Generative Adversarial Nets(简称GAN)是一种非常流行的神经网络。 它最初是由Ian Goodfellow等人在NIPS 2014论文中介绍的。 这篇论文引发了很多关于神经网络对抗性训练的兴趣,论文的引用次数已接近2700+。 许多变形的GAN出现了:DCGAN,Sequence-GAN,LSTM-GAN等。在NIPS 2016中,甚至会有整个专门针对对抗训练的研讨会!
首先,让我们回顾一下这篇论文的要点。 之后,我们将尝试使用TensorFlow和MNIST数据实现GAN。
Generative Adversarial Nets
考虑两个人,一个是制造假币的犯罪分子,另一个是鉴别假币的警察。 我们可以想象下犯罪分子的目标是什么,以及假冒伪劣货币的目的是什么? 让我们列举一下:
- 成为一个成功伪造假币的犯罪分子,从而欺骗警察的“法眼”,这样警察就不能分辨出伪造的钱和真钱之间的区别
- 维护“正义”,警察希望尽可能地发现假币
在此,我们看到了犯罪分子和警察之间存在利益冲突。 这种情况可以看成是一个博弈论中的minimax Game。 我们把这个过程称为对抗过程。
生成对抗网络(GAN)可以看成是对抗过程中的一个特例,其中警察和犯罪份子可以分别modeled as 神经网络。 第一个网络生成数据,第二个网络试图分辨真实数据和第一个网络生成的假数据之间的差异。 第二个网络将输出表示实际数据概率的标量[0,1]。
在GAN中,第一个网络被称为生成器G(Z)(Generator Net),第二个网络被称为判别器D(X)(Discriminator Net)。
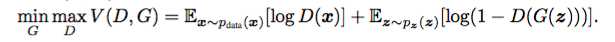
若达到了minimax Game中的最优的平衡点,第一个网络将非常的神奇的能够对实际数据进行建模(生成“实际数据”,骗过判别器D(X)),第二个网络将输出0.5的概率,i.e. 第一个网络的输出=真实数据。
到这里,你可能会萌生一个问题,“GAN应该怎么被训练呢?”。 这是因为数据的概率分布Pdata可能是一个非常复杂的分布,非常难以推断。 因此,如果有一台生成器可以从Pdata生成样本,而无需处理令人讨厌的概率分布(i.e. 不需要知道具体的概率分布表达式),那应该是极好的了吧! 有了这样一个生成器(从Pdata采样的过程),我们可以使用训练的生成网相廉价地地获取样本。
GAN Implementation
根据GAN的定义,我们需要两个网络。 网络的形式可以是五花八门的,无论是像convnet或只是一个两层神经网络复杂的网络都是ok的。 为了方便起见,G(z)和D(X)都使用两层的神经网络。使用的框架为TensorFlow。


# Discriminator Net X = tf.placeholder(tf.float32, shape=[None, 784], name=‘X‘) D_W1 = tf.Variable(xavier_init([784, 128]), name=‘D_W1‘) D_b1 = tf.Variable(tf.zeros(shape=[128]), name=‘D_b1‘) D_W2 = tf.Variable(xavier_init([128, 1]), name=‘D_W2‘) D_b2 = tf.Variable(tf.zeros(shape=[1]), name=‘D_b2‘) theta_D = [D_W1, D_W2, D_b1, D_b2] # Generator Net Z = tf.placeholder(tf.float32, shape=[None, 100], name=‘Z‘) G_W1 = tf.Variable(xavier_init([100, 128]), name=‘G_W1‘) G_b1 = tf.Variable(tf.zeros(shape=[128]), name=‘G_b1‘) G_W2 = tf.Variable(xavier_init([128, 784]), name=‘G_W2‘) G_b2 = tf.Variable(tf.zeros(shape=[784]), name=‘G_b2‘) theta_G = [G_W1, G_W2, G_b1, G_b2] def generator(z): G_h1 = tf.nn.relu(tf.matmul(z, G_W1) + G_b1) G_log_prob = tf.matmul(G_h1, G_W2) + G_b2 G_prob = tf.nn.sigmoid(G_log_prob) return G_prob def discriminator(x): D_h1 = tf.nn.relu(tf.matmul(x, D_W1) + D_b1) D_logit = tf.matmul(D_h1, D_W2) + D_b2 D_prob = tf.nn.sigmoid(D_logit) return D_prob, D_logit
根据上面的代码,generator(z)函数接受一个100维向量并return 786维向量,即MNIST图像(28x28)。 注意,z(G(z))是先验的。 以上述方式,生成器k学习先验分布(隐变量z)到实际分布Pdata之间的映射。
discriminator(x)函数接受MNIST图像并返回表示真实MNIST图像概率的标量。
现在,阐述下Adversarial Process是如何训练GAN的。 以下是论文中的训练算法:

G_sample = generator(Z) D_real, D_logit_real = discriminator(X) D_fake, D_logit_fake = discriminator(G_sample) D_loss = -tf.reduce_mean(tf.log(D_real) + tf.log(1. - D_fake)) G_loss = -tf.reduce_mean(tf.log(D_fake))
在上面,我们使用负号作为损失函数,TensorFlow优化器只能做最小化。
另外,根据其它资料的建议,最好使用tf.reduce_mean(tf.log(D_fake))最大化,而不是最小化上述算法中的tf.reduce_mean(1 - tf.log(D_fake))。
然后,我们可以开始对抗训练了:
# Only update D(X)‘s parameters, so var_list = theta_D D_solver = tf.train.AdamOptimizer().minimize(D_loss, var_list=theta_D) # Only update G(X)‘s parameters, so var_list = theta_G G_solver = tf.train.AdamOptimizer().minimize(G_loss, var_list=theta_G) def sample_Z(m, n): ‘‘‘Uniform prior for G(Z)‘‘‘ return np.random.uniform(-1., 1., size=[m, n]) for it in range(1000000): X_mb, _ = mnist.train.next_batch(mb_size) _, D_loss_curr = sess.run([D_solver, D_loss], feed_dict={X: X_mb, Z: sample_Z(mb_size, Z_dim)}) _, G_loss_curr = sess.run([G_solver, G_loss], feed_dict={Z: sample_Z(mb_size, Z_dim)})
到此,我们已经完成了! 我们可以通过抽样查看培训过程:
