原帖地址:https://www.jiqizhixin.com/articles/2018-04-03-5
K 近邻算法,简称 K-NN。在如今深度学习盛行的时代,这个经典的机器学习算法经常被轻视。本篇教程将带你使用 Scikit-Learn 构建 K 近邻算法,并应用于 MNIST 数据集。然后,作者将带你构建自己的 K-NN 算法,开发出比 Scikit-Learn K-NN 更准更快的算法。
1. K 近邻分类模型
K 近邻算法是一种容易实现的监督机器学习算法,并且其分类性能的鲁棒性还不错。K-NN 最大的优点之一就是它是一个惰性算法,即该模型无须训练就可以对数据进行分类,而不像其他需要训练的 ML 算法,如 SVM、回归和多层感知机。
2. K-NN 如何工作
为了对给定的数据点 p 进行分类,K-NN 模型首先使用某个距离度量将 p 与其数据库中其它点进行比较。
距离度量就是类似欧几里得距离之类的标准,以两个点为输入并返回这两个点之间距离的简单函数。
因此,可以假设距离较小的两个点比距离较大的两个点相似度更高。这是 K-NN 的核心思想。
该过程将返回一个无序数组,其中数组中的每一项都表示 p 与模型数据库中 n 个数据点之间的距离。所以返回数组的大小为 n。
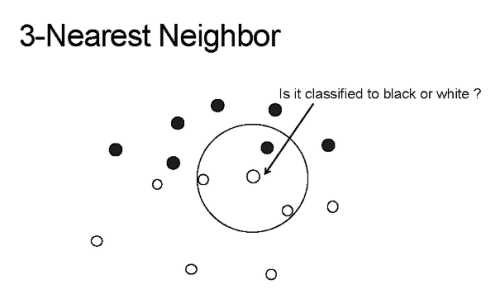
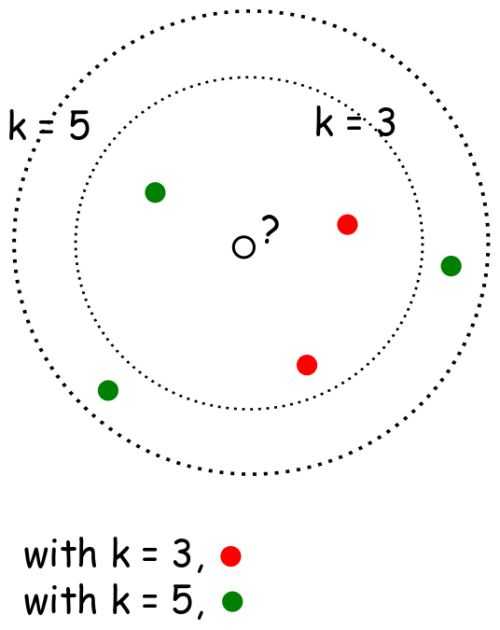
K 近邻的 K 的含义是:k 是一个任意值(通常在 3-11 之间),表示模型在对 p 分类时应该考虑多少个最相似的点。然后模型将记录这 k 个最相似的值,并使用投票算法来决定 p 属于哪一类,如下图所示。