标签:case base lap show 使用 商品 组织 win 数据
安装好数据库之后,不能修改计算机名字,否则无法启动!
下载官网:
http://www.oracle.com/technetwork/database/enterprise-edition/downloads/index.html
下载相应的2个压缩文件。
同时选中2个压缩文件,解压到一个目录下。
1:找到并点击:

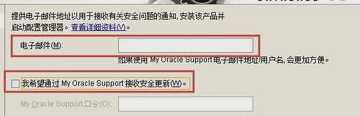
2:配置安全更新。电子邮件可写可不写,取消下面的"我希望通过My Oracle Support接受安全更新(W)",如下图所示,单击下一步。
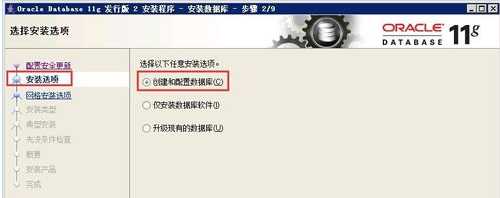
3:安装选项。直接选择默认的"创建和配置数据库",如下图所示,单击下一步
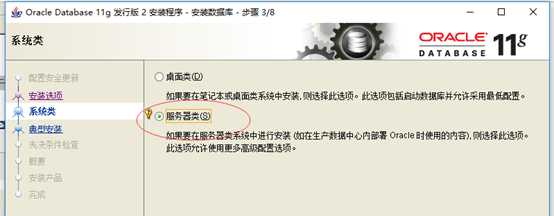
4:系统类。由于咱们安装的是服务器,所以选择"服务器类",如下图所示,单击下一步。
5:网格安装选项。选择"单实例数据库安装",如下图所示,单击下一步。: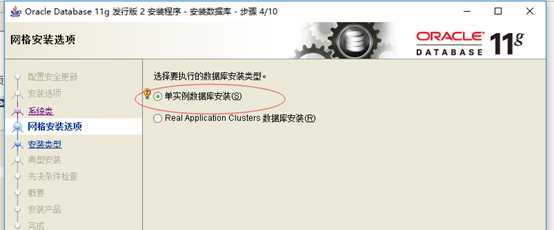
6: 安装类型。选择"高级安装",如下图所示,单击下一步。
7:产品语言。直接默认即可(简体中文、英语),如下图所示,单击下一步。
8:选择企业版
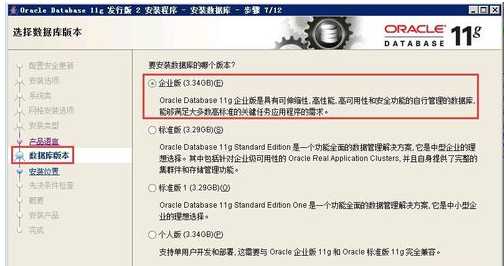
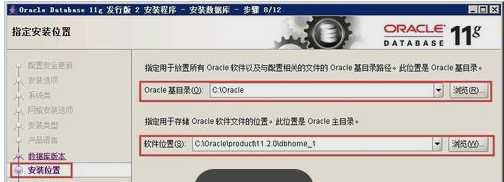
9: 安装位置。填入安装路径(只需要填"Oracle基目录"即可,"软件位置"会自动生成),如下图所示,单击下一步。(软件目录在基目录之下)
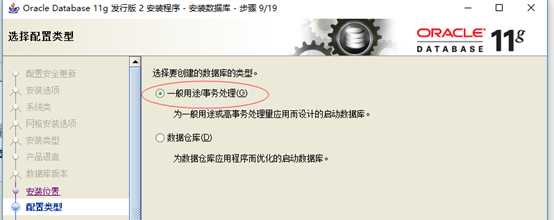
10:配置类型。选择"一般用途/事务处理",如下图所示,单击下一步
11:数据库标识符。填入全局数据库名和SID,如下图所示,单击下一步。
12:配置选项。切换到"字符集"选项卡,选择"使用Unicode(AL32UTF8)",如下图所示,单击下一步。
13: 管理选项。直接单击下一步,如下图所示。
14: 数据库存储。直接单击下一步,如下图所示。
15: 备份和恢复。如果需要对数据进行备份,就启用自动备份
16: 方案口令。为了便于测试,这里使用了相同的密码,实际部署时可根据实际情况自行决定。(我的为:123456)
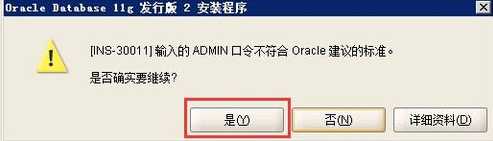
17: 概要。完成先决条件检查后,单击完成就可以正式开始安装了,如下图所示,单击下一步。
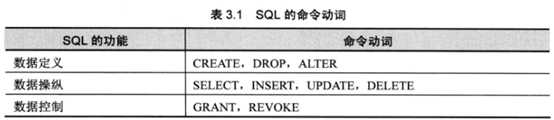
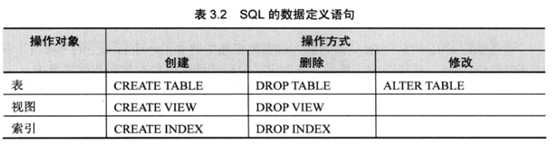

修改列名:




表和列的要求:

4. 创建表时的命名规则和注意事项
1)表名和字段名的命名规则:必须以字母开头,可以含符号A-Z,a-z,0-9,_,$,#
2)大小写不区分
3)不用SQL里的保留字, 一定要用时可用双引号把字符串括起来.
4)用和实体或属性相关的英文符号长度有一定的限制
1)建表时可以用中文的字段名, 但最好还是用英文的字段名
2)创建表时要把较小的不为空的字段放在前面, 可能为空的字段放在后面
3)建表时如果有唯一关键字或者唯一的约束条件,建表时自动建了索引
4)一个表的最多字段个数也是有限制的,254个.
2. 创建表时给字段加默认值 和约束条件
创建表时可以给字段加上默认值
例如 : 日期字段 DEFAULT SYSDATE
这样每次插入和修改时, 不用程序操作这个字段都能得到动作的时间
创建表时可以给字段加上约束条件
例如: 非空 NOT NULL
不允许重复 UNIQUE
关键字 PRIMARY KEY
按条件检查 CHECK (条件)
外键 REFERENCES 表名(字段名)
问题:字符串最大长度约为4000。如果要保存更多的内容怎么办?
回答:
解决的方法有两种。第一种是用大对象类型,即CLOB或者BLOB类型,但是编程比较麻烦;第二种是用一对多的父子表实现。
大对象是指大量的数据。如果用char或varchar2,列的最大长度大约在4000多;如果内容更多,其中一个方法就是将列设置为CLOB类型,但是只限制保存字符数据,如小说。如果是二进制数据,如图片、声音、office文档,则需要将列设置BLOB类型。CLOB或BLOB最大能够装4G的内容。如果是电影,则更通常的做法是在表中保存电影的名称、路径等信息,电影直接保存在磁盘上,而不是直接存储在数据库中,也不是用BFile类型。
示例:创建小说表
create table xiao_shuo(
xs_id number(10) primary key, --小说编号
xs_name varchar2(5), --小说名称
xs_contenct clob, --小说内容
xs_fen_mian blob --小说封面(图片)
);
第二种是利用父子表实现,例如:小说表(小说ID,小说标题),内容表(小说ID,行数,行内容),其中行内容为varchar(4000)。这表示每一行最多保存4000个字符。
回答:
两者主要的区别体现在存储上和查询效率上。
首先讲char——定长类型。
如将姓名列指定为char(8)。当保存"张三"时,数据库还会自动保存4个空格;保存"张三丰"时,数据库还会自动保存2个空格,这样每个人的姓名长度都为8,长度是固定的,所以叫做"定长"。明显,在保存信息时,定长会因为保存了很空格而多占用了磁盘空间。
数据库保存这些"多余"的空格有什么作用?
那就是查询时,在取到字段的长度以后,不再需要判断每一个姓名的实际长度,就可以取到数据。这样查询效率大大提高了。
下面再讲varchar2——变长类型。
如将姓名列指定为varchar2(8)。当保存"张三"和保存"张三丰"时,数据库都只保存数据的本身,不会自动添加空格。两个人姓名的长度分别为4和6,长度是变化的,所以叫做"变长"。这样没有多占用任何磁盘空间。
但是在查询时,每个人的姓名的长度都不同,必须先判断后取数据,所以查询效率比char类型要低。
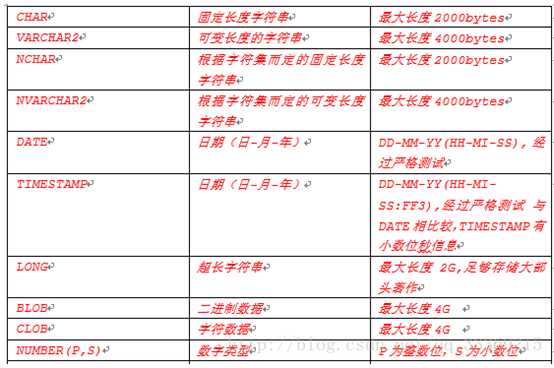
一个完整的建表语句:https://www.2cto.com/database/201304/202052.html


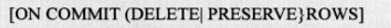
(会话级别|事务级别):
用法举例(在SCOTT模式下): https://blog.csdn.net/fjseryi/article/details/51119272
CREATE GLOBAL TEMPORARY TABLE session_temp_tab ON COMMIT PRESERVE ROWS AS SELECT * FROM emp WHERE 1=2;
ON COMMIT PRESERVE ROWS语句指定所创建的临时表是会话级临时表,当我们断开连接或手动执行DELETE或TRUNCATE之前,临时表中的数据一直存
在,并且只有当前会话可以看到,其他会话看不到。
CREATE GLOBAL TEMPORARY TABLE transaction_temp_tab ON COMMIT DELETE ROWS AS SELECT * FROM emp WHERE 1=2;
ON COMMIT DELETE ROWS语句指定所创建的临时表是事务级临时表,当COMMIT或ROLLBACK之前,这些数据一直存在,当事务提交之后,表中数据自动清除。
insert into session_temp_tab select * from emp ;
insert into transaction_temp_tab select * from emp ;
SQL> select count(*) from session_temp_tab ;
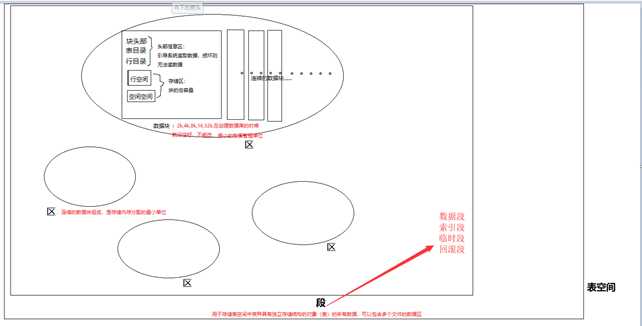
Oracle作为一款成熟的数据库软件产品,就提供了多种数据表存储结构。我们最常见的就是三种,分别为堆组织表(Heap Table)、索引组织表(Index Organization Table,简称为IOT)和聚簇表(Cluster Table)。
堆组织表的存储速度因为不用考虑排序, 所以存储速度会比较快. 但是要查找符合某个条件的记录, 就必须得读取全部的记录以便筛选. 而这个时候为了加快查询速度, 索引就出现了, 索引是针对少量特定字段的值拿出来进行排序存储, 并记录在表中的位置, 而因为索引是有序的, 所以就会很容易通过索引查询到具体的记录位置, 然后再根据记录位置直接从表中读取该记录. 索引表就这样产生了.
当然索引表中插入,更新资料的时候可能会因为需要排序而将数据重组, 这时候数据插入或更新速度会比堆组织表慢一些.如果堆组织表上有索引, 那么对堆组织表的插入也会因为要修改索引而变慢
默认就是堆组织表。

参考博客: https://www.cnblogs.com/wangfg/p/5286519.html
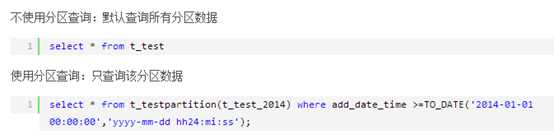
首先明确分区表和表分区的区别:表分区是一种思想,分区表示一种技术实现。当表的大小过G的时候可以考虑进行表分区,提高查询效率,均衡IO。oracle分区表是oracle数据库提供的一种表分区的实现形式。表进行分区后,逻辑上仍然是一张表,原来的查询SQL同样生效,同时可以采用使用分区查询来优化SQL查询效率,不至于每次都扫描整个表。
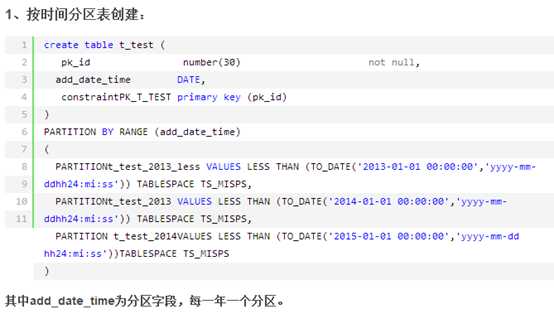
create tablespace morf01 datafile ‘d:\test\morf01.dbf‘ size 20m uniform size 128k
create table mytable(A number(3)) tablespace morf01;
CREATE TABLE t1(
id varchar2(32) primary key,
name VARCHAR2(32) ,
age VARCHAR2(32)
)
添加表注释:
COMMENT ON table t1 IS ‘个人信息‘;
comment on column t1.id is ‘id‘;
comment on column t1.name is ‘姓名‘;
comment on column t1.age is ‘年龄‘;
CONSTRAINT s_emp_id_pk PRIMARY KEY,
CONSTRAINT s_emp_last_name_nn NOT NULL,
CONSTRAINT s_emp_userid_nn NOT NULL
CONSTRAINT s_emp_userid_uk UNIQUE,
start_date DATE DEFAULT SYSDATE,
CONSTRAINT s_emp_dept_id_fk REFERENCES s_dept(id),
CONSTRAINT s_emp_commission_pct_ck CHECK
(commission_pct IN(10,12.5,15,17.5,20)));
DROP TABLE IF EXISTS `buycar`;
`carId` int(4) NOT NULL AUTO_INCREMENT COMMENT ‘购物车商品编号‘,
`userId` int(4) NOT NULL COMMENT ‘用户编号‘,
`shangId` int(4) NOT NULL COMMENT ‘商品编号‘,
`carCount` int(4) NOT NULL COMMENT ‘购物车数量‘,
KEY `fk_buycar_user` (`userId`),
KEY `fk_buycar_shangp` (`shangId`),
CONSTRAINT `fk_buycar_shangp` FOREIGN KEY (`shangId`) REFERENCES `shangp` (`shangId`),
CONSTRAINT `fk_buycar_user` FOREIGN KEY (`userId`) REFERENCES `user` (`userId`)
) ENGINE=InnoDB CHARSET=utf8 COMMENT=‘购物车表‘;






2.查询当前所有的表。ORACLE: select * from tab,MYSQL:show tables。
4:显示当前连接用户(库)。ORACLE:show user,MYSQL:connect。
insert into tb1 (id,name) values(1,‘a‘),(2,‘b‘);
INSERT INTO TEST (USER_ID,USER_NAME)
select ‘5‘,‘nahao5‘from dual union all
select ‘6‘,‘nahao6‘from dual union all
select ‘7‘,‘nahao7‘from dual union all
select ‘8‘,‘nahao8‘from dual union all
select ‘9‘,‘nahao9‘from dual union all
select ‘10‘,‘nahao10‘from dual
7.mysql不支持两个日期相减,但是可以直接使用datediff(date1,date2)函数求两个日期的差,oracle可以直接减
decode(条件,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)
mysql需要用case when判断 then结果 else另一结果 end来替换
限制返回记录条数 | SQL> select * from 表名 where rownum<5; | mysql> select * from 表名 limit 5; |
FROM (SELECT * FROM TABLE_NAME) A
select *
from (select rownum rn, a.* from emp a) t
where t.rn between 2 and 10;
标签:case base lap show 使用 商品 组织 win 数据
原文地址:https://www.cnblogs.com/domi22/p/8746669.html