这回两个爬虫协助作业,论坛爬虫先爬主贴,爬到主贴后启动帖子爬虫爬子贴。
代码多点了:
# 论坛爬虫,用于爬取主贴再爬子贴 from bs4 import BeautifulSoup import requests import threading import re import pymysql user_agent=‘Mozilla/4.0 (compatible;MEIE 5.5;windows NT)‘ headers={‘User-Agent‘:user_agent} # 论坛爬虫类(多线程) class forumCrawler(threading.Thread): def __init__(self,name,url): threading.Thread.__init__(self,name=name) self.name=name self.url=url self.infos=[] def run(self): print("线程"+self.name+"开始爬取页面"+self.url); try: rsp=requests.get(self.url,headers=headers) soup= BeautifulSoup(rsp.text,‘html.parser‘,from_encoding=‘utf-8‘) #print(rsp.text); # rsp.text是全文 # 找出span for spans in soup.find_all(‘span‘,class_="forumdisplay"): #找出link for link in spans.find_all(‘a‘): if link and link.get("href"): #print(link.get("href")) #print(link.text+‘\n‘) topicLink="http://www.55188.com/"+link.get("href") tc=topicCrawler(name=self.name+‘_tc#‘+link.get("href"),url=topicLink) tc.start() except Exception as e: print("线程"+self.name+"发生异常。")# 不管怎么出现的异常,就让它一直爬到底 print(e); # 帖子爬虫类(多线程) class topicCrawler(threading.Thread): def __init__(self,name,url): threading.Thread.__init__(self,name=name) self.name=name self.url=url self.infos=[] def run(self): while(self.url!="none"): print("线程"+self.name+"开始爬取页面"+self.url); try: rsp=requests.get(self.url,headers=headers) self.url="none"#用完之后置空,看下一页能否取到值 soup= BeautifulSoup(rsp.text,‘html.parser‘,from_encoding=‘utf-8‘) #print(rsp.text); # rsp.text是全文 # 找出一页里每条发言 for divs in soup.find_all(‘div‘,class_="postinfo"): #print(divs.text) # divs.text包含作者和发帖时间的文字 # 用正则表达式将多个空白字符替换成一个空格 RE = re.compile(r‘(\s+)‘) line=RE.sub(" ",divs.text) arr=line.split(‘ ‘) #print(len(arr)) arrLength=len(arr) if arrLength==7: info={‘楼层‘:arr[1], ‘作者‘:arr[2].replace(‘只看:‘,‘‘), ‘日期‘:arr[4], ‘时间‘:arr[5]} self.infos.append(info); elif arrLength==8: info={‘楼层‘:arr[1], ‘作者‘:arr[2].replace(‘只看:‘,‘‘), ‘日期‘:arr[5], ‘时间‘:arr[6]} self.infos.append(info); #找下一页所在地址 for pagesDiv in soup.find_all(‘div‘,class_="pages"): for strong in pagesDiv.find_all(‘strong‘): print(‘当前为第‘+strong.text+‘页‘) # 找右边的兄弟节点 nextNode=strong.next_sibling if nextNode and nextNode.get("href"): # 右边的兄弟节点存在,且其有href属性 #print(nextNode.get("href")) self.url=‘http://www.55188.com/‘+nextNode.get("href") if self.url!="none": print("有下一页,线程"+self.name+"前往下一页") continue else: print("无下一页,线程"+self.name+‘爬取结束,开始打印...‘) for info in self.infos: print(‘\n‘) for key in info: print(key+":"+info[key]) print("线程"+self.name+‘打印结束.‘) insertDB(self.name,self.infos) except Exception as e: print("线程"+self.name+"发生异常。重新爬行")# 不管怎么出现的异常,就让它一直爬到底 print(e); continue # 数据库插值 def insertDB(crawlName,infos): conn=pymysql.connect(host=‘127.0.0.1‘,user=‘root‘,passwd=‘12345678‘,db=‘test‘,charset=‘utf8‘) for info in infos: sql="insert into test.topic(floor,author,tdate,ttime,crawlername,addtime) values (‘"+info[‘楼层‘]+"‘,‘"+info[‘作者‘]+"‘,‘"+info[‘日期‘]+"‘,‘"+info[‘时间‘]+"‘,‘"+crawlName+"‘,now() )" print(sql) conn.query(sql) conn.commit()# 写操作之后commit不可少 conn.close() # 入口函数 def main(): for i in range(1,10): url=‘http://www.55188.com/forum-8-‘+str(i)+‘.html‘ tc=forumCrawler(name=‘fc#‘+str(i),url=url) tc.start() # 开始 main()
输出太多就不贴了,把插入数据后的数据库展示一下:
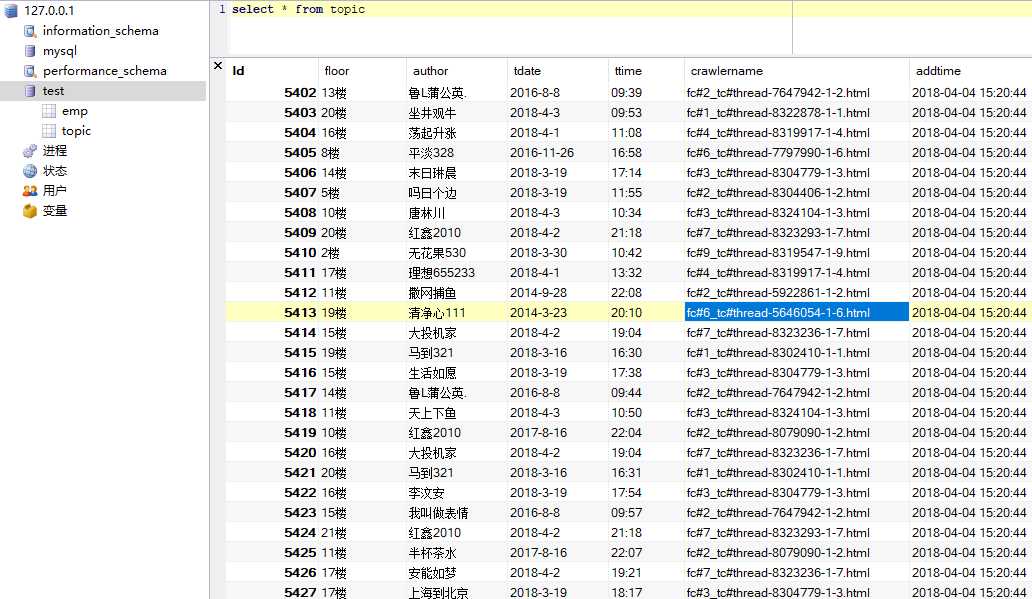
一会针对数据做个处理。