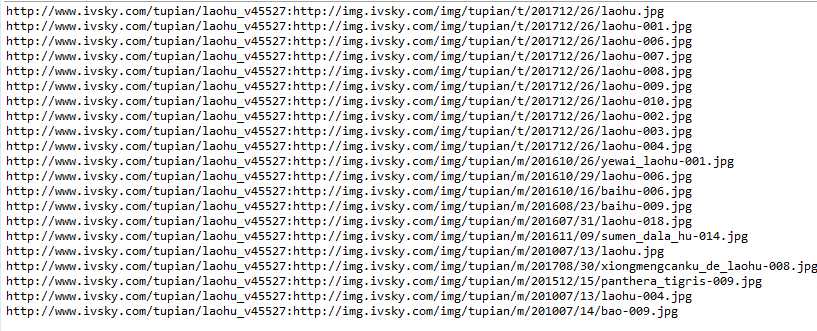
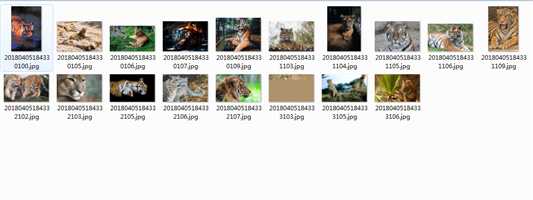
package com.ij34.JsoupTest; import java.io.File; import java.io.FileOutputStream; import java.io.InputStream; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLEncoder; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Random; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class JsoupTest { public static void downImages(String filePath,String imgUrl) throws Exception { //获取网址 String beforeUrl = imgUrl.substring(0,imgUrl.lastIndexOf("/")+1); //图片url后面的图片名字 String fileName = imgUrl.substring(imgUrl.lastIndexOf("/")+1); String newFileName = URLEncoder.encode(fileName, "UTF-8"); //"+"替换为UTF-8中的空格 newFileName = newFileName.replaceAll("\\+", "\\%20"); //编码之后的url imgUrl = beforeUrl + newFileName; //创建文件目录 File files = new File(filePath); if (!files.exists()) { files.mkdirs(); } URL url = new URL(imgUrl); HttpURLConnection connection = (HttpURLConnection)url.openConnection(); InputStream is = connection.getInputStream(); Date day=new Date(); SimpleDateFormat df = new SimpleDateFormat("yyyyMMddHHmmss"); Random ra=new Random(); int Num=ra.nextInt(11)+100; String fn=df.format(day)+Num; //去图片的格式例如.jpg .jpeg int lastIndex=fileName.lastIndexOf("."); String result=fileName.substring(lastIndex); File file = new File(filePath +fn+ result); FileOutputStream out = new FileOutputStream(file); int i = 0; while((i = is.read()) != -1){ out.write(i); } } public static void main(String[] args) throws Exception { //int[] a=new int[]{}; //for(int i=a.length-1;i>=0;i--){ //爬取的网址 String url = "http://www.ivsky.com/tupian/laohu_v45527";//+a[i]; String savePath = "D://webmagic//"; Document document = Jsoup.connect(url).get(); Elements elements = document.getElementsByTag("img"); for(Element element : elements){ //图片的绝对路径 String imgSrc = element.attr("abs:src"); //取jpg格式 if(imgSrc.contains(".jpg")){ downImages(savePath, imgSrc); System.out.println(url+":"+imgSrc); } } // } } }