标签:style blog http color io 使用 strong for div
记得刚学习C++那会这个问题曾困扰过我,后来慢慢形成了不管什么时候都用一维数组的习惯,再后来知道了在一维数组中提出首列元素地址进行二维调用的办法。可从来没有细想过这个问题,最近自己写了点代码测试下,虽然还是有些不明就里,不过结果挺有意思。
为了避免编译器优化过度,用的是写操作,int,测试分为不同大小的空间,同样大小空间不同的行和列数。分别记录逐行写入,逐列写入,按间隔写入,空间申请和释放的时间。
测试代码
一维数组的申请和释放
1 // Create 2 int *m = new int[n_row * n_col]; 3 4 // Free 5 delete [] m;
二维数组的申请和释放
1 // Create 2 int **m = new int*[n_row]; 3 for ( int i = 0; i < n_row; ++i ) 4 m[i] = new int[n_col]; 5 6 // Free 7 for ( int i = 0; i < n_row; ++i ) 8 delete [] m[i]; 9 delete [] m;
逐行写入
1 for ( int i = 0; i < n_row; ++i ) 2 { 3 for ( int j = 0; j < n_col; ++j ) 4 { 5 matrix[i * n_col + j] = answer; 6 // matrix[i][j] = answer; 7 } 8 }
逐列写入
1 for ( int j = 0; j < n_col; ++j ) 2 { 3 for ( int i = 0; i < n_row; ++i ) 4 { 5 matrix[i * n_col + j] = answer; 6 // matrix[i][j] = answer; 7 } 8 }
按间隔写入
1 for ( int i = 0; i < n_row; ++i ) 2 { 3 for ( int j = 0; j < n_col; ++j ) 4 { 5 int row = i * 7 % n_row; 6 int col = j * 11 % n_col; 7 matrix[i * n_col + j] = answer; 8 // matrix[i][j] = answer; 9 } 10 }
不是很确定这种测试是否很合理,不过大体上能体现我要测的东西了。需要注意的是逐行写入中为了简便我用的是写入一个叫answer的变量,其实情况应该更泛化,否则用memset或者std::fill也许会更快?逐列写入的代码本科课程级别的典型反面代码例子,这里也仅仅是为了测试。
仅仅从编译的角度来看主要的差别在下面两句:
1 matrix[i * n_col + j] = answer; 2 matrix[i][j] = answer;
来看一下对应的汇编代码:
1 ; matrix[i * n_col + j] = answer; 2 mov edx, DWORD PTR _i$3[ebp] 3 imul edx, DWORD PTR _n_col$[ebp] 4 add edx, DWORD PTR _j$2[ebp] 5 mov eax, DWORD PTR _matrix$[ebp] 6 mov ecx, DWORD PTR _answer$[ebp] 7 mov DWORD PTR [eax+edx*4], ecx
1 ; matrix[i][j] = answer; 2 mov ecx, DWORD PTR _i$4[ebp] 3 mov edx, DWORD PTR _matrix$[ebp] 4 mov eax, DWORD PTR [edx+ecx*4] 5 mov ecx, DWORD PTR _j$3[ebp] 6 mov edx, DWORD PTR _answer$[ebp] 7 mov DWORD PTR [eax+ecx*4], edx
都是6条指令,体系学得不好,所以也看不出哪个更快。这里用的是Visual Studio编译,因为本人gcc用得不熟,不知道怎么生成这么直观的汇编和C++对应,效率上而言Linux下还是比Windows高一些,不过为了统一,之后的测试也基于Windows。当然上面的是没有优化的编译,如果开了优化(VS /O2),汇编指令大概也都是4、5条的样子,因为/O2优化后的汇编代码结构不是很直观,这里就不贴了。(另一方面也是由于我的汇编水平很弱,看不出什么)
除了直接使用一维和二维数组,也可以对一维数组进行二维索引,方法是把一维数组中所有对应第一列的元素的地址单独作为一个指针数组,这样本质上还是一维数组,但是实现了形式上的二维数组调用,这种办法空间申请的代码如下:
1 // Create 2 int **m = new int*[n_row]; 3 int *block = new int[n_row * n_col]; 4 for ( int i = 0; i < n_row; ++i ) 5 m[i] = &block[i * n_col]; 6 return m;
释放的代码和二维数组相同。
用一维数组模拟二维调用的优点是既保证了内存空间的连续性,又保持了二维调用的代码易维护的优点。不过需要注意的是,由于是二维索引,汇编代码和二维数组还是一样的。
测试结果
执行上面的代码,在不同行数和列数下,循环执行取平均值,结果如下:
内存的申请和释放:
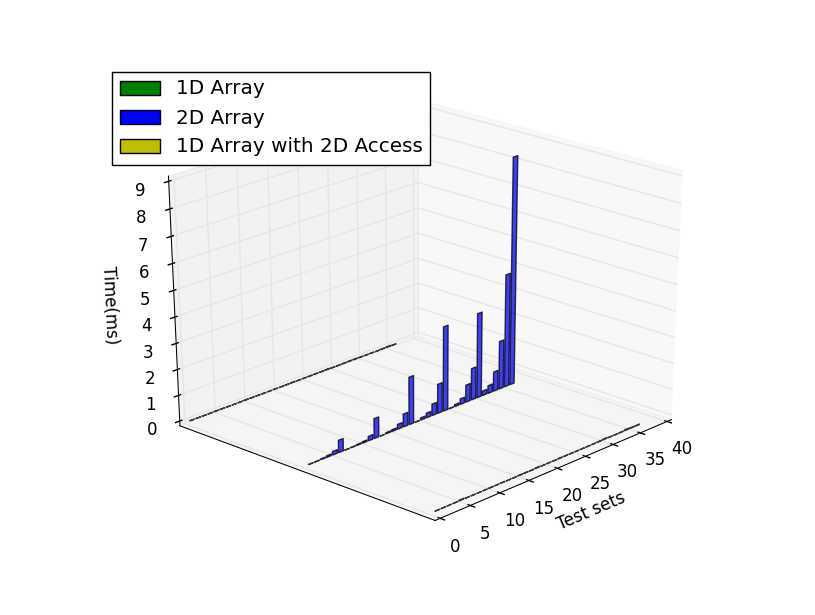
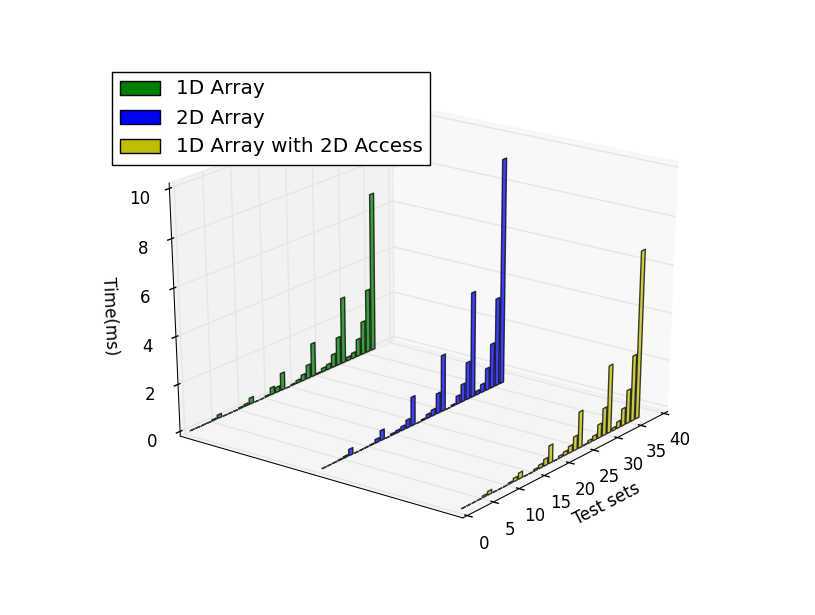
逐行访问
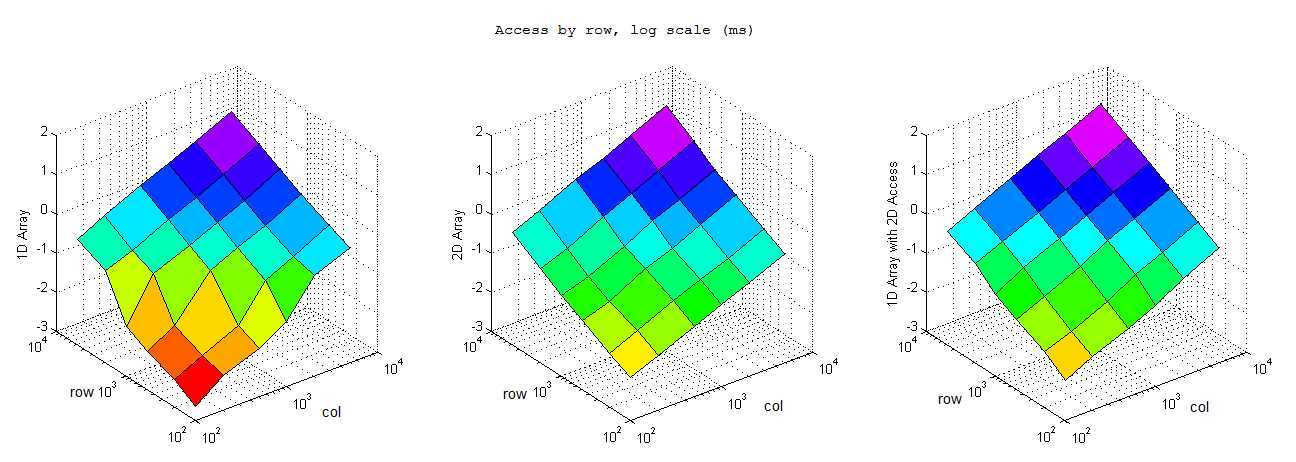
逐列访问
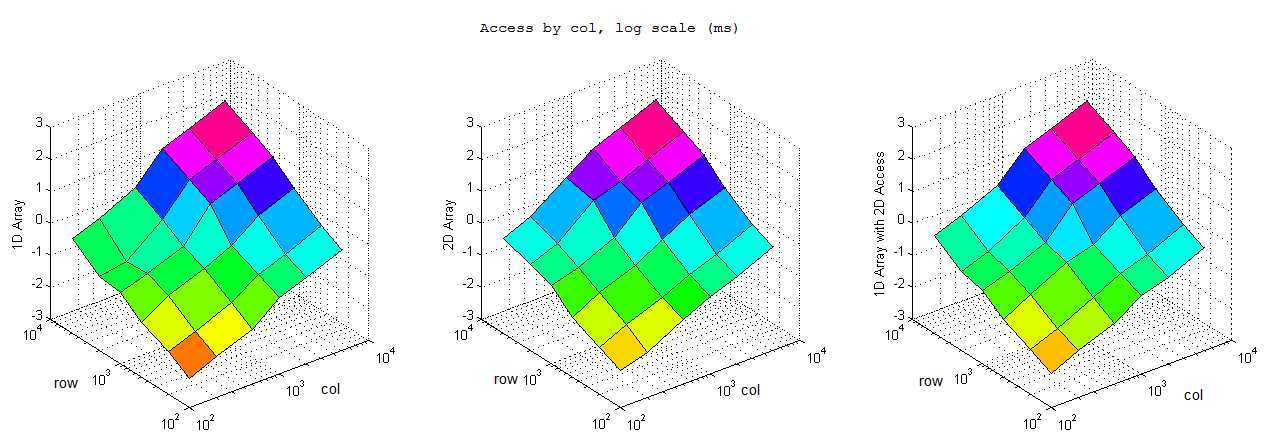
按间隔访问
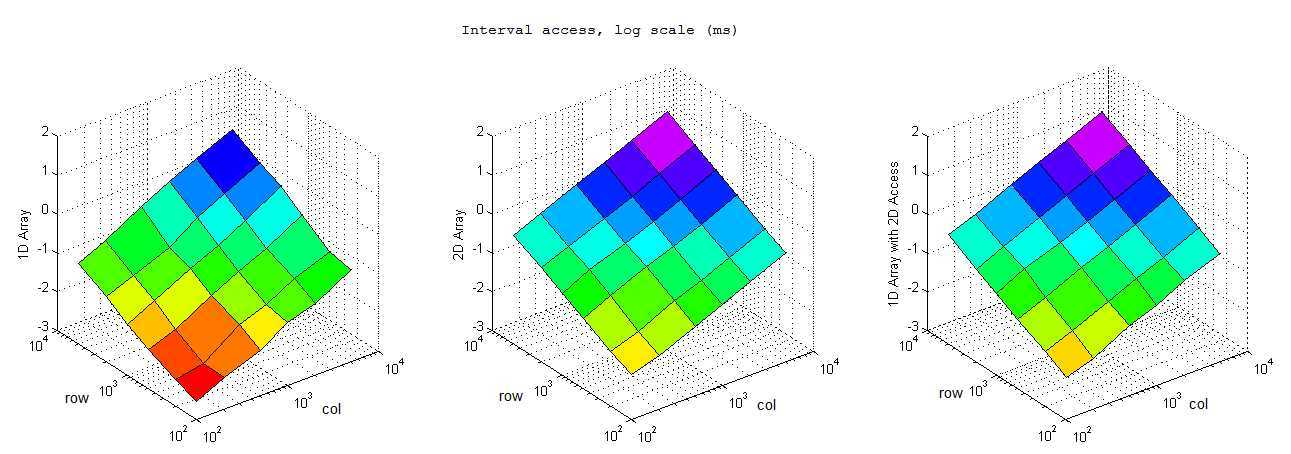
分析
内存的连续性:一维数组显然有着比二维数组更好的连续性,我忘了以前是在哪看到的一个形象的字符画说明一维数组和二维数组的区别,大概是下面这样子:
一维数组:
┌--┬--┬--┬--┬-
| | | | | ...
└--┴--┴--┴--┴-
二维数组:
┌--┬--┬--┬--┬-
| | | | | ...
└--┴--┴--┴--┴-
| | |
| | V
| | ┌--┬--┬--┬-
| | | | | | ...
| | └--┴--┴--┴-
| V
| ┌--┬--┬--┬--┬-
| | | | | | ...
| └--┴--┴--┴--┴-
V
┌--┬--┬--┬--┬--┬-
| | | | | | ...
└--┴--┴--┴--┴--┴-
缓存命中率:缓存是SRAM,内存是DRAM,效率差很多,所以如果能提高缓存中的命中率,效率能提高很多。其实这和上一条其实也有关联,显然连续的内存命中率会高,不过如果申请的内存空间非常大那具体问题得具体分析了。
指令执行速度:由于早年体系没学好,所以我也不知道这条有多大影响,另外现在的电脑都是多核的,作为不搞多核算法的人,不太懂会有多大影响。
对照结果可以看到基本上而言一维数组的效率完爆二维数组,尤其是内存申请和小内存访问的情况,总体而言效率上一维数组>一维数组的二维引用>二维数组。不过也有比较有意思的发现:1) 逐行访问的时候,在开辟内存空间小的时候一维数组二维索引效率高于二维数组,而大内存情况下却变慢了。2) 逐列访问基本符合预期,一维数组和一维数组二维索引效率接近,二维索引效率略低,但是都优于二维数组。3) 按间隔访问的时候一维数组大幅快于逐行访问,不太懂这是为什么,是否我电脑是多核的影响?还是说VS的O2编译的作用?
纯属蛋疼的测试,也相当不严谨,希望有体系知识比较丰富的大拿指点一二。
标签:style blog http color io 使用 strong for div
原文地址:http://www.cnblogs.com/frombeijingwithlove/p/3763250.html