 hashSet.add(new Person("张三",23)); 3 hashSet.add(new Person("张三",23)); 4 hashSet.add(new Person("张三",23));
由于HashSet底层用Hash算法实现,那么第二行代码 hashSet.add(new Person("张三",23));在执行时,会生成一个hash码,第三行代码执行时有生成一个hash码,以此类推,每次都不一样,那么就认为他是三个不同的值
那么他就会都存下来。因此最后的结果就是3。
重写了hashCode方法之后呢?我们来看看那段代码~
1 @Override 2 public int hashCode() { 3 int result = name != null ? name.hashCode() : 0; 4 result = 31 * result + (age != null ? age.hashCode() : 0); 5 return result; 6 }
第三行代码,一个int类型的result,如果name不为null,那么就result就等于name的hash值,如果为null,result等于0。
第四行代码,result = 31 * 第三行的result值,加上age的判断(age不为空那么就等于age的hash值,否则等于0)
最后的结果就是result的值,这是为了保证这个对象的属性的不重复,确保hash码不重复。相同的hash码采取执行equals方法,这样降低了equals执行的次数。
那么为什么会是31乘以后面的数呢?
1,31是一个质数,质数是能被1和自己本身整除的数
2,31这个数既不大也不小
3,31这个数好算,2的五次方-1,2向左移动5位
3.HashSet的原理:
- 我们使用Set集合都是需要去掉重复元素的,如果在存储的时候逐个equals()比较,,效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数。
- 当HashSet调用add()方法存储对象的时候,先调用对象的hashCode()方法得到一个哈希值,,然后在集合中查找是否有哈希值相同的对象
* 如果没有哈希值相同的对象就直接存入集合
* 如果有哈希值相同的对象,就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存
回到那个存储自定义对象的问题当中:
* 类中必须重写hashCode()和equals()方法
* hashCode():属性相同的对象返回值必须相同, 属性不同的返回值尽量不同(提高效率)
* equals():属性相同返回true, 属性不同返回false,返回false的时候存储
三、LinkedHashSet
官方说法:此实现与 HashSet 的不同之外在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,即按照将元素插入到 set 中的顺序(插入顺序)进行迭代。
也就是:保证了怎么存怎么取。类似于List怎么存怎么取。上代码:
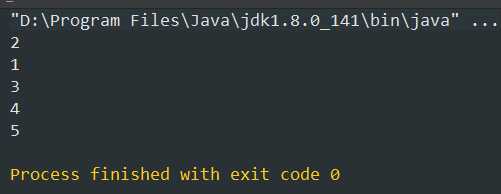
1 public class Test_Set { 2 public static void main(String[] args) { 3 LinkedHashSet<Integer> lhs = new LinkedHashSet<>(); 4 lhs.add(2); 5 lhs.add(1); 6 lhs.add(3); 7 lhs.add(1); 8 lhs.add(4); 9 lhs.add(5); 10 11 for (Integer num : lhs) { 12 System.out.println(num); 13 } 14 15 } 16 }
结果:(保证了怎么存怎么取,不重复)
四、TreeSet
1.API

好晦涩。
我们直接用例子来说明:
1 public class Test_Set { 2 public static void main(String[] args) { 3 TreeSet<Integer> treeSet = new TreeSet<>(); 4 treeSet.add(1); 5 treeSet.add(2); 6 treeSet.add(5); 7 treeSet.add(3); 8 treeSet.add(4); 9 treeSet.add(5); 10 treeSet.add(6); 11 treeSet.add(7); 12 for (Integer num : treeSet) { 13 System.out.println(num); 14 } 15 } 16 }
TreeSet是实现Set接口的,自然不重复,无序,那么运行结果是什么呢?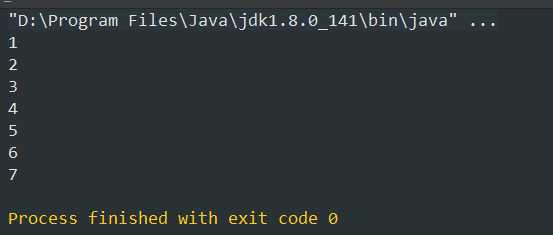
无论你怎么改变treeSet.add()里面的顺序,他的输出结果都是1234567。
也就是说,TreeSet提供了排序的功能,也就是用来给对象排序的。
2.TreeSet存储自定义对象
那么,如果我们往里面放入自定义的对象呢?
1 public class Test_Set { 2 public static void main(String[] args) { 3 TreeSet<Person> treeSet = new TreeSet<>(); 4 treeSet.add(new Person("唐豆豆",24)); 5 treeSet.add(new Person("王豆豆",23)); 6 treeSet.add(new Person("李豆豆",24)); 7 8 for (Person person : treeSet) { 9 System.out.println(person); 10 } 11 } 12 }
结果是:

Person类不能够比较,后面有个Comparable,不能够比较的。要想比较必须在Person类当中实现这一接口。那么我们来实现一下。
class Person implements Comparable<Person> { //实现comparable接口实现的方法 @Override public int compareTo(Person o) { return 0; } private String name; private Integer age; public Person() { } public Person(String name, Integer age) { this.name = name; this.age = age; } //此处省略set/get方法 }
再次运行:(只打印了一个对象信息)
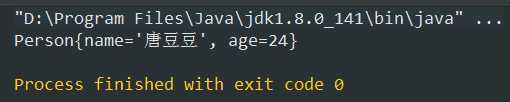
将compareTo方法里的return 0改成1(正数),再次运行:(全部打印)
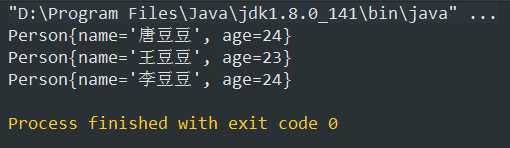
改成-1(负数)
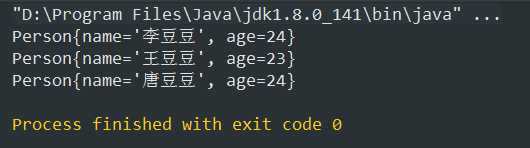
总结:
TreeSet集合是用来对象元素进行排序的,同样他也可以保证元素的唯一
* 当compareTo方法返回0的时候集合中只有一个元素
* 当compareTo方法返回正数的时候集合会怎么存就怎么取
* 当compareTo方法返回负数的时候集合会倒序存储
如有错误之处,欢迎指正。
邮箱:it_chang@126.com