在正式爬取之前,先做一个试验,看一下爬取的数据对象的类型是如何转换为列表的:
写一个html文档:
x.html
<html><head><title>This is a python demo page</title></head> <body> <p class="title"> <a>The demo python introduces several python courses.</a> <a href="http://www.icourse163.org/course/BIT-133" class="py1" id="link1">Basic Python</a> </p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a> </p> </body></html>
# coding:utf-8 from bs4 import BeautifulSoup import requests import bs4 soup = BeautifulSoup(open(‘D:/x.html‘, encoding=‘utf-8‘), "html.parser") print(soup.find(‘body‘,).children) # .children返回可迭代对象,不是列表,需要用for循环遍历其中的内容 for t in soup.find(‘body‘).children: 迭代<body>标签的儿子节点 if isinstance(t, bs4.element.Tag): # 判断子节点是否为Tag对象(因为子节点会包含如换行符之类的节点) print(‘body的子标签的内容是:‘, t) # 查看t变量获得的对象内容,body的子标签为p标签,一组<p></p>表示一个对象 print(‘t的类型是:‘, type(t)) # 查看t的类型
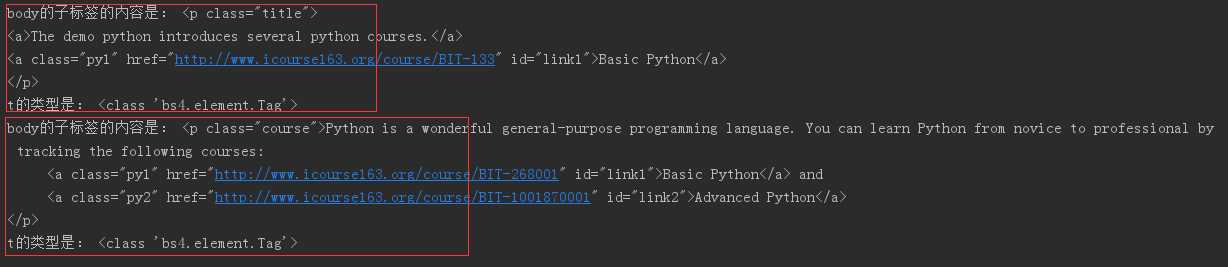
可以看到每个t对象的类型是bs4.element.Tag,也就是标签对象。
那么,如果要从每个t对象中获取a标签的内容,并把所有a标签都保存到一个列表中,该如何做?
可以使用:
list = t(‘a‘) # t(‘a‘)会生成一个bs4.element.ResultSet类型的数据对象,实际上就是Tag列表
for t in soup.find(‘body‘).children: if isinstance(t, bs4.element.Tag): # 判断子标签是否为Tag对象(因为子节点会包含如换行符之类的节点) # print(‘body的子标签的内容是:‘, t) # 查看t变量获得的对象内容 # print(‘t的类型是:‘, type(t)) # 查看t的类型 list = t(‘a‘) # 循环获取每个t对象中的所有a标签,并保存到一个列表中 print(list) print(type(list)) print(‘每个p标签的第一个a标签的内容:‘, list[0].string) # a标签保存到列表后,便可以利用列表方法解析出其中的具体每个a标签对象,并利用.string获取标签字符串

接下来就可以正式编写爬虫了:
分析网页源代码
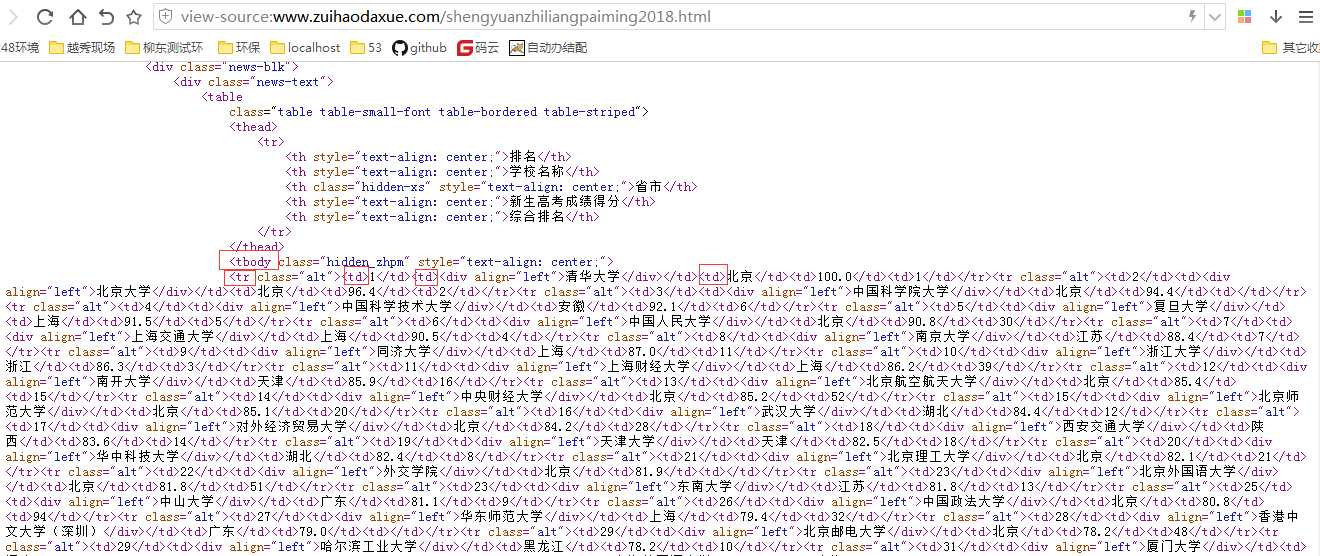
可以看到需要的一些信息如大学排名、大学名称、地址、分数等分别在如图标注的地方,每个大学信息所在的标签结构如下:所有大学信息都在<tbody>标签下,每个大学都在各自的<tr>标签,然后大学自身的排名、名称、地址等信息都分别由一个<td>标签包裹。
思路如下:先找到<tbody>下的所有标签内容,然后再从中找出所有<tr>标签内容(为什么不直接用find_all()找<tr>?因为不只有我们需要的大学信息用到了<tr>标签,<tbody>之外也有用到<tr>标签来包裹内容的)。
我要把每个学校的“排名、名称、地址、分数”的值都取出来,并且把每组数据都各自装在一个列表中,然后再把每个列表依次加到一个大列表里
(1)直接处理数据
from bs4 import BeautifulSoup import requests import bs4 url = ‘http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html‘ r = requests.get(url) r.encoding = r.apparent_encoding # 转换编码,不然中文会显示乱码,也可以r.encoding = ‘utf-8‘ html = r.text soup = BeautifulSoup(html, ‘html.parser‘) # 获取爬取网页的BeautifulSoup对象 for tr in soup.find(‘tbody‘).children: if isinstance(tr, bs4.element.Tag): td = tr(‘td‘)
print(‘td‘) t = [td[0].string, td[1].string, td[2].string, td[3].string] # 把每个学校解析出的数据各自装到一个列表中
print(t)
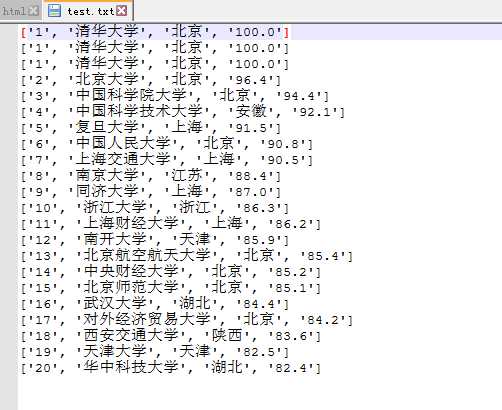
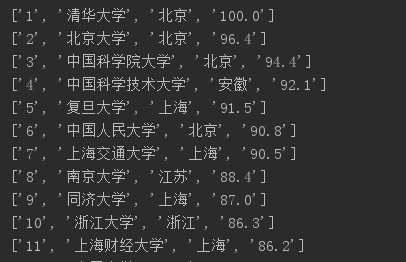
打印td的结果:

打印t的结果如下,其实排名信息已经可以看出来了
然后依次把每个大学信息写入一个文本文档:
from bs4 import BeautifulSoup import requests import bs4 url = ‘http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html‘ r = requests.get(url) r.encoding = r.apparent_encoding # 转换编码,不然中文会显示乱码,也可以r.encoding = ‘utf-8‘ html = r.text soup = BeautifulSoup(html, ‘html.parser‘) # 获取爬取网页的BeautifulSoup对象 for tr in soup.find(‘tbody‘).children: if isinstance(tr, bs4.element.Tag): td = tr(‘td‘) t = [td[0].string, td[1].string, td[2].string, td[3].string] # 把每个学校解析出的数据各自装到一个列表中print(t) with open(‘D:/test.txt‘,‘a‘) as data: # 以‘a‘模式打开文件,即可不停的追加写入而不改变原内容
print(t, file=data)
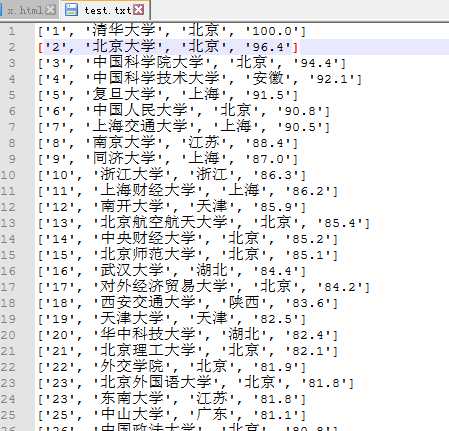
(2)把代码封装,写到函数中
# coding:utf-8 import requests import bs4 from bs4 import BeautifulSoup def get_html(url):
"""定义获取网页源码函数""" try: r = requests.get(url, timeout=20) r.encoding = r.apparent_encoding return r.text except: return None def get_data(html, list):
"""定义从网页源码获取数据并处理数据函数""" soup = BeautifulSoup(html, ‘html.parser‘) for tr in soup.find(‘tbody‘).children: if isinstance(tr, bs4.element.Tag): td = tr(‘td‘) t = [td[0].string, td[1].string, td[2].string, td[3].string] # 把每个学校解析处的数据各自装到一个列表中 list.append(t) # 把每个学校信息列表都追加到一个大列表中,方便后面写入文件 # return list # 不能加return,造成的后果就是第一次循环时就把结果返回出去了,只取到了第一条数据 def write_data(ulist, num): # num参数,控制提取多少组数据写入文件
"""定义把数据写入文件函数""" for i in range(num): u = ulist[i] with open(‘D:/test.txt‘, ‘a‘) as data: print(u, file=data) if __name__ == ‘__main__‘: list = [] # 我之前是把list=[]放到get_data()函数的for循环里面了,导致每次循环都会先清空列表,然后再追加数据,结果最后遍历完只剩最后一组数据。。。
url = ‘http://www.zuihaodaxue.com/shengyuanzhiliangpaiming2018.html‘
html = get_html(url)
get_data(html, list)
write_data(list, 20)