数据结构和算法
Python 提供了大量的内置数据结构,包括列表,集合以及字典。大多数情况下使 用这些数据结构是很简单的。但是,我们也会经常碰到到诸如查询,排序和过滤等等 这些普遍存在的问题。因此,这一章的目的就是讨论这些比较常见的问题和算法。另外,我们也会给出在集合模块 collections 当中操作这些数据结构的方法。
1.解压序列赋值给多个变量
问题
现在有一个包含 N 个元素的元组或者是序列,怎样将它里面的值解压后同时赋值 给 N 个变量?
解决
任何序列可以通过一个简单的赋值语句解压给多个变量,唯一的前提是,变量的数量需要与序列的元素数量一样。
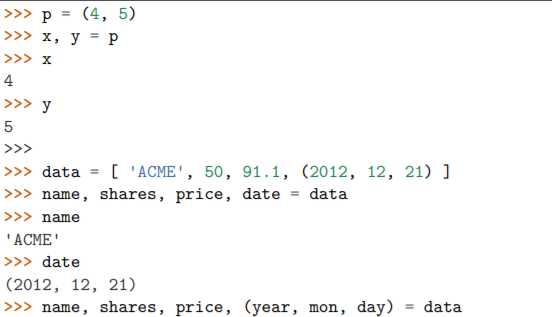
代码示例:

讨论
实际上,这种解压赋值可以用在任何可迭代对象上面,而不仅仅是列表或者元组。 包括字符串,文件对象,迭代器和生成器。
代码示例:

有时候,可能只想解压一部分,丢弃其他的值。对于这种情况 Python 并没有提 供特殊的语法。但是可以使用任意变量名去占位,到时候丢掉这些变量就行了。
代码示例:
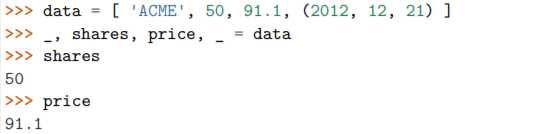
必须保证选用的那些占位变量名在其他地方没被使用到。
2.解压可迭代对象赋值给多个变量
问题
如果一个可迭代对象的元素个数超过变量个数时,会抛出一个 ValueError 。那么怎样才能从这个可迭代对象中解压出 N 个元素出来?
解决
Python 的星号表达式可以用来解决这个问题。比如,在学习一门课程,在学期末的时候,想统计下家庭作业的平均成绩,但是排除掉第一个和最后一个分数。如果只有四个分数,可能就直接去简单的手动赋值,但如果有 24 个呢?这时候星号表达式就派上用场了:
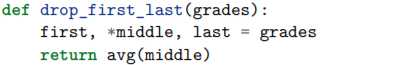
值得注意的事,星号表达式解压出来的变量永远是列表类型。
星号表达式也能用在列表的开始部分。比如,有一个公司前8个月销售数据的序列,但是想看下最近一个月数据和前面7个月的平均值的对比。可以这样做:
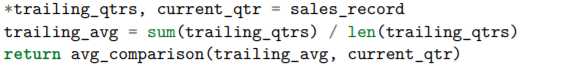
讨论
扩展的迭代解压语法是专门为解压不确定个数或任意个数元素的可迭代对象而设计的。通常,这些可迭代对象的元素结构有确定的规则(比如第1个元素后面都是电话号码),星号表达式让开发人员可以很容易的利用这些规则来解压出元素来。而不是通过一些比较复杂的手段去获取这些关联的的元素值。值得注意的是,星号表达式在迭代元素为可变长元组的序列时是很有用的。比如,下面是一个带有标签的元组序列:

有时候,你想解压一些元素后丢弃它们,你不能简单就使用 * ,但是你可以使用一 个普通的废弃名称,比如_或者ign。
代码示例:

3.保留最后 N 个元素
问题
在迭代操作或者其他操作的时候,怎样只保留最后有限几个元素的历史记录?
解决方案
保留有限历史记录正是 collections.deque 大显身手的时候。比如,下面的代码在多行上面做简单的文本匹配,并返回匹配所在行的前 N 行:

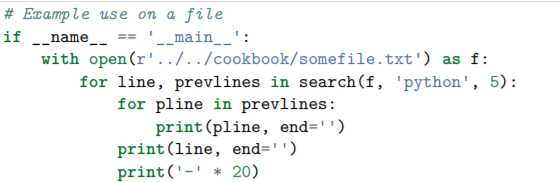
讨论
我们在写查询元素的代码时,通常会使用包含 yield 表达式的生成器函数,也就是我们上面示例代码中的那样。这样可以将搜索过程代码和使用搜索结果代码解耦。
使用 deque(maxlen=N) 构造函数会新建一个固定大小的队列。当新的元素加入并 且这个队列已满的时候,最老的元素会自动被移除掉。
代码示例:

尽管也可以手动在一个列表上实现这一的操作 (比如增加、删除等等)。但是这里的队列方案会更加优雅并且运行得更快些。更一般的, deque 类可以被用在任何只需要一个简单队列数据结构的场合。如果不设置最大队列大小,那么就会得到一个无限大小队列,可以在队列的两端执行添加和弹出元素的操作。
代码示例:


在队列两端插入或删除元素时间复杂度都是 O(1) ,而在列表的开头插入或删除元素的时间复杂度为 O(N) 。
4 .查找最大或最小的 N 个元素
问题
怎样从一个集合中获得最大或者最小的 N 个元素列表?
解决方案
heapq 模块有两个函数:nlargest() 和 nsmallest() 可以完美解决这个问题。

两个函数都能接受一个关键字参数,用于更复杂的数据结构中:

上面代码在对每个元素进行对比的时候,会以 price 的值进行比较。
讨论
如果你想在一个集合中查找最小或最大的 N 个元素,并且 N 小于集合元素数量, 那么这些函数提供了很好的性能。因为在底层实现里面,首先会先将集合数据进行堆 排序后放入一个列表中:
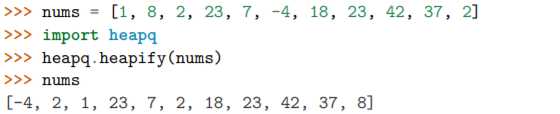
堆数据结构最重要的特征是 heap[0] 永远是最小的元素。并且剩余的元素可以很 容易的通过调用 heapq.heappop() 方法得到,该方法会先将第一个元素弹出来,然后 用下一个最小的元素来取代被弹出元素 (这种操作时间复杂度仅仅是 O(log N),N 是 堆大小)。比如,如果想要查找最小的 3 个元素,你可以这样做:
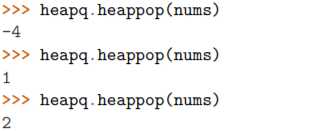
当要查找的元素个数相对比较小的时候,函数 nlargest() 和 nsmallest() 是很 合适的。如果你仅仅想查找唯一的最小或最大 (N=1) 的元素的话,那么使用 min() 和 max() 函数会更快些。类似的,如果 N 的大小和集合大小接近的时候,通常先排序这 个集合然后再使用切片操作会更快点 ( sorted(items)[:N] 或者是 sorted(items)[- N:] )。需要在正确场合使用函数 nlargest() 和 nsmallest() 才能发挥它们的优势 (如果 N 快接近集合大小了,那么使用排序操作会更好些)。 尽管你没有必要一定使用这里的方法,但是堆数据结构的实现是一个很有趣并且值 得你深入学习的东西。基本上只要是数据结构和算法书籍里面都会有提及到。 heapq 模块的官方文档里面也详细的介绍了堆数据结构底层的实现细节。
5. 实现一个优先级队列
问题
怎样实现一个按优先级排序的队列?并且在这个队列上面每次 pop 操作总是返回 优先级最高的那个元素?
解决方案
下面的类利用 heapq 模块实现了一个简单的优先级队列:


下面是它的使用方式:
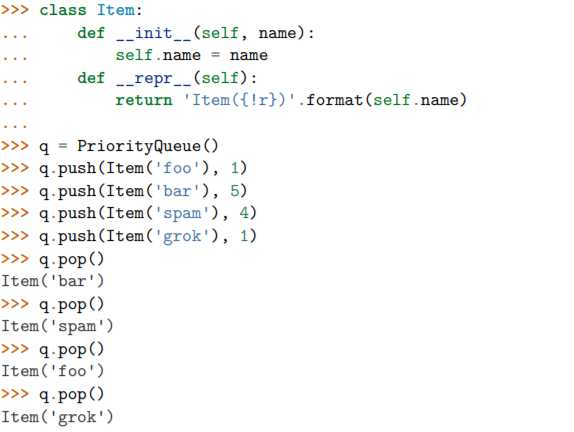
仔细观察可以发现,第一个 pop() 操作返回优先级最高的元素。另外注意到如果 两个有着相同优先级的元素 ( foo 和 grok ),pop 操作按照它们被插入到队列的顺序返 回的。
讨论
这一小节我们主要关注 heapq 模块的使用。 函数 heapq.heappush() 和 heapq.heappop() 分别在队列 queue 上插入和删除第一个元素,并且队列 queue 保证 第一个元素拥有最小优先级 。heappop() 函数总是返回” 最小的” 的元素,这就是保证队列 pop 操作返回正确元素的关键。另外,由于 push 和 pop 操作时间复杂度为 O(log N),其中 N 是堆的大小,因此就算是 N 很大的时候它们 运行速度也依旧很快。 在上面代码中,队列包含了一个 (-priority, index, item) 的元组。优先级为负数的目的是使得元素按照优先级从高到低排序。这个跟普通的按优先级从低到高排序 的堆排序恰巧相反。 index 变量的作用是保证同等优先级元素的正确排序。通过保存一个不断增加的 index 下标变量,可以确保元素按照它们插入的顺序排序。而且, index 变量也在相同优先级元素比较的时候起到重要作用。
为了阐明这些,先假定 Item 实例是不支持排序的:

如果你使用元组 (priority, item) ,只要两个元素的优先级不同就能比较。但是 如果两个元素优先级一样的话,那么比较操作就会跟之前一样出错:

通过引入另外的 index 变量组成三元组 (priority, index, item) ,就能很好的 避免上面的错误,因为不可能有两个元素有相同的 index 值。Python 在做元组比较时 候,如果前面的比较以及可以确定结果了,后面的比较操作就不会发生了:
