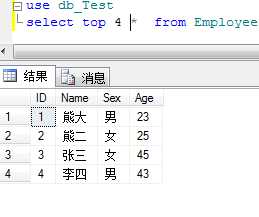
本文所用数据库为db_Test,数据表为Employee
一.SELECT语句基本结构
语句语法简单归纳为:
SELECT select_list [INTO new_table_name] [FROM table_source] [WHERE search_condition] [GROUP BY group_by_expression]
[HAVING search_condition] [ORDER BY order_expression [ASC | DESC]]
备注:红色字体为自定义参数,根据实际查询填写。
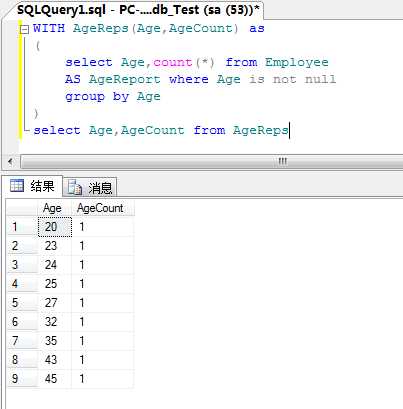
二.WITH子句
WITH子句用于指定临时命名的公用表达式,在单条语句(SELECT、INSERT、UPDATE、DELETE)的语句执行范围内定义;
例:创建一个公用表达式,计算Employee表中每一年龄的员工数量;
三.SELECT...FROM...子句
例: 在Employee中查询所有女员工的姓名、年龄信息,并另起列名;
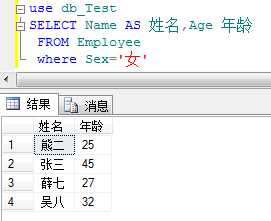
另起列名有三种方法:
1.列名 as 新列名
2.列名 =新列名
3.列名 新列名
PS:我个人比较爱用as
四.INTO子句
创建新表,并将查询结果行插入该表中。
例:用into新建一张表,名为tb_EmpAge,包含Name和Age两列
Select Name,Age into tb_EmpAge from Employee
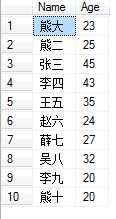
五.WHERE子句
由于where子句的复杂性,下面按照参数的先后顺序进行介绍;
1.逻辑运算符(NOT、AND、OR)
NOT:取反;
AND:逻辑与;
OR:逻辑或;
例:利用AND查询Employee表中的年龄小于30岁的所有女员工 的信息;
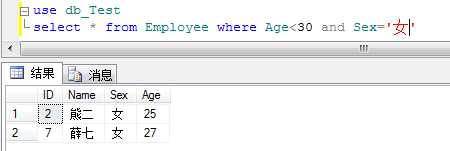
例;利用NOT查询年龄不小于30岁的所有女员工的信息
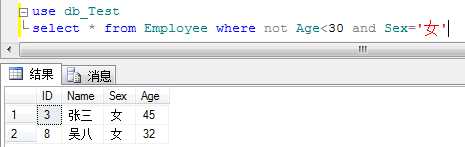
例:利用组合查询年龄不大于40的男员工信息或年龄大于30的女员工信息;
2.比较运算符(=、<>、!=、>、>=、!>、<、<=、!<)
此运算符使用简单,在此不再占用篇幅了。
3.LIKE关键字
用于模糊查询,通配符有%、_、[ ]、[^]
%:后面可以跟零个或多个字符
_:匹配任意单个字符
[ ]:查询一定范围内的单个字符,包括两端数据
[^]:表示不在一定范围内的单个字符,包括两端数据
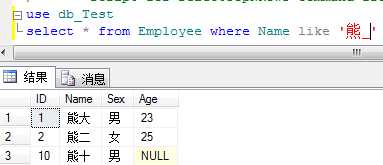
例:查询姓熊的员工并且名字只有两个字的员工信息
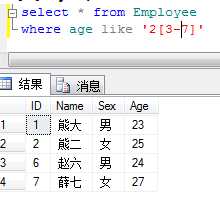
例:查询年龄在23-27周岁的员工信息
4.BETWEEN关键字
between...and 和not between and
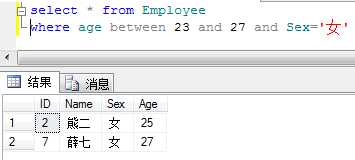
例:查询年龄在23-27周岁的女员工信息
5.is (not) null关键字
在where子句中,需要用is (not) null 判断空值,不能使用=判断空值
6.in关键字
用来指定列表搜索的条件;
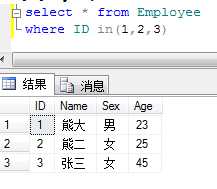
例:查询ID为1,2,3,的员工信息
7.ALL SOME ANY关键字
三者都作用于比较运算符和子查询之间,一般和嵌套查询一起用,Some和any等效
具体作用请看例子。all是大于最大者,any是小于最小者
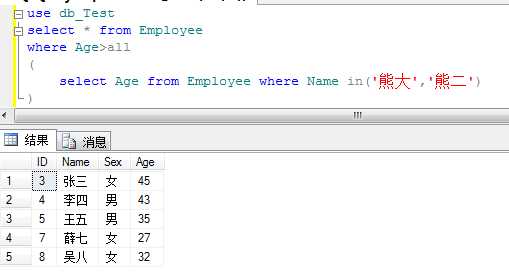
例:查询年龄大于熊大和熊二的员工信息
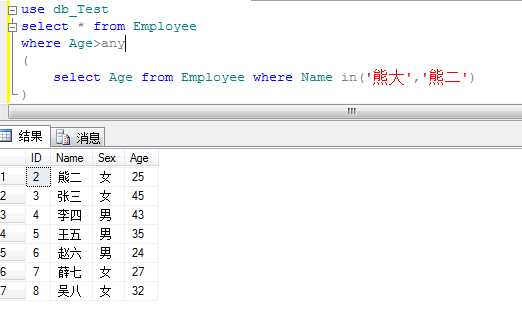
8.exists关键字
作用于子查询,指定行是否存在
9.Group by 子句
用于对表进行分组
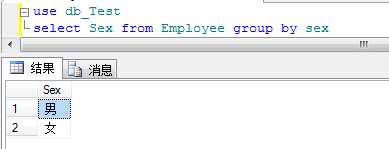
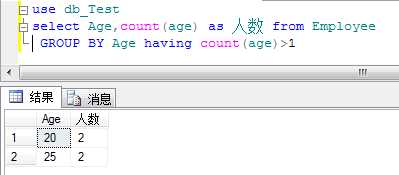
10.Having 子句
指定组或聚合的搜索条件,只能与select一起使用。
例:查询相同年龄段大于2人的员工信息
11.ORDER BY
在select返回的结果中排序;只有在指定了Top情况下,才能在视图、内联函数、派生表和子查询中起作用。
ORDER
例:将表中人员按照年龄大小降序排列
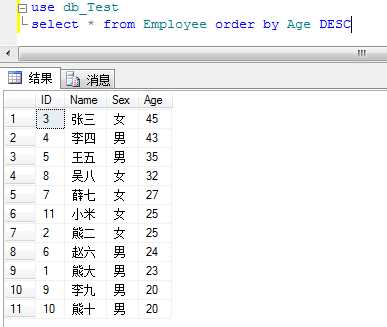
说明:order by 默认是升序排列
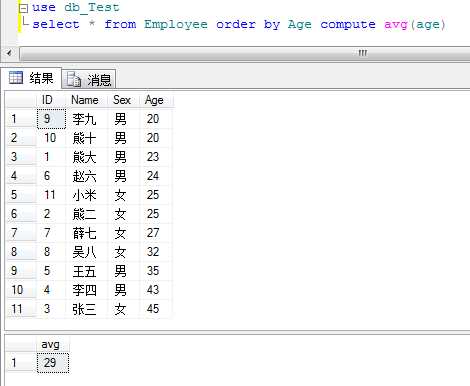
12.COMPUTE子句
生成合计,出现在结果列
例:计算表中员工的平均年龄
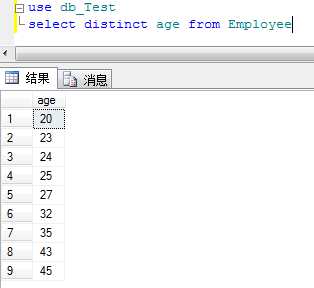
13.DISTINCT关键字
从select结果中去掉重复记录
例;去掉重复年龄
14.TOP关键字
例:从select结果中显示前4行