标签:范围 格式 python模块 前缀 多行 9.png 操作 sch 自己
数据库相关概念:
1. 数据库服务器:运行数据库管理软件的计算机
2. 数据库管理软件:MySQL、Oracle、db2、slqserver
3. 库:文件夹,用来组织文件/表
4. 表:文件(类似于excel),用来存放多行内容/多条记录
5. 记录:事物一系列典型的特征
6. 数据:描述事物特征的符号
MySQL数据库就是一个套接字软件,用来管理其他机器上的数据文件
MySQL介绍:
MySQL是一个关系型数据库管理系统;就是一个基于socket编写的C/S架构胡软件
客户端软件
mysql自带:如mysql命令,mysqldump命令等
python模块:如pymysql
数据库管理软件分类:
分两大类:
关系型:如 sqllite,db2,oracle,access,sql server,mysql,注意:sql语句通用
非关系型:mongodb,redis,memcache
可以简单的理解为:
关系型数据库需要有表结构
非关系型数据库是key-value存储的,没有表结构
SQL语句基本操作:
MySQL服务端软件即mysqld帮我们管理好文件夹及文件,前提是作为使用者的我们,需要下载mysql的客户端,或者其他模块来连接到mysqld,然后使用mysql软件规定的语法格式去提交自己的命令,实现对文件夹或文件的管理。该语句即sql(Structured Query Language 结构化查询语言)
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统;分为3种类型:
1. DDL语句: 数据库定义语言:数据库、表、视图、索引、存储过程,例如create,drop,alter
2. DML语句: 数据库操纵语言:插入数据insert、删除数据delete、更新数据update、查询数据select
3. DCL语句: 数据库控制语言:例如控制用户胡访问权限grant、revoke
操作文件夹(库)
增: create database db1 charset utf8; (创建数据库db1,其字符编码为UTF-8;db1是库名)
查: show create database db1; (查看我刚创建的文件夹db1)
show databases; (查看所有的数据库)
改: alter database db1 charset gbk; (改数据库 db1 的字符编码 为 gbk; 不能改名字,只能改字符编码)
删: drop database db1; (删数据库db1)
操作文件(表)
先切换文件夹: use db1; (切换到数据库db1)
查看当前所在的文件夹(库): select database();
增: create table t1(id int,name char); (创建文件(表),文件名是t1,表中字段是id(id的数据类型是整型) 和 name(name是字符))
查: show create table t1; (查看创建的文件t1)
desc t1; (查看表t1;desc是describe的缩写)
show tables; (查看当前库下所有的表/文件)
改: alter table t1 modify name char(6); (修改表t1,把t1中name字段char的宽度改为6)
alter table t1 change name NAME char(7); (修改表t1,把t1中name字段改为NAME,并把char改为7)
删: drop table t1; (删除t1这个表)
操作文件内容(记录)
增:insert t1(id,name) values(1,"neo1"),(2,"neo2"),(3,"neo3"); (往t1这个文件中插入values;插入多条value用逗号隔开;values中的值按照t1后面的字段顺序添加)
insert t1 values(1,"neo1"),(2,"neo2"),(3,"neo3"); (t1后面不加字段名,默认按字段顺序添加values)
查:select id,name from t1; (查看当前库下t1这个表的id和name)
select id,name from db1.t1; (如果所查看的t1表不在当前库下,则在t1前加上db1这个库名前缀)
select id from t1; (只查询id)
select * from t1; (查询所有字段)
改:update db1.t1 set name="NEO"; (更改db1库下的t1表,把name字段全部设置成NEO)
update t1 set name="Neo" where id=2; (更新当前库下的t1表,把id为2那一行name设置成Neo)
删:delete from t1; (把t1表下的所有记录都删除)
delete from t1 where id=2; (把t1表下id为2的记录删除)
库操作:
系统数据库:
information_schema:虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
performance_schema:MySQL 5.5开始新增一个数据库:主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
mysql:授权库,主要存储系统用户胡权限信息
test:MySQL数据库系统自动创建胡测试数据库
创建数据库:
1. 语法: create database 数据库名 charset utf8;
2. 数据库命名规则:
可以由字母、数字、下划线、@、#、¥
区分大小写
唯一性
不能使用关键字如create、select等
不能单独使用数字
最长128位
数据库相关操作:
查看数据库:
show databases;
show create database db1;
select database();
选择数据库:
use 数据库名;
删除数据库:
drop database 数据库名;
修改数据库:
alter database db1 charset utf8;
存储引擎介绍:
1. 数据库中的表有不同胡类型,表的类型不同,会对应mysql不同的存取机制,表类型又称存储引擎;存储引擎就是表的类型
2. 查看MySQL支持的存储引擎: show engines; # 默认的存储引擎是innodb
3. 指定表类型/存储引擎:
create table t1(id int)engine=innodb;
create table t1(id int)engine=memory;
create table t1(id int)engine=blackhole;
表操作:
1. 表介绍:表相当于文件,表中的一条记录就相当于文件胡一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段
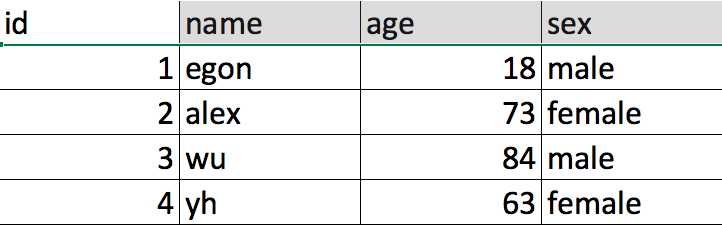
id,name,age,sex称为字段,其余的,一行内容称为一条记录
2. 创建表:
语法:
create table 表名(
字段名1 类型[(宽带)约束条件],
字段名2 类型[(宽带)约束条件],
字段名3 类型[(宽带)约束条件]
) ;
附:表中最后一个字段后面不要再加逗号
注意:
1. 同一张表种,字段名不能相同
2. 宽带和约束条件可选
3. 字段名肯类型椒必须的
3. 查看表结构:
1. describe 表名; # 查看表结构,可简写为 desc 表名;
2. show create table 表名; # 查看表详细结构,可加 \G
4. 修改表结构:
1. 修改表名: alter table 表名 rename 新表名;
2. 增加字段: alter table 表名 add 字段名 数据类型 [完整性约束条件], add 字段名 数据类型 [完整性约束条件];
alter table 表名 add 字段名 数据类型 [完整性约束条件] first; # 把这个字段放到第几个位置
alter table 表名 add 字段名 数据类型 [完整性约束条件] after 字段名; # 把新添加的字段放到某个字段后面
3. 删除字段: alter table 表名 drop 字段名;
4. 修改字段: alter table 表名 modify 字段名 数据类型 [完整性约束条件]; # 修改字段的数据类型相关信息
alter table 表名 change 旧字段名 新字段名 新/旧数据类型 [完整性约束条件]; # 修改字段名和数据类型
5. 删除表: drop table 表名;
6. 复制表:
1. 复制表结构和记录: create table 表名1 select name,age from db1.表名2; # 数据库db1中的表名2中的name和age复制到表名1中(把表2胡查询结果当作复制的内容传给表1)
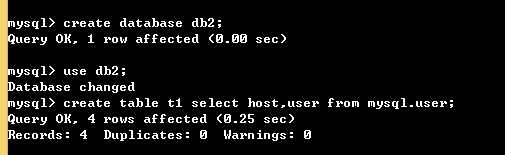
2. 只复制表结构,不复制纪录:create table 表名1 select name,age from db1.表名2 where 1>5; # where 1>5是一个假条件(没有纪录能满足这个条件),但表名2的表结构却是存在的,通过这种方式去只复制表结构
3. 只复制全部的表结构: create table 表名1 like db1.表名2; # 复制db1数据库中表名2的所有表结构,不复制纪录

数据类型:
存储引擎决定了表的类型,而表内存放胡数据也要有不同的类型,每种数据类型都有自己的宽带,但宽度是可选胡
详细参考:
http://www.runoob.com/mysql/mysql-data-types.html
https://dev.mysql.com/doc/refman/5.7/en/data-type-overview.html
MySQL常用数据类型:
1. 数字
整形:tinyint, int, bigint
小数:
float:在位数比较短的情况下不精确
double:在位数比较长的情况下不精确
decimal:精确,内部原理是字符串形式存储
2. 字符串:
char(10):简单粗暴,浪费空间,存取速度快;root存成root000000
varchar:精确,节省空间,存取速度慢
3. 时间类型: 最常用:datetime
4. 枚举类型于集合类型
数值类型:
1. 整数类型:tinyint, smallint, mediumint,bigint; 作用:存储年龄、等级、id、各种号码等
tinyint[(m)] [unsigned] [zerofill]
小整数,数据类型用于保存一些范围的整数数值范围:
有符号: -128~127 ; 无符号: 0~255 ; ps: MySQL中无布尔值,使用tinyint(1)构造
inyint[(m)] [unsigned] [zerofill]
整数,数据类型用于保存一些范围的整数数值范围:
有符号:-2147483648 ~ 2147483647;无符号: 0 ~ 4294967295
注意:为整数类型指定宽度时,仅仅只是指定查询结果的显示宽度,与存储范围无关;其实我们完全没必要为整数类型指定显示宽带,使用默认的就可以了;默认的显示宽带,都是在最大值的基础上加1
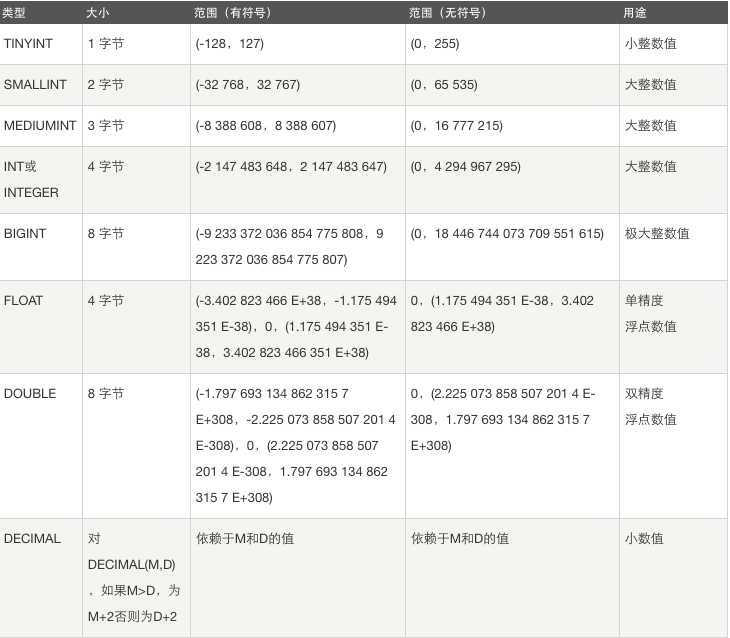
int的存储宽度是4个bytes,即32个bit,即2**32; 无符号最大值为:4294967296-1;有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完整,所以int类型默认的显示宽带为11是非常合理的;所以,整形类型,没有必要指定显示宽度,使用默认的就行
浮点型:定点数类型:decimal(等同于dec); 浮点类型:float,double;作用:存储薪资、身高、体重、体质参数等
float[(m,d)] [unsigned] [zerofill]:
定义:单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数;m最大值为255,d最大值为30;随着小数的增多,精度变得不准确
double[(m,d)] [unsigned] [zerofill]:
定义:双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30;随着小数的增多,精度比float要高,但也会变得不准确
decimal[(m[,d])] [unsigned] [zerofill]:
定义: 准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30;随着小数的增多,精度始终准确;对于精确数值计算时需要用此类型;decaimal能够存储精确值的原因在于其内部按照字符串存储。
补充知识点:加入一条sql语句写错了,可以利用 \c 来终止这条语句的运行; 加入少了一个引号,就先把引号补全再用\c, 如: ‘\c
日期类型:year, date, time, datetime, timestamp;作用:存储用户注册时间、文章发布时间、入职时间、出生时间、过期时间等
形式与范围:
year:YYYY(1901/2155)
date:YYYY-MM-DD (1000-01-01/9999-12-31)
time:HH:MM:SS(‘-838:59:59‘/‘838:59:59‘)
datetime: YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 )
timestamp:YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
先看下面一段sql语句:
create table stu1( id int, name char(6), born_year year, birth_date date, class_time time, regis_time datetime ); # char(6)是最多能存储6个字符,所以名字最多6个字符 insert stu1 values(1,"neo",now(),now(),now(),now()); # now()是mysql是自带的一个函数,调用当前时间
执行结果如下:
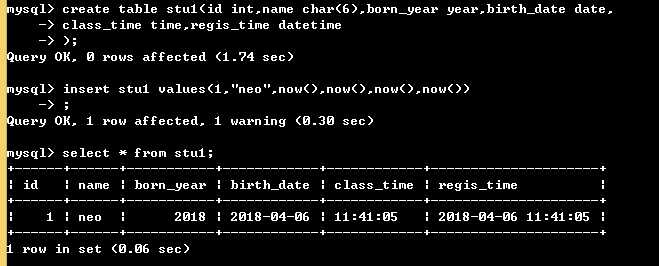
也可以自己添加日期:
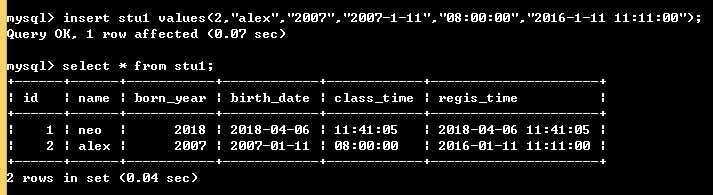
insert stu1 values(2,"alex","2007","2007-1-11","08:00:00","2016-1-11 11:11:00");
如下图:
字符类型:
char和varchar括号内的参数指的都是字符的长度
char类型:定长,简单粗暴,浪费空间,存取速度快
字符长度范围:0-255 (一个中文是一个字符,是utf8编码的3个字节)
存储:存储char类型的值时,会往右填充空格来满足长度,例如:指定长度为10,存<10个字符则用空格填充直到凑够10个字符存储
检索:在检索或者说查询时,查出的结构会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL 模式(SET sql_mode = "PAD_CHAR_TO_FULL_LENGTH";)
varchar类型:变长,精准,节省空间,存取速度慢
字符长度范围:0-65535(mysql行最大限制为65535字节)
存储:varchar类型存储数据的真实内容,不会用空格填充;
varchar类型会在真实数据前加1~2个bytes作为前缀,该前缀用来表示真实数据的bytes字节数(1~2bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用)
如果真实的数据<255则需要一个bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255)
如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535)
检索: 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
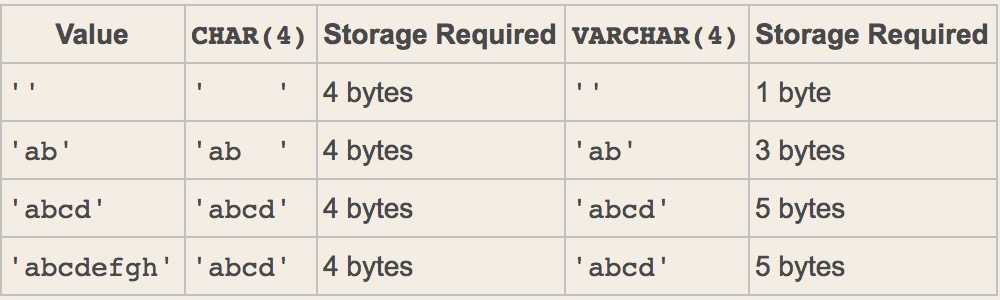
# length:查看字节数; char_length:查看字符数
1. char填充空格来满足固定长度,但是在查询时会自动删除尾部的空格来匹配查询值
2. 虽然char和varchar的存储方式不太相同,但是对于两个字符串的比较,都是只比较其值,忽略char存在的右填充,即使将sql_mode设置成PAD_CHAR_TO_FULL_LENGTH也一样;但这不适用于like
所以,虽然varchar使用起来比较灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快
枚举类型和集合类型:
字段的值只能在给定范围内选择,如单选框、多选框
enum 单选 只能在给定的范围内选一个值,如性别 sex male/female
set 多选 在给定的范围内可以选择一个或多个值(爱好1,爱好2.。。)
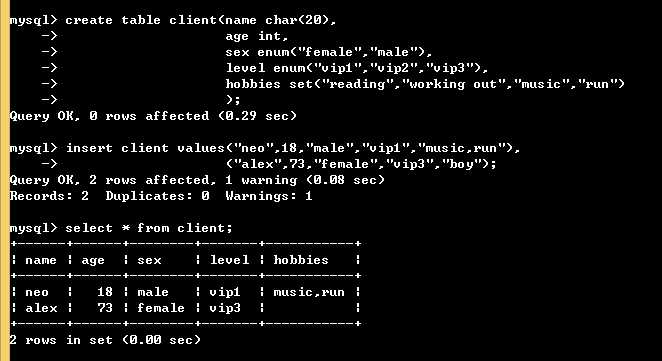
create table client(name char(20), age int, sex enum("female","male"), level enum("vip1","vip2","vip3"), hobbies set("reading","working out","music","run") ); insert client values("neo",18,"male","vip1","music,run"), ("alex",73,"female","vip3","boy");
运行结果:
约束条件:
not null和default:
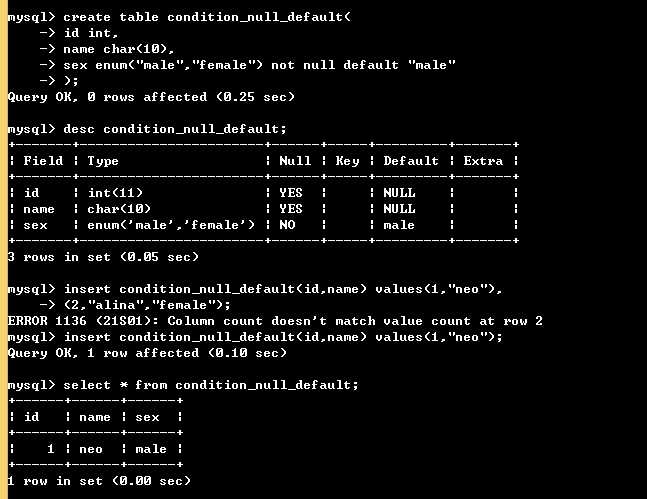
create table condition_null_default( id int, name char(10), sex enum("male","female") not null default "male" ); insert condition_null_default(id,name) values(1,"neo"), (2,"alina","female");
如下:
约束条件 unique key:
单列唯一:
方式一:
create table department1( id int unique, name char(10) unique ); insert department1 values(1,"IT"),(2,"Sales);
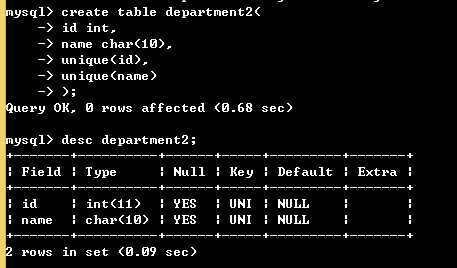
方式二:
create table department2( id int, name char(10), unique(id), unique(name) );
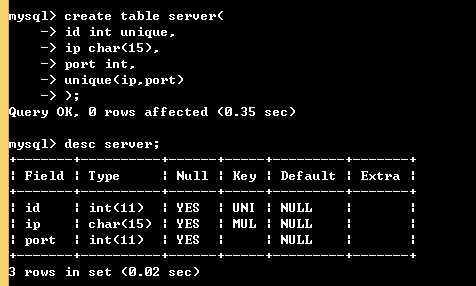
联合唯一:
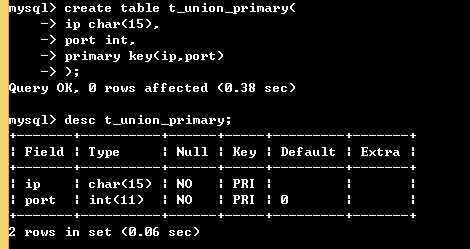
create table server( id int unique, ip char(15), port int, unique(ip,port) ); # unique(ip,port)的含义是: ip和port拼到一起后必须是唯一的
primary key:
约束:not null unique(不为空且唯一)
存储引擎(默认innodb):对于innodb存储引擎来说,一张表内必须有一个主键(通常将id字段设为主键)
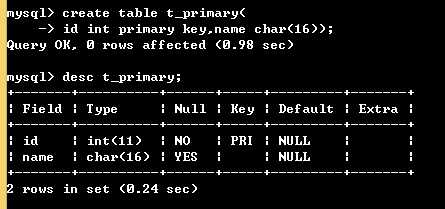
单列主键:
create table t_primary( id int primary key,name char(16));
对于innodb,如果你不指定主键,innodb会找一个不为空且唯一的字段作为主键;如果没找到,就用它自己隐藏的字段作为主键;如下
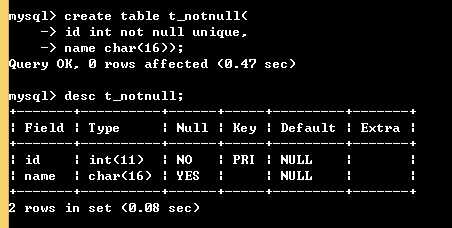
复合主键:
create table t_union_primary( ip char(15), port int, primary key(ip,port) ); # ip和port联合组成主键
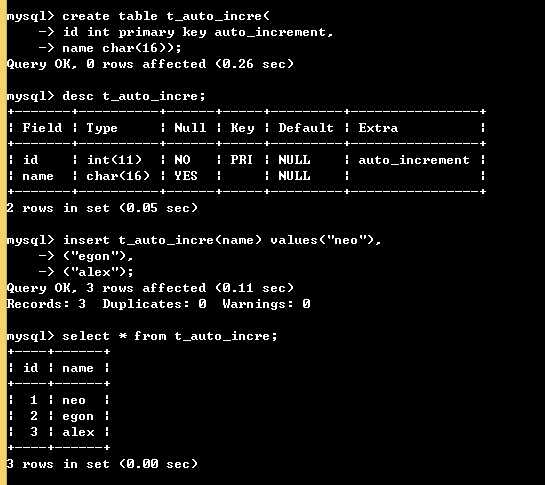
auto_increment: (自增长)
create table t_auto_incre( id int primary key auto_increment, name char(16)); # auto_increment的字段需要指定key # 默认是从1开始,每次增加1 insert t_auto_incre(name) values("neo"), ("egon"), ("alex");
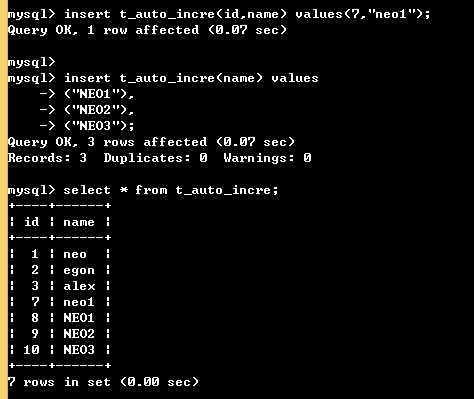
如果中间自己不按顺序插入了id,后面的id auto_increment时以你新插入的id作为起点
insert t_auto_incre(id,name) values(7,"neo1"); insert t_auto_incre(name) values ("NEO1"), ("NEO2"), ("NEO3");
# 查看mysql关于auto_increment的默认设置 show variables like "auto_inc%"; # show variables 是查看变量,like是模糊匹配,%代表任意长度的任意字符
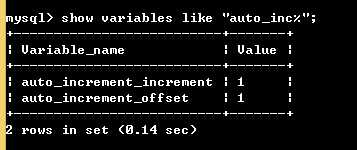
# 步长: auto_increment_increment默认为1
# 起始偏移量(位置): auto_increment_offset默认为1
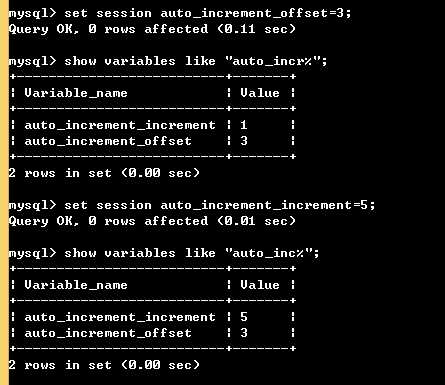
#设置步长: set session auto_increment_increment=5; set global auto_increment_increment=5; #session是会话级别的修改,就是只在本次运行时有效,退出再登录后会恢复到原先的设置; #global是全局级别的修改,长期有效,但需要推出后重新登录mysql才会生效 #设置起始偏移量: set session auto_increment_offset=3; set global auto_increment_offset=3; #用法同上;需要注意的一点:起始偏移量必须要小于等于步长
清空表:
delete from 表名 where xxx; 不要用delete去清空表,delete用在跟where语句连用的情况下;delete from 表名 无法删除自增长(auto_increment)的纪录
truncate 表名; 清空表应该用 truncate(能把自增长的纪录也删除掉)
foreign key(外键):建立表之间的关系
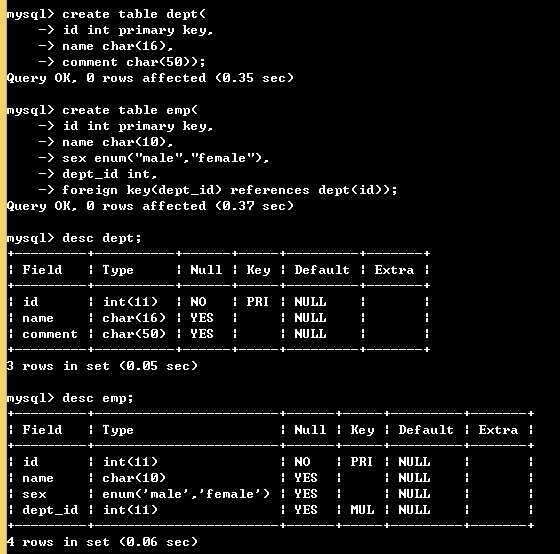
1. 建表
# 先建被关联的表,并且保证保证被关联的字段唯一 create table dept( id int primary key, name char(16), comment char(50)); # 再建关联表 create table emp( id int primary key, name char(10), sex enum("male","female"), dept_id int, foreign key(dept_id) references dept(id)); # dept_id是外键,关联到dept表的id字段
2. 插入数据
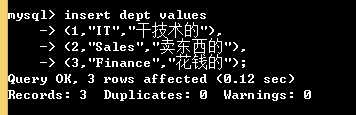
# 先往被关联表中插入纪录 insert dept values (1,"IT","干技术的"), (2,"Sales","卖东西的"), (3,"Finance","花钱的"); # 再往关联表中插入数据 insert emp values (1,"neo","male",1), (2,"alex","female",2), (3,"egon","male",3); # 因为只有被关联表的关联字段建起来后关联表才能去关联;后有纪录的那张表加foreign key
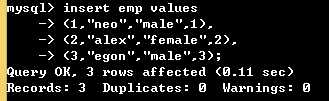
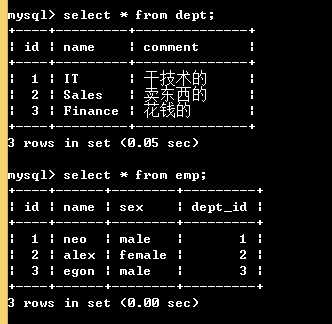
上述建表方式由于没有指定 on delete cascade on update cascade,所以不能直接操作被关联表
如果想删除、更新同步(即 删除、更细被关联表的关联字段,关联表也自动跟着删除、更新),关联表建表时要加上 on delete cascase on update cascade 例如:foreign key(dept_id) references dept(id) on delete cascade on update cascade
# 建被关联的表 create table dept( id int primary key, name char(16), comment char(50)); # 建关联表 create table emp( id int primary key, name char(10), sex enum("male","female"), dept_id int, foreign key(dept_id) references dept(id) on delete cascade on update cascade ); # 加上 on delete cascade on update cascade
delete from dept where id=1; update dept set id=202 where id=2;
tips:实际项目中尽量不要把两张表建立硬性限制(foreign key),最好能从逻辑上去实现两张表的关系,即从应用程序代码的层面上去实现两张表的关系,不要再数据库利用foreign key去建立硬性关系(这样不利于扩展)
表与表之间的关系: 多对一、多对多、一对一
多对一:例如上面的例子,员工表emp中多个人纪录可以对应部门表dept中的一个部门纪录,但多个部门纪录却不能对应一个人(即 多个人可以在一个部门下,但一个人却不能在多个部门),这就是多对一
多对多:A表中的多条纪录可以对应B表中的一条纪录,同时B表中的多条纪录也可以对应A表中的一条纪录,这就是多对多;多对多需要专门另外建一张表来存多对多之间的关系;例如下面的书与作者的例子:
create table author( id int primary key auto_increment, name char(16)); create table book( id int primary key auto_increment, name char(50)); # 专门建一张表来保存多对多那两张表之间的关系 create table author2book( id int not null unique auto_increment, author_id int not null, foreign key(author_id) references author(id) on delete cascade on update cascade, book_id int not null, foreign key(book_id) references book(id) on delete cascade on update cascade, primary key(author_id,book_id)); # author_id去多对一author表中的id字段,book_id去多对一book表中的id字段 insert author(name) values("neo"),("egon"),("alex"),("wusir"); insert book(name) values("python自动化"),("linux运维"),("python全栈"); # 插入多对多之间的关系 insert author2book(author_id,book_id) values (1,1),(1,2),(1,3), (2,1),(2,2), (3,2), (4,2),(4,3);
一对一:两张表中的纪录最多只能互相对应中的一条纪录,即一一对应,例如博客园中一个昵称只能对应一个博客链接,一个博客链接也只能对应一个昵称
以培训机构的custome和student为例,客户(customer)表中的一条纪录最多只能对应student表中的一个纪录,student表中的一条纪录也一定对应customer表中的一条纪录:
# 先有潜在客户customer才能有学生(student),后有纪录的那钟表加foreign key create table customer( id int primary key auto_increment, name char(10) not null, phone int not null); create table student( id int primary key auto_increment, class_name char(16) not null, customer_id int unique, foreign key(customer_id) references customer(id) on delete cascade on update cascade); # 要想称为一对一的表,student的字段 customer_id必须要指定为 unique; 外键一定要保证 unique !!! insert into customer(name,phone) values (‘李飞机‘,13811341220), (‘王大炮‘,15213146809), (‘守榴弹‘,1867141331), (‘吴坦克‘,1851143312), (‘赢火箭‘,1861243314), (‘战地雷‘,18811431230); insert student(class_name,customer_id) values ("python周末5期",3), ("linux运维6期",5);
MySQL数据库:SQL语句基础、库操作、表操作、数据类型、约束条件、表之间的关系
标签:范围 格式 python模块 前缀 多行 9.png 操作 sch 自己
原文地址:https://www.cnblogs.com/neozheng/p/8719471.html
{kind=link}