标签:list article hashlib 类的属性 区分 www. width size now()
一、继承
继承是一种新建类的方式,在python中支持一个子类继承多个父类
新建类称为子类或派生类
父类可以称之为基类或者超类
子类会遗传父类的属性
2. 为什么继承
减少代码冗余
3. 定义方式:
class Parent: pass class SubClass(Parent): pass print(SubClass.__bases__) #查看类的父类
4. 继承,调用父类方法以及self
class Foo: def f1(self): print(‘Foo.f1‘) def f2(self): #self=obj print(‘Foo.f2‘) self.f1() #obj.f1() class Bar(Foo): def f1(self): print(‘Bar.f1‘) obj=Bar() # print(obj.__dict__) obj.f2() #输出为: FOO.f1 # Bar.f1
二、 派生
子类定义自己新的属性,如果与父类同名,以子类自己的为准
在子类派生出的新方法中重用父类功能(最好不要两种方法混着用):
class OldboyPeople: school = ‘oldboy‘ def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex def tell_info(self): print(""" ===========个人信息========== 姓名:%s 年龄:%s 性别:%s """ %(self.name,self.age,self.sex)) class OldboyTeacher(OldboyPeople): def __init__(self, name, age, sex, level, salary): # self.name = name # self.age = age # self.sex = sex OldboyPeople.__init__(self,name, age, sex) #此处直接调用父类方法 self.level = level self.salary = salary def tell_info(self): OldboyPeople.tell_info(self) print(""" 等级:%s 薪资:%s """ %(self.level,self.salary))
2. super()调用(严格依赖于继承)
super()的返回值是一个特殊的对象,该对象专门用来调用父类中的属性
class OldboyTeacher(OldboyPeople): # tea1,‘egon‘, 18, ‘male‘, 9, 3.1 def __init__(self, name, age, sex, level, salary): OldboyPeople.__init__(self,name, age, sex) #调用父类方法 # super(OldboyTeacher,self).__init__(name,age,sex) 在python2中调用时用这种写法 self.level = level self.salary = salary def tell_info(self): # OldboyPeople.tell_info(self) super().tell_info() print(""" 等级:%s 薪资:%s """ %(self.level,self.salary))
super()严格依赖继承
三、新式类与经典类
1、新式类:
继承object的类,以及该类的子类,都是新式类
在python3中,如果一个类没有指定继承的父类,默认就继承object
所以说python3中所有的类都是新式类
2、经典类 (只有在python2才区分经典类与新式类):
没有继承object的类,以及该类的子类,都是经典类
区别: 在菱形继承的背景下,经典类和新式类才有区别。非菱形继承时,是一样的。但是当菱形继承时,新式类会采用广度优先,经典类深度优先
深度优先:按照从左往右的顺序,每一条分支走到底,再转入下一条分支
广度优先:按照从左往右的顺序,忽略菱形最顶上的父类,将除该父类之外的所有类进行深度优先遍历,最后再查找该父类
多继承的类便利顺序:一个对象继承多个类,按照定义顺序,从左到右,深度便利
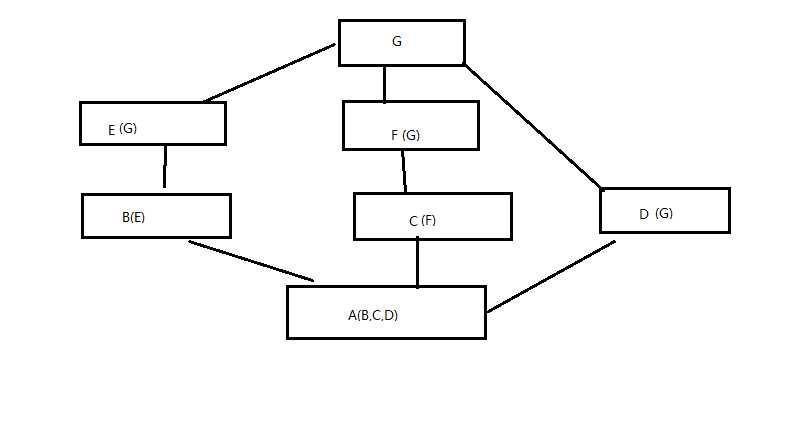
经典类遍历结果:ABEGCFD
新式类便利结果:ABECFDG
#coding:utf-8 #在菱形继承的背景下,查找属性 #1、经典类:深度优先 #2、新式类:广度优先 class A: # def test(self): # print(‘from A‘) pass class B(A): # def test(self): # print(‘from B‘) pass class C(A): # def test(self): # print(‘from C‘) pass class D(B): # def test(self): # print(‘from D‘) pass class E(C): # def test(self): # print(‘from E‘) pass class F(D,E): # def test(self): # print(‘from F‘) pass # f1=F() # f1.test() print(F.mro()) # F->D->B->E->C-A->object
super()严格依赖继承
#super()会严格按照mro列表从当前查找到的位置继续往后查找 class A: def test(self): print(‘A.test‘) super().f1() class B: def f1(self): print(‘from B‘) class C(A,B): pass c=C() print(C.mro()) #C->A->B->object c.test()
作 业 :
4月12日作业 1、类的属性和对象的属性有什么区别? 类的属性是所有对象共享的,对象的属性,是对象单独使用的 2、面向过程编程与面向对象编程的区别与应用场景? 1、面向过程是流水线式编程,先做什么在做什么 2、面向对象是上帝视角的,面向一个个对象,让对象之间交互解决问题 3、类和对象在内存中是如何保存的。 都是一串数据 类在定义时,执行代码,开辟内存空间,存放各种属性名和方法名,但不执行__init__方法 对象在执行是,调用类的__init__方法,开辟内存空间,存放该对象自己独有的属性名 4、什么是绑定到对象的方法,、如何定义,如何调用,给谁用?有什么特性 类的方法 类的方法是绑定给对象用的,一个类的每一个对象,对应相同的类方法,在调用时相互独立,互不相干 5、如下示例, 请用面向对象的形式优化以下代码 在没有学习类这个概念时,数据与功能是分离的,如下 def exc1(host,port,db,charset): conn=connect(host,port,db,charset) conn.execute(sql) return xxx def exc2(host,port,db,charset,proc_name) conn=connect(host,port,db,charset) conn.call_proc(sql) return xxx # 每次调用都需要重复传入一堆参数 exc1(‘127.0.0.1‘,3306,‘db1‘,‘utf8‘,‘select * from tb1;‘) exc2(‘127.0.0.1‘,3306,‘db1‘,‘utf8‘,‘存储过程的名字‘) class exc: def __int__(self,host,port,db,charset,proc_name): self.host=host self.port=port self.db=db self.charset=charset self.proc_name = proc_name def exc1(self): conn = connect(self.host, self.port, self.db, self.charset) conn.execute(sql) return xxx def exc2(self): conn = connect(self.host, self.port, self.db, self.charset) conn.call_proc(sql) return xxx 6、下面这段代码的输出结果将是什么?请解释。 class Parent(object): x = 1 class Child1(Parent): pass class Child2(Parent): pass print(Parent.x, Child1.x, Child2.x) # 1 1 1 Child1.x = 2 print(Parent.x, Child1.x, Child2.x) # 1 2 1 Parent.x = 3 print(Parent.x, Child1.x, Child2.x) # 3 2 3 7、多重继承的执行顺序,请解答以下输出结果是什么?并解释。 class A(object): def __init__(self): print(‘A‘) super(A, self).__init__() class B(object): def __init__(self): print(‘B‘) super(B, self).__init__() class C(A): def __init__(self): print(‘C‘) super(C, self).__init__() class D(A): def __init__(self): print(‘D‘) super(D, self).__init__() class E(B, C): def __init__(self): print(‘E‘) super(E, self).__init__() class F(C, B, D): def __init__(self): print(‘F‘) super(F, self).__init__() class G(D, B): def __init__(self): print(‘G‘) super(G, self).__init__() if __name__ == ‘__main__‘: g = G() # G D A B f = F() # F C B D A 8、什么是新式类,什么是经典类,二者有什么区别?什么是深度优先,什么是广度优先? 新式类:继承自object,其子类也是新式类 经典类:没有继承自object的所有类,其子类也是经典类 区别: 非菱形继承时,是一样的。但是当菱形继承时,新式类会采用广度优先,经典类深度优先 深度优先:按照从左往右的顺序,每一条分支走到底,再转入下一条分支 广度优先:按照从左往右的顺序,忽略菱形最顶上的父类,将除该父类之外的所有类进行深度优先遍历,最后再查找该父类 9、用面向对象的形式编写一个老师类, 老师有特征:编号、姓名、性别、年龄、等级、工资,老师类中有功能 1、生成老师唯一编号的功能,可以用hashlib对当前时间加上老师的所有信息进行校验得到一个hash值来作为老师的编号 def create_id(self): pass 2、获取老师所有信息 def tell_info(self): pass 3、将老师对象序列化保存到文件里,文件名即老师的编号,提示功能如下 def save(self): with open(‘老师的编号‘,‘wb‘) as f: pickle.dump(self,f) 4、从文件夹中取出存储老师对象的文件,然后反序列化出老师对象,提示功能如下 def get_obj_by_id(self,id): return pickle.load(open(id,‘rb‘)) 答案: import hashlib import datetime import pickle class Teacher: def create_id(self): m=hashlib.md5() m.update(self.name.encode(‘gbk‘)) m.update(self.sex.encode(‘gbk‘)) m.update(bytes(self.age)) m.update(bytes(self.level)) m.update(bytes(self.salary)) m.update(str(datetime.datetime.now()).encode(‘gbk‘)) return m.hexdigest() def __init__(self,name,sex,age,level,salary): self.name=name self.age=age self.sex=sex self.level=level self.salary=salary self.id=self.create_id() def tell_info(self): print(self.__dict__) def save(self): with open(r‘%s.json‘%self.id, ‘wb‘) as f: pickle.dump(self, f) def get_obj_by_id(self): with open(r‘%s.json‘ % self.id, ‘rb‘) as f: info= pickle.load(f).__dict__ return info t=Teacher(‘egon‘,‘male‘,18,9,1.3) print(t.__dict__) t.save() print(t.get_obj_by_id()) 10、按照定义老师的方式,再定义一个学生类 import hashlib import datetime import pickle class Student: def create_id(self): m=hashlib.md5() m.update(self.name.encode(‘gbk‘)) m.update(self.sex.encode(‘gbk‘)) m.update(bytes(self.age)) m.update(str(datetime.datetime.now()).encode(‘gbk‘)) return m.hexdigest() def __init__(self,name,sex,age): self.name=name self.age=age self.sex=sex self.id=self.create_id() def tell_info(self): print(self.__dict__) def save(self): with open(r‘%s.json‘%self.id, ‘wb‘) as f: pickle.dump(self, f) def get_obj_by_id(self): with open(r‘%s.json‘ % self.id, ‘rb‘) as f: info= pickle.load(f).__dict__ return info s=Student(‘egon‘,‘male‘,18) print(s.__dict__) s.save() print(s.get_obj_by_id()) 11、抽象老师类与学生类得到父类,用继承的方式减少代码冗余 import hashlib import datetime import pickle class ParentClass: def create_id(self): m=hashlib.md5() m.update(self.name.encode(‘gbk‘)) m.update(self.sex.encode(‘gbk‘)) m.update(bytes(self.age)) m.update(str(datetime.datetime.now()).encode(‘gbk‘)) return m.hexdigest() def __init__(self,name,sex,age): self.name=name self.age=age self.sex=sex self.id=self.create_id() def tell_info(self): print(self.__dict__) def save(self): with open(r‘%s.json‘%self.id, ‘wb‘) as f: pickle.dump(self, f) def get_obj_by_id(self): with open(r‘%s.json‘ % self.id, ‘rb‘) as f: info= pickle.load(f).__dict__ return info class Teacher(ParentClass): def create_id(self): m = hashlib.md5() m.update(self.name.encode(‘gbk‘)) m.update(self.sex.encode(‘gbk‘)) m.update(bytes(self.age)) m.update(bytes(self.level)) m.update(bytes(self.salary)) m.update(str(datetime.datetime.now()).encode(‘gbk‘)) return m.hexdigest() def __init__(self, name, sex, age, level, salary): self.level = level self.salary = salary super().__init__(name, sex, age) self.id = self.create_id() class Student(ParentClass): def learn(self): print(‘learning...‘) 12、基于面向对象设计一个对战游戏并使用继承优化代码,参考博客 http://www.cnblogs.com/linhaifeng/articles/7340497.html#_label1
标签:list article hashlib 类的属性 区分 www. width size now()
原文地址:https://www.cnblogs.com/95lyj/p/8809514.html