标签:lin body 取反 order show 字节 浮点数 lsp jvm
以下是本文的目录大纲:
一.什么是装箱?什么是拆箱?
简单一点说,装箱就是 自动将基本数据类型转换为包装器类型;拆箱就是 自动将包装器类型转换为基本数据类型。
二.装箱和拆箱是如何实现的
1:反编译class文件:javap -c 类名
2:装箱过程是通过调用包装器(Integer)的valueOf方法实现的,而拆箱过程是通过调用包装器的 xxxValue方法实现的。(xxx代表对应的基本数据类型)。
3:注意,Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的。
Double、Float的valueOf方法的实现是类似的。
三.面试中相关的问题
1:Integer a=1时发生装箱过程中使用valueOf方法,Integer.valueOf()中有个静态内部类IntegerCache,里面有个常量cache[],也就是Integer常量池(其实就是缓存池技术,利用空间换时间的策略,也叫对象池),在常量池(对象池)中Integer已经默认创建了数值【-128-127】的Integer缓存数据。所以使用Integer a=1时,JVM会直接在该在对象池找到该值的引用。也就是说这种方式声明一个Integer对象时,JVM首先会在Integer对象的缓存池中查找有木有值为1的对象,如果有直接返回该对象的引用;如果没有,则使用New Integer(在jvm的堆中new一个)创建一个对象,并返回该对象的引用地址。
注意:最大值 127 可以通过 JVM 的启动参数 -XX:AutoBoxCacheMax=size 修改
2:int与Integer比较时,会自动装箱

3:谈谈Integer i = new Integer(xxx)和Integer i =xxx;这两种方式的区别。
当然,这个题目属于比较宽泛类型的。但是要点一定要答上,我总结一下主要有以下这两点区别:
1)第一种方式不会触发自动装箱的过程;而第二种方式会触发;
2)在执行效率和资源占用上的区别。第二种方式的执行效率和资源占用在一般性情况下要优于第一种情况,当值不在(-128-127)之间时(注意这并不是绝对的)。
在前面的文章中提到,Java为每种基本数据类型都提供了对应的包装器类型,至于为什么会为每种基本数据类型提供包装器类型在此不进行阐述,有兴趣的朋友可以查阅相关资料。在Java SE5之前,如果要生成一个数值为10的Integer对象,必须这样进行:
|
1
|
Integer i = new Integer(10); |
而在从Java SE5开始就提供了自动装箱的特性,如果要生成一个数值为10的Integer对象,只需要这样就可以了:
|
1
|
Integer i = 10; |
这个过程中会自动根据数值创建对应的 Integer对象,这就是装箱。
那什么是拆箱呢?顾名思义,跟装箱对应,就是自动将包装器类型转换为基本数据类型:
|
1
2
|
Integer i = 10; //装箱int n = i; //拆箱 |
简单一点说,装箱就是 自动将基本数据类型转换为包装器类型;拆箱就是 自动将包装器类型转换为基本数据类型。
下表是基本数据类型对应的包装器类型:
| int(4字节) | Integer |
| byte(1字节) | Byte |
| short(2字节) | Short |
| long(8字节) | Long |
| float(4字节) | Float |
| double(8字节) | Double |
| char(2字节) | Character |
| boolean(未定) | Boolean |
上一小节了解装箱的基本概念之后,这一小节来了解一下装箱和拆箱是如何实现的。
我们就以Interger类为例,下面看一段代码:
|
1
2
3
4
5
6
7
|
public class Main { public static void main(String[] args) { Integer i = 10; int n = i; }} |
反编译class文件之后得到如下内容:javap -c 类名
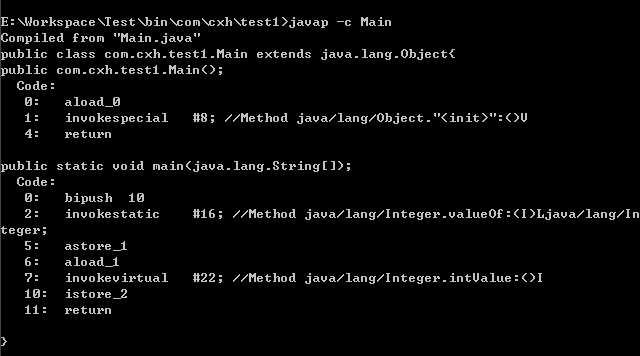
从反编译得到的字节码内容可以看出,在装箱的时候自动调用的是Integer的valueOf(int)方法。而在拆箱的时候自动调用的是Integer的intValue方法。
其他的也类似,比如Double、Character,不相信的朋友可以自己手动尝试一下。
因此可以用一句话总结装箱和拆箱的实现过程:
装箱过程是通过调用包装器的valueOf方法实现的,而拆箱过程是通过调用包装器的 xxxValue方法实现的。(xxx代表对应的基本数据类型)。
虽然大多数人对装箱和拆箱的概念都清楚,但是在面试和笔试中遇到了与装箱和拆箱的问题却不一定会答得上来。下面列举一些常见的与装箱/拆箱有关的面试题。
1;先看一个问题,对于下面定义的四个变量进行==比较:
|
1
2
3
4
5
6
|
Integer a=1;
Integer b=1;
Integer c=200;
Integer d=200;
System.out.println(a==b);//true
System.out.println(c==d);//false
|
我们都知道==在JAVA里面是比较对象引用的,如果两个对象引用指向堆中的同一块内存就返回true,否则返回false。根据自动装箱规则我们知道Integer a = 1 <==> Integer a = Integer.valueOf(1);,但是在valueOf方法上,查看源码:
|
1
2
3
4
5
6
7
|
public static Integer valueOf(int i) {
final int offset = 128;
if (i >= -128 && i <= 127) { // must cache
return IntegerCache.cache[i + offset];
}
return new Integer(i);
}
|
Integer.valueOf()中有个内部类IntegerCache(类似于一个常量数组,也叫对象池),它维护了一个Integer数组cache,长度为(128+127+1)=256。Integer类中还有一个Static Block(静态块)
|
1
2
3
4
|
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Integer(i - 128);
}
|
从这个静态块可以看出,Integer已经默认创建了数值【-128-127】的Integer缓存数据。所以使用Integer a=1时,JVM会直接在该在对象池找到该值的引用。也就是说这种方式声明一个Integer对象时,JVM首先会在Integer对象的缓存池中查找有木有值为1的对象,如果有直接返回该对象的引用;如果没有,则使用New Integer创建一个对象,并返回该对象的引用地址。因为Java中==比较的是两个对象是否是同一个引用(即比较内存地址),a和b都是引用的同一个对象,所以a==b结果为true;c和d已经超出了缓存的范围,所以重新生成了Integer对象,所以c==d结果为false。
2.下面这段代码的输出结果是什么?
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public class Main { public static void main(String[] args) { Double i1 = 100.0; Double i2 = 100.0; Double i3 = 200.0; Double i4 = 200.0; System.out.println(i1==i2); System.out.println(i3==i4); }} |
也许有的朋友会认为跟上面一道题目的输出结果相同,但是事实上却不是。实际输出结果为:
 false false
false false至于具体为什么,读者可以去查看Double类的valueOf的实现。
在这里只解释一下为什么Double类的valueOf方法会采用与Integer类的valueOf方法不同的实现。很简单:在某个范围内的整型数值的个数是有限的,而浮点数却不是。
下面我们进行一个归类:
Integer派别:Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的。
Double派别:Double、Float的valueOf方法的实现是类似的。每次都返回不同的对象。
下面对Integer派别进行一个总结,如下图:
4.谈谈Integer i = new Integer(xxx)和Integer i =xxx;这两种方式的区别。
当然,这个题目属于比较宽泛类型的。但是要点一定要答上,我总结一下主要有以下这两点区别:
1)第一种方式不会触发自动装箱的过程;而第二种方式会触发;
2)在执行效率和资源占用上的区别。第二种方式的执行效率和资源占用在一般性情况下要优于第一种情况(注意这并不是绝对的)。
5.下面程序的输出结果是什么?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public class Main { public static void main(String[] args) { Integer a = 1; Integer b = 2; Integer c = 3; Integer d = 3; Integer e = 321; Integer f = 321; Long g = 3L; Long h = 2L; System.out.println(c==d); System.out.println(e==f); System.out.println(c==(a+b)); System.out.println(c.equals(a+b)); System.out.println(g==(a+b)); System.out.println(g.equals(a+b)); System.out.println(g.equals(a+h)); }} |
先别看输出结果,读者自己想一下这段代码的输出结果是什么。这里面需要注意的是:当 "=="运算符的两个操作数都是 包装器类型的引用,则是比较指向的是否是同一个对象,而如果其中有一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。另外,对于包装器类型,equals方法并不会进行类型转换。明白了这2点之后,上面的输出结果便一目了然:
true
false
true
true
true
false
true
第一个和第二个输出结果没有什么疑问。第三句由于 a+b包含了算术运算,因此会触发自动拆箱过程(会调用intValue方法),因此它们比较的是数值是否相等。而对于c.equals(a+b)会先触发自动拆箱过程,再触发自动装箱过程,也就是说a+b,会先各自调用intValue方法,得到了加法运算后的数值之后,便调用Integer.valueOf方法,再进行equals比较。同理对于后面的也是这样,不过要注意倒数第二个和最后一个输出的结果(如果数值是int类型的,装箱过程调用的是Integer.valueOf;如果是long类型的,装箱调用的Long.valueOf方法)。
如果对上面的具体执行过程有疑问,可以尝试获取反编译的字节码内容进行查看。
标签:lin body 取反 order show 字节 浮点数 lsp jvm
原文地址:https://www.cnblogs.com/Pjson/p/8777940.html
