标签:针对 统计 数据集 des 技术分享 指定 概述 示例 col
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
GROUP BY 子句放在 WHERE 子句之后,ORDER BY 子句之前。
2、聚合函数
group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
表结构:
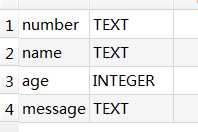
现有数据:
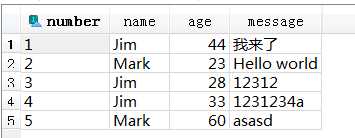
(1)
SELECT * FROM test1 GROUP BY name
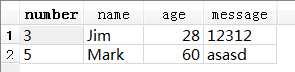
以name为关键字,每个name随机搜到了一个
(2)
SELECT name, avg(age) FROM test1 GROUP BY name
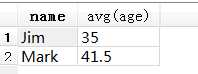
avg : 显示name和age两列,age列取所有满足项的平均值
(3)
SELECT *, avg(age) FROM test1 GROUP BY name
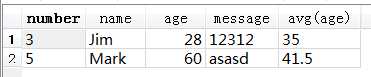
显示了所有列,外加 avg(age) 一列
(4)
SELECT name, sum(age) FROM test1 GROUP BY name
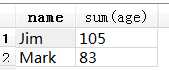
sum : 对age一列求和
(5)
SELECT name, count(age) FROM test1 GROUP BY name
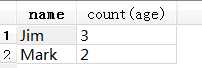
count : 满足添加的数量
(6)
SELECT name, count(age) FROM test1 WHERE age>30 AND age<60 GROUP BY name ORDER BY desc
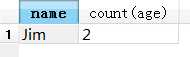
注意:GROUP BY 子句介于 WHERE 子句和 ORDER BY 子句 中间。
《完》
标签:针对 统计 数据集 des 技术分享 指定 概述 示例 col
原文地址:https://www.cnblogs.com/pjl1119/p/8806600.html