在序言中,我们提到函数式编程的两大特征:无副作用、函数是第一公民。现在,我们先来深入第一个特征:无副作用。
无副作用是通过引用透明(Referential transparency)来定义的。如果一个表达式满足将它替换成它的值,而程序的行为不变,则称这个表达式是引用透明的。
现在,我们不妨进行一个尝试:我们来实现一些函数,但是这次有一个限制:只能用无副作用的表达式。
先以素数判定为例子,我们要写一个函数bool IsPrime(int n),它返回这个整数是不是素数。简单起见,我们采用最朴素的方法:依次检查2~n-1的整数,如果存在n的因子,则返回false,否则返回true.
这种问题的原始做法是使用循环,但是使用循环需要修改循环变量的值,从而产生副作用。
那怎么办了?有一个和循环关系紧密的概念——递归。递归不会改变变量的值,我们尝试用递归实现。
直接对IsPrime递归似乎不太可行,我们需要写一个辅助方法IsPrimeLoop。这个方法的参数除了n以外还有一个辅助参数acc,这个辅助参数起到类似循环变量的作用,它表示当前我们正在尝试的因子。
那这个函数要怎么实现呢?我们约定从小到大枚举整数,那么当acc == n时,循环就结束了,返回true。若acc != n,则循环继续。接着我们需要判断acc是不是n的因子,如果是,则n不是素数,返回false,否则继续递归循环。
借助这个辅助函数,我们只要调用IsPrimeLoop(n, 2)就可以判断了。代码如下:
private static bool IsPrimeLoop(int n, int acc) => (acc == n) || (n % acc != 0 && IsPrimeLoop(n, acc + 1)); public static bool IsPrime(int n) => n >= 2 && IsPrimeLoop(n, 2);
注意到,这里的辅助函数IsPrimeLoop是私有的,因为这个函数是专门供IsPrime调用的,它的访问范围应该限制在IsPrime内。在C#6及以前,这是做不到的,只能把它设定为类私有尽可能减小访问范围。在C#7,我们可以利用内部函数进一步完善。
public static bool IsPrime(int n) { bool Loop(int acc) => (acc == n) || (n % acc != 0 && Loop(acc + 1)); return n >= 2 && Loop(2); }
这时我们的Loop函数可以省略掉参数n,而且Loop的访问范围被限制在了IsPrime内。这样,我们就能在无副作用的前提下,实现素数的判定函数。
注意到,由于我们的IsPrime函数没有用到任何有副作用的表达式,所以,我们可以保证调用IsPrime也不会产生任何副作用。一般的,如果一个函数满足对它的调用一定是引用透明的,我们称这个函数为纯函数。
下面我们来做一个练习,这里我需要你用递归实现阶乘函数int Fact(int n),当n>0时返回1*2*3*...*n的值,当n<=0时返回1,不考虑结果溢出的情况。你的实现不应该包含有副作用的表达式。
如果你完成了,请往下看。
下面我给出两个你可能的实现
public static int Fact(int n) => n <= 0 ? 1 : n * Fact(n - 1);
public static int Fact(int n) { int Loop(int acc, int result) => acc > n ? result : Loop(acc + 1, result * acc); return Loop(1, 1); }
当然,你的具体写法可能有所不同,但基本上可以归为两类。一类是像第一个那样,利用Fact(n)=n * Fact(n-1)进行递归;还有就是就像第二个那样,通过递归来让参数acc从1到n循环,并乘进一个结果变量result.
直观来看,第一个函数会更“递归”一点,而第二个函数则更像用递归实现的循环。为了进一步揭析这两个实现的区别,我们来手动展开一下两个版本的Fact(5)的递归过程:
版本一:
Fact(5) = 5 * Fact(4)
= 5 * 4 * Fact(3)
= 5 * 4 * 3 * Fact(2)
= 5 * 4 * 3 * 2 * Fact(1)
= 5 * 4 * 3 * 2 * 1 * Fact(0)
= 5 * 4 * 3 * 2 * 1 * 1
= 120
版本二:
Fact(5) = Loop(1, 1)
= Loop(2, 1)
= Loop(3, 2)
= Loop(4, 6)
= Loop(5, 24)
= Loop(6, 120)
= 120
发现没有?版本一的式子会逐渐变长,而版本二的式子长度则保持不变。这是因为,后者是尾递归。尾递归的定义为递归调用被立刻返回的递归。尾递归的特点是它理论上不需要额外的空间存储递归信息,就像我们展开式子那样,尾递归占用的空间是恒定的,而非尾递归调用则需额外的空间储存信息。事实上,尾递归和循环是等价的,因为尾递归可以想象成跳转到函数开头,只不过这个“跳转”是无副作用的。因此,我们可以用尾递归去实现循环,从而去除副作用。由于尾递归具有这种好处,我们通常尽可能的使用尾递归,只有在无法转换成尾递归,或者递归层数不大时,才使用非尾递归。
注意到我前面提到尾递归理论上不需要额外空间,但是很多语言在实现尾递归的时候会消耗栈空间的。比如JVM的尾递归会消耗栈空间,一些诸如Scala等编译到JVM的语言会将尾递归转换成循环从而防止栈溢出。但是C#编译器没有这个操作,那.NET在进行尾递归时会消耗栈空间吗?我们不妨来试一下。我的测试环境是.NET Core,使用之前定义的IsPrime函数,然后给它传入int.MaxValue,运行。
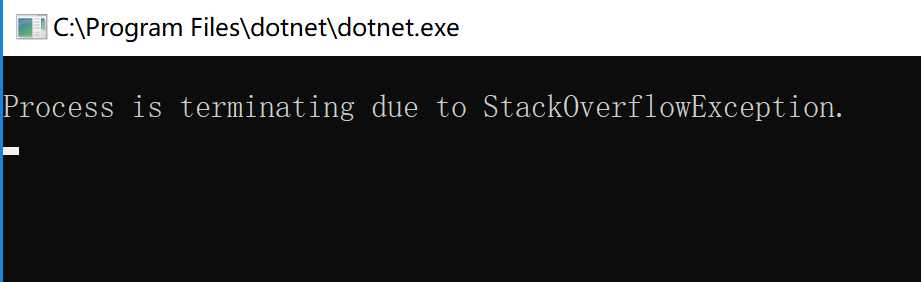
嗯,栈溢出了。
根据目前的实验结果,.NET在实现尾递归时会消耗栈空间。但是我用的是Debug模式,那切换到Release模式会怎样呢?
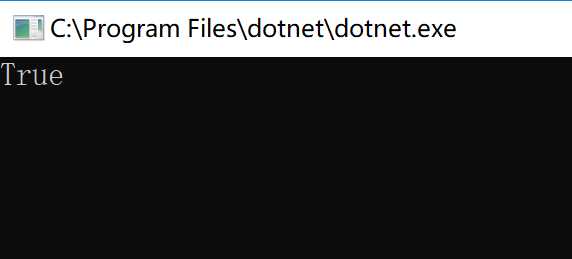
哈!没有溢出!
从上面实验可以看出,.NET Core在Debug模式下尾递归会消耗栈空间,Release模式不会。
因此,我们可以通过打开Release模式来避免尾递归产生栈溢出错误。
现在,递归相关的知识已经介绍完了。现在我们来讲讲递归的价值。
有的人觉得既然循环可以解决问题,那就没必要花时间去学什么递归;而有的人则觉得循环是魔鬼的,都应该改成递归。事实上,这两种极端的想法都是错误的。
递归的价值在于它能保证你写的函数是纯函数,从而降低一些意外的副作用产生的可能性。还记得序言的那个例子吗?那个程序就可以用尾递归实现来避免bug的产生。
当然,如果你要我写一个阶乘算法,或者写一个素数判断算法,我肯定用for循环。因为这个函数足够简单,我有自信做到,即使我的函数产生了副作用,但是这个副作用只是局部的,整个函数还是纯的函数。
但是,当程序复杂时,尤其是产生闭包时,这些副作用会比较隐晦,此时,使用尾递归能降低代码出错的几率。
尾递归还有一种好处:它能减少代码逻辑上的复杂性。我见过有一些好几重循环嵌套的程序,循环变量之间还相互依赖,逻辑非常复杂。但是,如果你把它改成尾递归,你就需要将循环转为一个或多个递归函数,从而使得逻辑结构更加的清晰。
最后,用一句话总结,递归应该减少你的负担,而不是成为你的负担。
习题:
一、用尾递归改写序言中提到的副作用产生bug的例子。
二、对于斐波那契数列数列fib(n)定义为:当n<=2时,fib(n)=1;当n>2时,fib(n)=fib(n-1)+fib(n-2)。分别用尾递归和非尾递归实现fib,并比较两个实现的效率差异。你能解释其中的原因吗?